标签:清空 top rop abi 网络层 icm 文件的 dash 自动
发现应用记录日志内,出现网络访问延迟较大的情况。
此类问题较为常见,特别是之前参与辅助一个朋友项目运维的过程中,经常因为网络访问延迟较大,朋友认为是遭到了ddos攻击或者是cc攻击。网络访问延迟较大常常会给顶层业务带来损失,甚至严重影响用户体验。
遇到这类问题,首先根据OSI七层模型,从上到下,尽可能脱离更加高层的协议带来的影响。一般说来,稍微有经验的人都会采用ping的方式,通过探寻icmp是否工作正常,来直接从网络层面进行定位。
通过测试电脑ping业务服务器,发现如下诡异的回包情况:
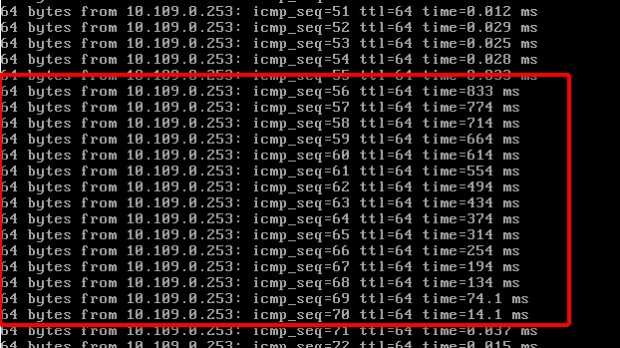
可以看到,这张图片内展示的上下部分,延迟极低,属于正常。但是中间部分出现了延迟极高的现象。不但如此,红框内的延迟变化情况,呈现诡异的逐步降低态势。
如果是业务长期故障,延迟应该是高、数值稳定的。如果是偶发现象,延迟应该是突然增大,前后无变化趋势的。这种有规律的从833ms逐步降低到10ms上下,让人不禁思考,这个里面是不是隐藏着更大的秘密?
假设,在出现故障的时候,服务器的表现是一直再等待处理,故障过去,服务器突然统一按照顺序开始处理,那么造成的结果就是——先发包的回包延迟极大,后续发包延迟逐渐降低。是不是十分吻合上述的情况?
如果这个假设成立,那么事情就变得更加有趣了起来~
我们先要明白,当网卡捕获到icmp包的时候,需要向CPU提起中断申请,CPU发生中断,才能处理回包请求。那么,如果CPU在一段时间内,由于特殊原因,拒绝中断,那么不就会造成上文所说的那种假设情况吗?
事情逐渐明朗了起来。但是即便这种拒绝中断的情况发生了,那么如何才能找到这个拒绝中断的原因呢?还真没有这么简单。不简单的原因很简单,硬件中断本身优先级要高于一般进程和软中断,在其被禁用之后自然普通软件层面的追踪方法也不起作用了。
所以目前尚无很好的方法在不影响业务的情况下较轻量级地获得禁用中断时的内核堆栈。
走到这个地步的时候,那么我们就需要从外露出来的其他指标看看,还有没有什么解决问题的突破口~
果然系统的内存占用较高,但是并没有发现明显的异常程序占用,就感觉凭空少了一块。
这时候我们可以考虑一下slab的问题。
cat /proc/meminfo |grep -i slab
通过这个命令,我们可以了解总共的slab占用。如果发现显示出来的数据确实很大,那么我们有必要调用slabtop进一步查看slab相关的占用高的内容。

我们可以看到这个dentry占用极高。dentry是内存中表示目录与文件的对象,用于链接inode。肯定是出现了什么大量打开文件或目录的情况。
那么,又回到一开始的问题,我们发现了ping的问题,感觉可能和系统禁用中断有关,现在又发现内存占用高,找到了dentry大量占用资源的事实。这二者之间有必然联系吗?
答案是有的。
托大神指导,我们看到了2.6内核的源码。下面这张图片内展示的源码,实现了一个计算slab总量的功能。
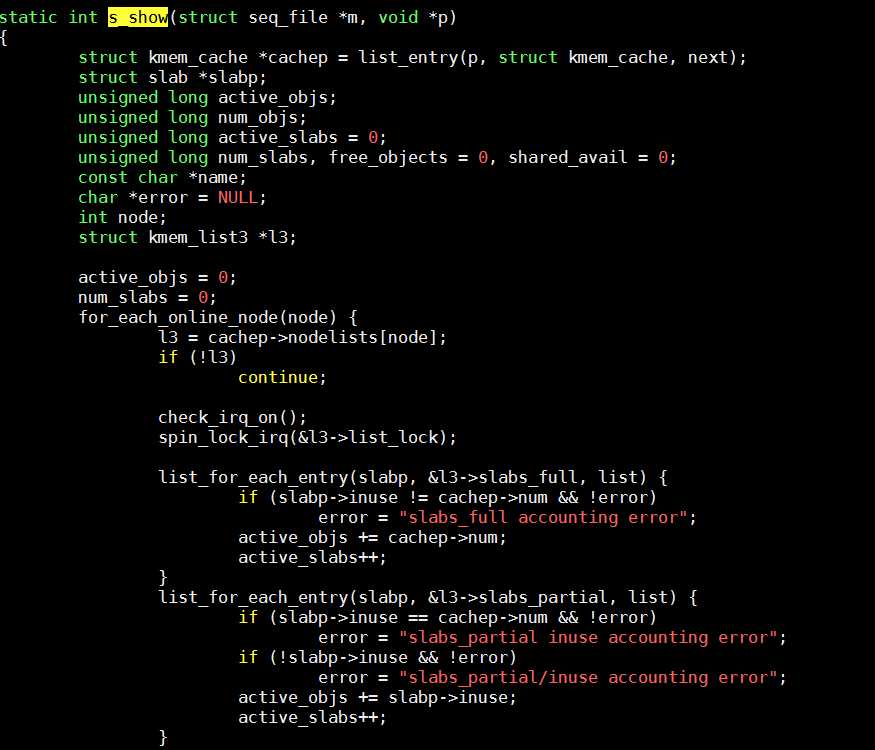
我们可以看到内核是通过遍历链表的方式,进行统计计数。而在进入链表之前,调用了spin_lock_irq函数。我们再继续跟进,看看这个函数的相关实现。

至此,真相大白。我们可以确认在统计slab信息的时候,系统的行为是首先禁用中断,然后遍历链表统计slab,最后再次启用中断。那么整个禁用中断的时间将取决于链表中对象的个数,如果其对象数量惊人,很可能就会导致禁用中断时间过长。
当然,验证这个关联是否存在,也是可以简单实现的。首先,我们在测试机上长ping业务服务器。然后,在业务服务器上执行以下代码:
cat /proc/slabinfo
系统获取slabinfo同样会调用s_show函数,从而触发禁止中断。最终,当然发现再次出现了本文开头一样的幽灵ping延迟变化。至此,表面原因基本已经找到。
从缓解问题的角度来考虑,此时由于dentry项本身是作为系统缓存而存在,所以利用以下指令释放缓存,dentry项会被清空,且不影响硬盘上的实际文件。
echo 2 > /proc/sys/vm/drop_caches && sync
至此,问题已经从表面上缓解。
但是,深层次的来说,还要继续探究为什么会出现这么多的异常文件和目录打开?这一块需要继续从业务层面进行排查。
不过从降低网络延迟的角度考虑,在目前情境下,设定当slab中dentry比例再次达到某一水平的时候,进行释放缓存,可以长久自动化维持正常水平,不影响排查工作的进行。
标签:清空 top rop abi 网络层 icm 文件的 dash 自动
原文地址:https://www.cnblogs.com/Leo_wl/p/11106200.html