标签:运行 cpu 虚引用 溢出 garbage 多线程 空间 current 布局
众所周知,Java语言的一个重要特性就是自动内存管理与垃圾回收机制。垃圾收集也被称作GC(Garbage Collection),在讲到GC的时候,我根据《深入理解Java虚拟机》中提到的内容,打算从三个方面讲述:
首先从理论上讲述这三个问题,然后再以HotSpot为例讲述这三点的具体实现。
前面对于JVM的内存划分中讲到,JVM将其管理的内存分为程序计数器、虚拟机栈、本地方法栈、堆以及方法区。
因此我们说,需要考虑GC问题的内存区域有方法区和堆内存。
在堆中有很多个对象,哪些对象是需要被回收的呢?用大白话说,哪些对象是死亡的呢?这个就涉及到对象的存活判定问题,书中提到的判定方法有两种:
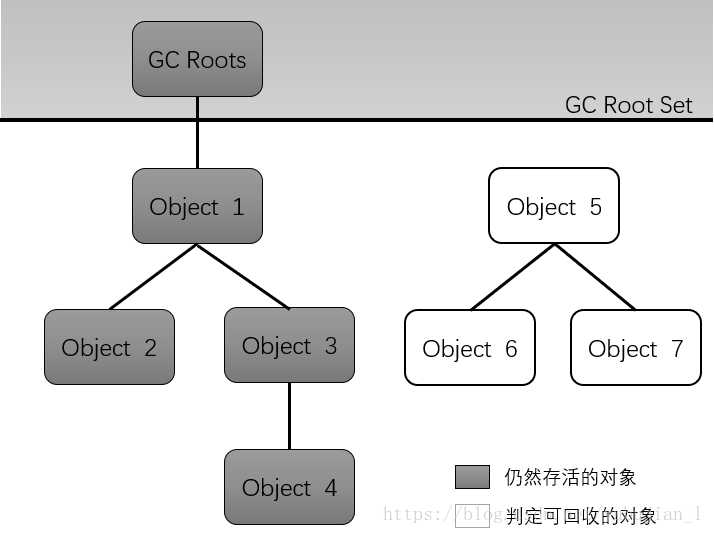
上述的两种判定方法可以用来判定对象的存活与否,基本的判定方法根据对象引用判定对象存活或者死亡,只有两种状态。在Java2之后,引用的概念从两种扩充到四种:
另外,对象在被GC回收的时候,JVM会检查是否重写finalize方法,如果重载了则会执行一次,所以对象可以在这个方法中为自己恢复引用从而逃脱。但是每个对象的finalize方法只会被执行一次,下一次GC就不会执行了。
堆内存中已经死亡的对象是可回收的,对象存活的判断方法有引用计数法和可达性分析法;
Java2之后对引用的类型进行了扩展,引用强度:强引用>软引用>弱引用>虚引用;
方法区中被回收的内容主要是:废弃的常量和无用的类:
GC的时机很重要,从理论上来讲GC执行的时机是不确定的,就算我们显式的调用System.gc()或者Runtime.getRuntime().gc(),也只是通知JVM希望进行一次垃圾回收,但是具体的JVM执行垃圾回收行为的时机是不可预测的,自动的。这里的不可预测是指我们并不知道什么时候会触发,但是我们可以了解它的条件,我将GC的条件分为了触发条件和执行条件。
就是指当JVM达到某种状态的时候会触发一次GC,但是具体的执行还要满足执行条件。在具体的虚拟机实现中各不相同,例如在HotSpot中触发条件主要有
并不是GC一触发就立刻执行的,而是程序运行到安全点或者线程执行到安全区域的时候才能够执行GC。GC在执行的时候需要标记处哪些对象是要回收的,这个过程通过可达性分析算法来完成,此时所有线程都必须停下来,否则会因为引用的动态改变影响可达性分析结果。这里线程停下来的点我们称作安全点,另外线程也可能在GC的时候发生阻塞从而无法到达安全点,这个时候就需要线程进入一个安全区域。
垃圾回收的执行行为是不可预测的,它可以显式的由用户触发,也可以隐式的触发。触发GC之后还需程序满足执行条件才能开始GC。具体的触发条件和执行条件因不同的虚拟机实现而不同。
知道了什么内存需要回收,什么时候回收,GC是如何回收内存的呢?这里提到的就是垃圾收集算法,不同的虚拟机对垃圾收集算法的实现不尽相同。比较经典的三种算法的思想有“标记-清除算法”,“复制算法”,“标记-整理算法”。
本节介绍算法的图片来自于博客https://www.jianshu.com/p/5d612f36eb0b
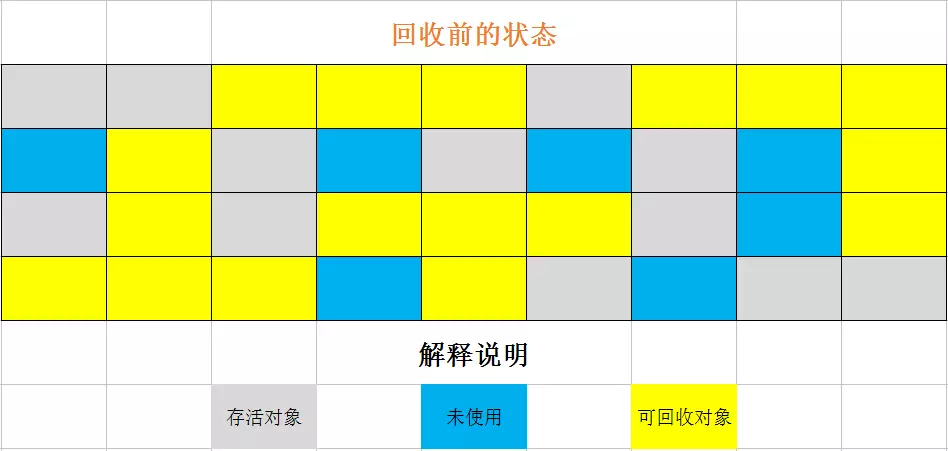
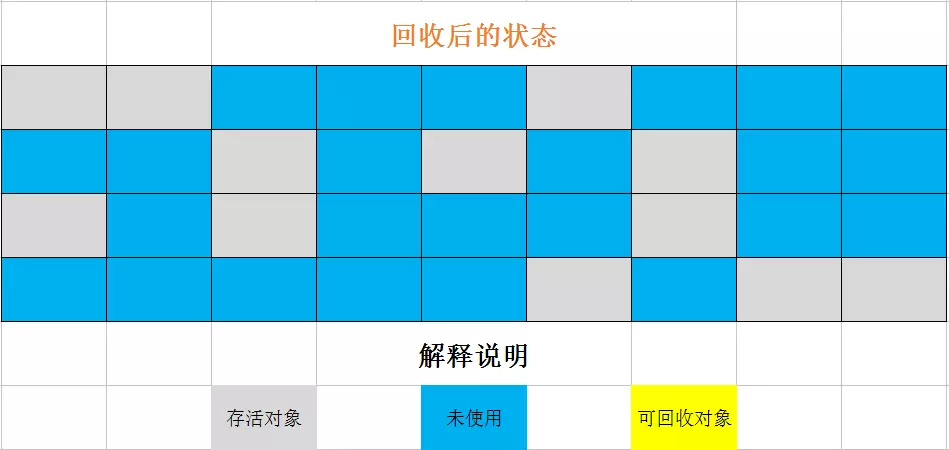
缺点:
复制算法的思想是将内存划分为两块,每次使用其中的一块,GC时将使用的那一块中存活的对象复制到另一块中,然后将之前使用的内存全部抹去。HotSpot中新生代里就将内存划分为Eden空间和两块小的Survivor空间,每次只使用Eden和from Survivor,GC时将对象全部复制到to Survivor中。
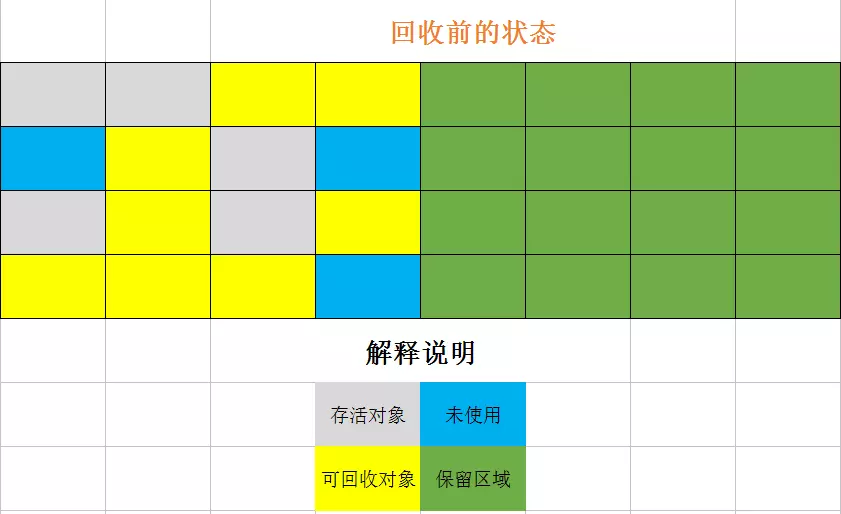
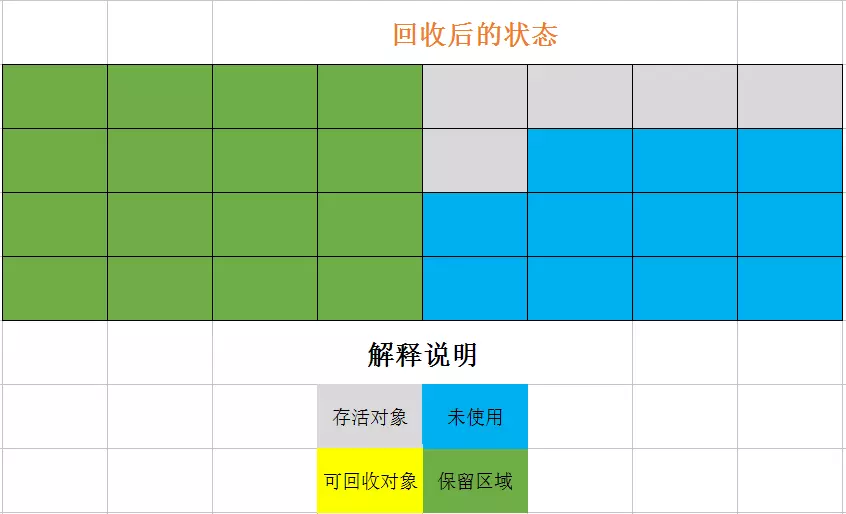
优点是分配内存实现简单高效,缺点是内存使用率不高。
标记整理算法类似与标记清除:
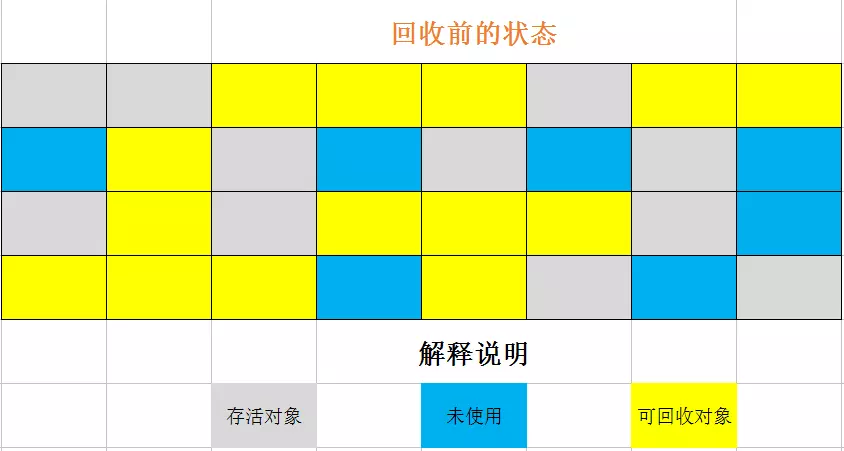
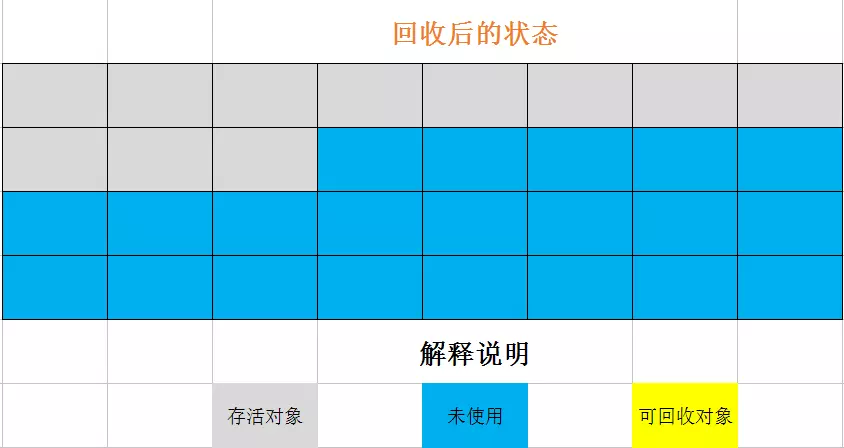
这样的好处是既使用了整块内存,又不会产生内存碎片。但是由于需要进行整理操作,适用于对象存活度高的老年代空间。
前面介绍了具体的内存回收过程都是基于理论上的设计。在HotSpot中针对上述理论有具体的实现。
在HotSpot中采用可达性分析来判定对象的存活状况,可达性分析发生在GC的过程中,前述的四种引用划分以及finalize方法在HotSpot中都有实现。
HotSpot中对于可达性分析的实现是枚举根节点,枚举根节点的时候需要停顿所有Java执行线程,然后使用OopMap的数据结构来实现准确式内存,完成GC Roots的枚举。
HotSpot中通过分代收集算法来进行垃圾收集,将内存划分为新生代和老年代,根据不同的年代特点选择合适的收集算法。在新生代中对象死亡较多,选择复制算法;在老年代中对象存活较多,选择“标记-清除”或者“标记-整理”算法。对于不同年代下的垃圾收集,HotSpot具体实现了不同的垃圾收集器。
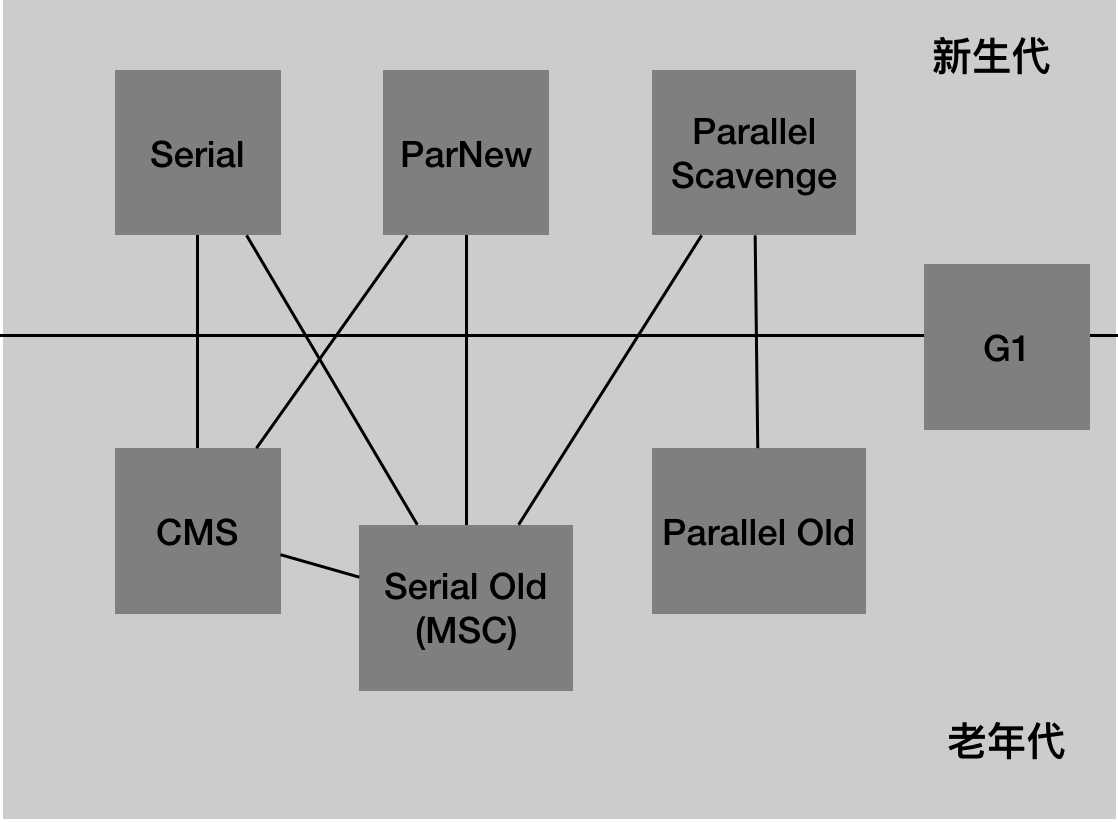
在新生代中实现了Serial、ParNew、Parallel Scavenge收集器,老年代中对应实现了Serial Old、Parallel Old收集器以及CMS收集器,另外还实现了同时处理新生代和老年代的G1收集器。
Serial收集器是用于新生代的单线程垃圾收集器。每次需要垃圾收集时,用户所有线程会全部暂停,然后一个单线程GC开始采取复制算法进行垃圾收集。
ParNew收集器是用于新生代的多线程垃圾收集器,除了多条线程收集垃圾,其他的部分与Serial一样。同样的,ParNew收集器也是采用复制算法进行垃圾收集。
Parllel Scavenge是用于新生代的并行的多线程垃圾收集器,同样采取复制算法进行垃圾收集。它的特点是实现一个可以控制的吞吐量。吞吐量=用户线程时间/CPU消耗总时间;
垃圾收集器关注两个指标,一个是停顿时间,停顿时间越短用户体验越好,适用于用户交互程序;另一个指标是吞吐量,吞吐量越高,用户程序的运算效率越高,适用于后台运算等少交互的程序。Parallel Scavenge收集器通过参数-XX:MaxGCPauseMills来设置GC停顿最大时间,通过参数-XX:GCTimeRatio来控制吞吐量大小。
Serial Old是用于老年代的单线程垃圾收集器。与Serial一样,采用标记-整理算法进行垃圾收集,每次垃圾收集时都会暂停用户所有线程。
Parallel Old收集器是Parallel Scavenge的老年代版本,也是多线程的垃圾收集器,采用标记-整理算法进行垃圾收集。在新生代和老年代可以配合使用Parallel垃圾收集器,实现吞吐量的优先考虑。
CMS收集器全称(Concurrent Mark Sweep),它用于老年代,是一种追求最短回收停顿时间为目标的收集器,采用标记-清除算法进行垃圾收集。
垃圾收集过程中停顿用户线程的根源是GC根枚举过程,也就是标记过程。为了缩短回收垃圾时的停顿时间,CMS收集器将标记过程拆分成3部分:初始标记、并发标记以及重新标记。
由此可见,通过将主要的溯源标记过程设计为与用户线程并发进行,从而缩短用户线程停顿的时间。完成标记之后进入并发清理阶段,清理阶段也是与用户线程并行的。
不过这样设计也有一些缺点:
针对缺点可以设置调优的参数:
CMS收集器是一个专注于优化停顿时间的老年代垃圾收集器,虽然在设计过程中会存在一些缺点,但是针对这些缺点JVM的设计者也在不停的进行补救,用户可以合理使用参数设置,根据实际应用情况来设置最优的CMS收集器。
G1收集器全称是Garbage-First,在HotSpot中称作将来会替换掉CMS收集器。G1收集器对堆内存的布局是采用区域的概念,将堆划分为多个大小相等的独立区域,从而可以实现收集器收集范围为整个堆内存。与CMS的目标类似,它也是以降低用户线程停顿时间为目标,运作分为以下几步:
G1收集器是比较现金的收集器技术,它的主要特点是:
除了内存回收GC,HotSpot对对象的内存分配同样重要,不同的收集器组合对内存的布局和分配规则不同。
对于Serial+Serial Old收集器组合,堆内存的布局就是经典的新生代+老年代,新生代中分为Eden区和两块Survivor区。新建对象优先分配在Eden区,如果Eden区空间不够分配则发起一次Minor GC,Minor GC是指发生在新生代的垃圾回收,主要过程是将Eden空间和from Survivor空间内存活的对象复制到to Survivor中,然后将两个Survivor名称互换,一旦to Survivor空间不够用,则使用担保机制直接将对象复制到老年代区中。
对于空间分配担保,前面也已经讲述过了。Minor GC的时候如果Survivor空间无法容纳存活的对象,则进行一次担保并将无法容纳的对象直接移动到老年代。
JVM的垃圾收集与内存分配是互相对应的同样重要的,内存分配时负责给对象分配内存空间,垃圾收集时负责对无用对象的内存进行回收。我们需要关注的重点有:
标签:运行 cpu 虚引用 溢出 garbage 多线程 空间 current 布局
原文地址:https://www.cnblogs.com/zhengshuangxi/p/11087515.html