标签:contex random direct context images too can table pen
As we all know that Kafka is very fast, much faster than most of its competitors. So what’s the reason here?
Avoid Random Disk Access
Kafka writes everything onto the disk in order and consumers fetch data in order too. So disk access always works sequentially instead of randomly. For traditional hard disks(HDD), sequential access is much faster than random access. Here is a comparison:
| hardware | sequential writes | random writes |
|---|---|---|
| 6 * 7200rpm SATA RAID-5 | 300MB/s | 50KB/s |
Kafka Writes Everything Onto The Disk Instead of Memory
Yes, you read that right. Kafka writes everything onto the disk instead of memory. But wait a moment, isn’t memory supposed to be faster than disks? Typically it’s the case, for Random Disk Access. But for sequential access, the difference is much smaller. Here is a comparison taken from https://queue.acm.org/detail.cfm?id=1563874.

As you can see, it’s not that different. But still, sequential memory access is faster than Sequential Disk Access, why not choose memory? Because Kafka runs on top of JVM, which gives us two disadvantages.
1.The memory overhead of objects is very high, often doubling the size of the data stored(or even higher).
2.Garbage Collection happens every now and then, so creating objects in memory is very expensive as in-heap data increases because we will need more time to collect unused data(which is garbage).
So writing to file systems may be better than writing to memory. Even better, we can utilize MMAP(memory mapped files) to make it faster.
Memory Mapped Files(MMAP)
Basically, MMAP(Memory Mapped Files) can map the file contents from the disk into memory. And when we write something into the mapped memory, the OS will flush the change onto the disk sometime later. So everything is faster because we are using memory actually, but in an indirect way. So here comes the question. Why would we use MMAP to write data onto disks, which later will be mapped into memory? It seems to be a roundabout route. Why not just write data into memory directly? As we have learned previously, Kafka runs on top of JVM, if we wrote data into memory directly, the memory overhead would be high and GC would happen frequently. So we use MMAP here to avoid the issue.
Zero Copy
Suppose that we are fetching data from the memory and sending them to the Internet. What is happening in the process is usually twofold.
1.To fetch data from the memory, we need to copy those data from the Kernel Context into the Application Context.
2.To send those data to the Internet, we need to copy the data from the Application Context into the Kernel Context.
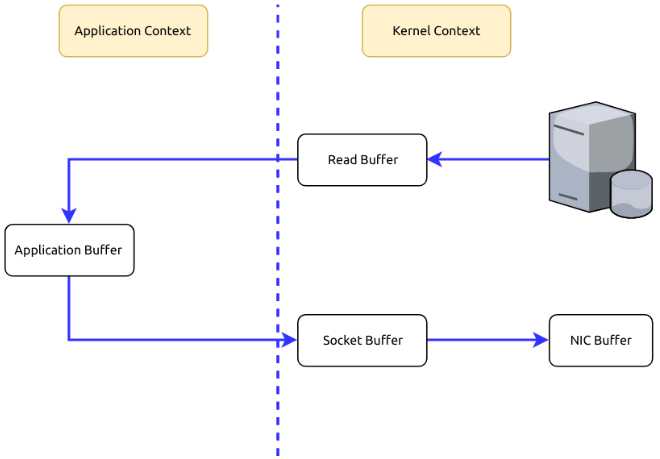
As you can see, it’s redundant to copy data between the Kernel Context and the Application Context. Can we avoid it? Yes, using Zero Copy we can copy data directly from the Kernel Context to the Kernel Context.
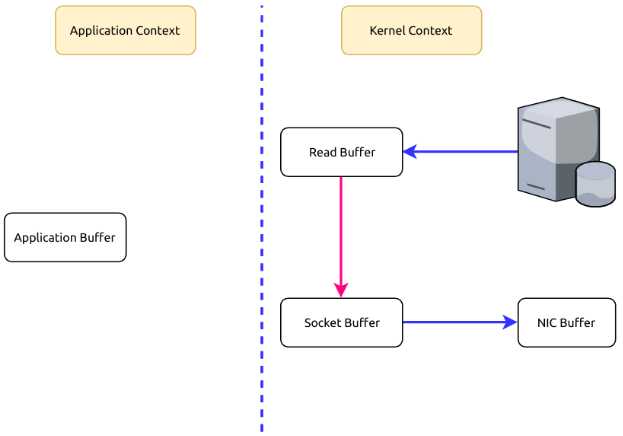
Batch Data
Kafka only sends data when batch.size is reached instead of one by one. Assuming the bandwidth is 10MB/s, sending 10MB data in one go is much faster than sending 10000 messages one by one(assuming each message takes 100 bytes).
"I would be fine and made no troubles."
标签:contex random direct context images too can table pen
原文地址:https://www.cnblogs.com/yanggb/p/11063957.html