标签:小白 完成 曲线 优点 不同的 分数 读者 过程 算法
1.简介
TensorFlow可以很容易地利用单个GPU加速深度学习模型的训练过程,但要利用更多的GPU或者机器,需要了解如何并行化训练深度学习模型。常用的并行化深度学习模型训练方式有两种,同步模式和异步模式。
2.两种模式的区别
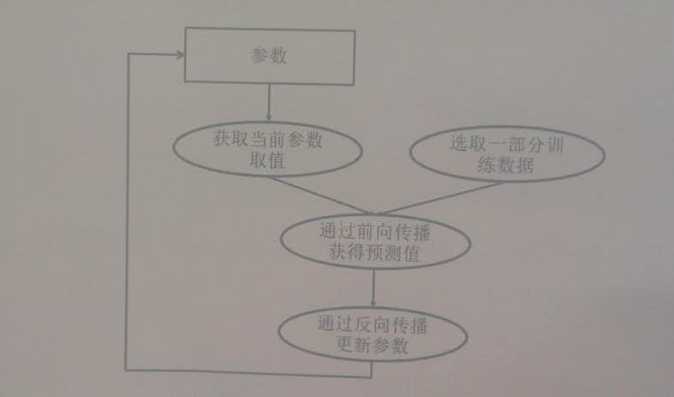
为帮助读者理解这两种训练模式,首先简单回顾一下如何训练深度学习模型。下图展示了深度学习模型的训练流程图。深度学习模型的训练是一个迭代的过程。在每一轮迭代中,前向传播算法会根据当前参数的取值计算出在一小部分训练数据上的预测值,然后反向传播算法再根据损失函数计算参数的梯度并更新参数。在并行化地训练深度学习模型时,不同设备(GPU或CPU)可以在不同训练数据上运行这个迭代的过程,而不同并行模式的区别在于不同的参数更新方式。
2.1 异步模式
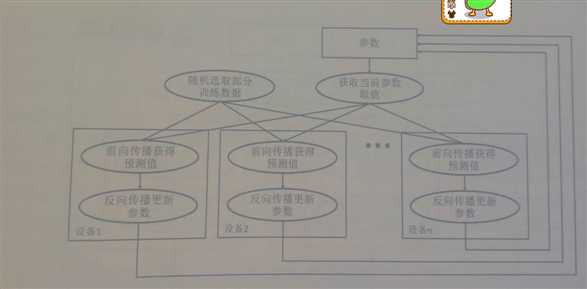
下图展示了异步模式的训练流程图。可以看到,在每一轮迭代时,不同设备会读取参数最新的取值,但因为不同设备读取参数取值的时间不一样,所以得到的值也有可能不一样。根据当前参数的取值和随机获取的一小部分训练数据,不同设备各自运行反向传播的过程并独立地更新参数。可以简单地认为异步模式就是单机模式复制了多份,每一份使用不同的训练数据进行训练。在异步模式下,不同设备之间是完全独立的。
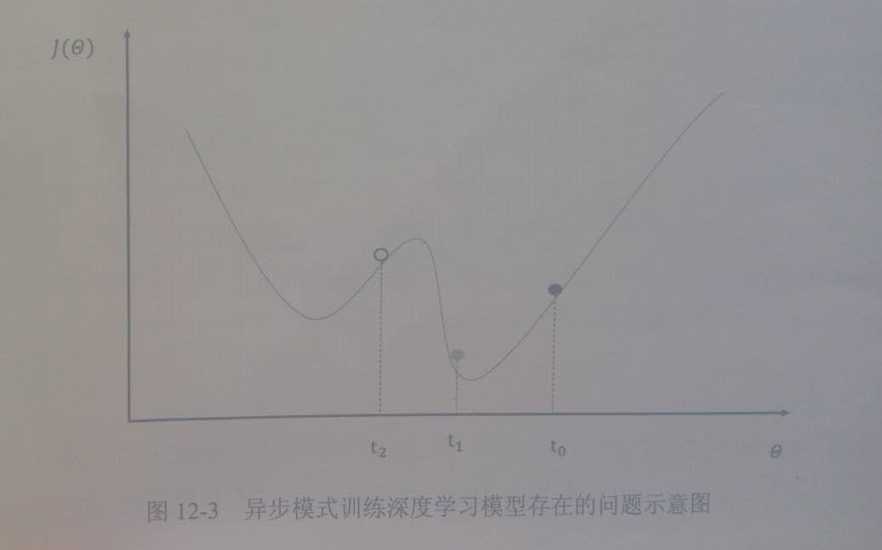
然而使用异步模式训练的深度学习模型有可能无法达到较优的训练效果。下图中给出了一个具体的样例来说明异步模式的问题。其中黑色曲线展示了模型的损失函数,黑色小球表示了在to时刻参数所对应的损失函数的大小。假设两个设备do和d1在时间to同时读取了参数的取值,那么设备do和d1计算出来的梯度都会将小黑球向左移动。假设在时间t1设备do已经完成了反向传播的计算并更新了参数,修改后的参数处于图中小灰球的位置。然而这时的设备d1并不知道参数已经被更新了,所以在时间t2时,设备d1会继续将小球向左移动,使得小球的位置达到图中小白球的地方。从图中可以看到,当参数被调整到小白球的位置时,将无法达到最优点。
2.2 同步模式
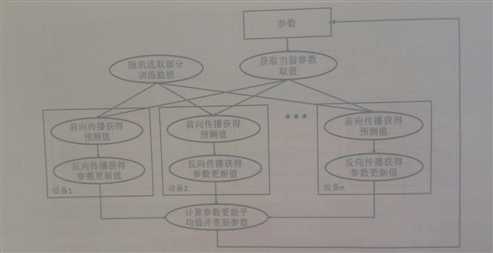
为了避免更新不同步的问题,可以使用同步模式。在同步模式下,所有的设备同时读取参数的取值,并且当反向传播算法完成之后同步更新参数的取值。单个设备不会单独对参数进行更新。而会等待所有设备都完成反向传播之后再统一更新参数。下图展示了同步模式的训练过程。可以看出,在每一轮迭代时,不同设备首先统一读取当前参数的取值,并随机获取一部分数据。然后在不同设备上运行反向传播过程得到在各自训练数据上参数的梯度。注意虽然所有设备使用的参数是一致的,但是因为训练数据不同,所以得到参数的梯度就有可能不同。当所有设备完成反向传播的计算之后,需要计算出不同设备上参数梯度的平均值,最后再根据平均值对参数进行更新。
同步模式解决了异步模式中存在的参数更新问题,然而同步模式的效率却低于异步模式。在同步模式下,每一轮迭代都需要设备统一开始、统一结束。如果设备的运行速度不一致,那么每一轮训练都需要等待最慢的设备结束才能开始更新参数,于是很多时间将被花在等待上。虽然理论上异步模式存在缺陷,但因为训练深度学习模型时使用的随机梯度下降本身就是梯度下降的一个近似解法,而且即使是梯度下降也无法保证达到全局最优值,所以在实际应用中,在相同时间内,使用异步模式训练的模型不一定比同步模式差。所以这两种训练模式在实践中都有非常广泛的应用。
标签:小白 完成 曲线 优点 不同的 分数 读者 过程 算法
原文地址:https://www.cnblogs.com/bestExpert/p/10787438.html