标签:sum local cal 过程 ISE getbean map ini ssi
本篇文章接着上篇内容继续,地址:IDC集群相关指标获取
在获取了对应的IDC机器自身的指标之后,还需要对Hadoop集群中HDFS和YARN的指标进行采集,大体思路上可以有2种:
第一种当然还是可以延用CM API去获取,因为CM中的tssql提供了非常丰富的各种指标监控
第二种即通过jmxJ去获取数据,其实就是通过访问上述这些相关的URL,然后将得到的json进行解析,从而获取到我们需要的数据,最终将这些数据归并到一起,定时的去执行采集操作
在实际的实践过程当中使用jmx这种方式去进行获取,涉及到的url请求如下:
http://localhost:50070/jmx?qry=Hadoop:service=NameNode,name=NameNodeInfo
http://localhost:50070/jmx?qry=Hadoop:service=NameNode,name=FSNamesystemState
具体的代码实现思路如下:
首先需要有个httpclient,去向server发起请求,从而获得对应的json数据,这里自己编写了StatefulHttpClient
其次使用JsonUtil该工具类,用于Json类型的数据与对象之间的转换
当然,我们也需要将所需要获取的监控指标给梳理出来,编写我们的entity,这里以HDFS为例,主要为HdfsSummary和DataNodeInfo
本案例的代码在github上,地址:
这里主要展示核心的代码:
MonitorMetrics.java:
public class MonitorMetrics {
// beans为通过jmx所返回的json串中最起始的key
// 结构为{"beans":[{"":"","":"",...}]}
List<Map<String, Object>> beans = new ArrayList<>();
public List<Map<String, Object>> getBeans() {
return beans;
}
public void setBeans(List<Map<String, Object>> beans) {
this.beans = beans;
}
public Object getMetricsValue(String name) {
if (beans.isEmpty()) {
return null;
}
return beans.get(0).getOrDefault(name, null);
}
}HadoopUtil.java:
public class HadoopUtil {
public static long gbLength = 1073741824L;
public static final String hadoopJmxServerUrl = "http://localhost:50070";
public static final String jmxServerUrlFormat = "%s/jmx?qry=%s";
public static final String nameNodeInfo = "Hadoop:service=NameNode,name=NameNodeInfo";
public static final String fsNameSystemState = "Hadoop:service=NameNode,name=FSNamesystemState";
public static HdfsSummary getHdfsSummary(StatefulHttpClient client) throws IOException {
HdfsSummary hdfsSummary = new HdfsSummary();
String namenodeUrl = String.format(jmxServerUrlFormat, hadoopJmxServerUrl, nameNodeInfo);
MonitorMetrics monitorMetrics = client.get(MonitorMetrics.class, namenodeUrl, null, null);
hdfsSummary.setTotal(doubleFormat(monitorMetrics.getMetricsValue("Total"), gbLength));
hdfsSummary.setDfsFree(doubleFormat(monitorMetrics.getMetricsValue("Free"), gbLength));
hdfsSummary.setDfsUsed(doubleFormat(monitorMetrics.getMetricsValue("Used"), gbLength));
hdfsSummary.setPercentUsed(doubleFormat(monitorMetrics.getMetricsValue("PercentUsed")));
hdfsSummary.setSafeMode(monitorMetrics.getMetricsValue("Safemode").toString());
hdfsSummary.setNonDfsUsed(doubleFormat(monitorMetrics.getMetricsValue("NonDfsUsedSpace"), gbLength));
hdfsSummary.setBlockPoolUsedSpace(doubleFormat(monitorMetrics.getMetricsValue("BlockPoolUsedSpace"), gbLength));
hdfsSummary.setPercentBlockPoolUsed(doubleFormat(monitorMetrics.getMetricsValue("PercentBlockPoolUsed")));
hdfsSummary.setPercentRemaining(doubleFormat(monitorMetrics.getMetricsValue("PercentRemaining")));
hdfsSummary.setTotalBlocks((int) monitorMetrics.getMetricsValue("TotalBlocks"));
hdfsSummary.setTotalFiles((int) monitorMetrics.getMetricsValue("TotalFiles"));
hdfsSummary.setMissingBlocks((int) monitorMetrics.getMetricsValue("NumberOfMissingBlocks"));
String liveNodesJson = monitorMetrics.getMetricsValue("LiveNodes").toString();
String deadNodesJson = monitorMetrics.getMetricsValue("DeadNodes").toString();
List<DataNodeInfo> liveNodes = dataNodeInfoReader(liveNodesJson);
List<DataNodeInfo> deadNodes = dataNodeInfoReader(deadNodesJson);
hdfsSummary.setLiveDataNodeInfos(liveNodes);
hdfsSummary.setDeadDataNodeInfos(deadNodes);
String fsNameSystemStateUrl = String.format(jmxServerUrlFormat, hadoopJmxServerUrl, fsNameSystemState);
MonitorMetrics hadoopMetrics = client.get(MonitorMetrics.class, fsNameSystemStateUrl, null, null);
hdfsSummary.setNumLiveDataNodes((int) hadoopMetrics.getMetricsValue("NumLiveDataNodes"));
hdfsSummary.setNumDeadDataNodes((int) hadoopMetrics.getMetricsValue("NumDeadDataNodes"));
hdfsSummary.setVolumeFailuresTotal((int) hadoopMetrics.getMetricsValue("VolumeFailuresTotal"));
return hdfsSummary;
}
public static List<DataNodeInfo> dataNodeInfoReader(String jsonData) throws IOException {
List<DataNodeInfo> dataNodeInfos = new ArrayList<DataNodeInfo>();
Map<String, Object> nodes = JsonUtil.fromJsonMap(String.class, Object.class, jsonData);
for (Map.Entry<String, Object> node : nodes.entrySet()) {
Map<String, Object> info = (HashMap<String, Object>) node.getValue();
String nodeName = node.getKey().split(":")[0];
DataNodeInfo dataNodeInfo = new DataNodeInfo();
dataNodeInfo.setNodeName(nodeName);
dataNodeInfo.setNodeAddr(info.get("infoAddr").toString().split(":")[0]);
dataNodeInfo.setLastContact((int) info.get("lastContact"));
dataNodeInfo.setUsedSpace(doubleFormat(info.get("usedSpace"), gbLength));
dataNodeInfo.setAdminState(info.get("adminState").toString());
dataNodeInfo.setNonDfsUsedSpace(doubleFormat(info.get("nonDfsUsedSpace"), gbLength));
dataNodeInfo.setCapacity(doubleFormat(info.get("capacity"), gbLength));
dataNodeInfo.setNumBlocks((int) info.get("numBlocks"));
dataNodeInfo.setRemaining(doubleFormat(info.get("remaining"), gbLength));
dataNodeInfo.setBlockPoolUsed(doubleFormat(info.get("blockPoolUsed"), gbLength));
dataNodeInfo.setBlockPoolUsedPerent(doubleFormat(info.get("blockPoolUsedPercent")));
dataNodeInfos.add(dataNodeInfo);
}
return dataNodeInfos;
}
public static DecimalFormat df = new DecimalFormat("#.##");
public static double doubleFormat(Object num, long unit) {
double result = Double.parseDouble(String.valueOf(num)) / unit;
return Double.parseDouble(df.format(result));
}
public static double doubleFormat(Object num) {
double result = Double.parseDouble(String.valueOf(num));
return Double.parseDouble(df.format(result));
}
public static void main(String[] args) {
String res = String.format(jmxServerUrlFormat, hadoopJmxServerUrl, nameNodeInfo);
System.out.println(res);
}
}MonitorApp.java:
public class MonitorApp {
public static void main(String[] args) throws IOException {
StatefulHttpClient client = new StatefulHttpClient(null);
HadoopUtil.getHdfsSummary(client).printInfo();
}
}最终展示结果如下: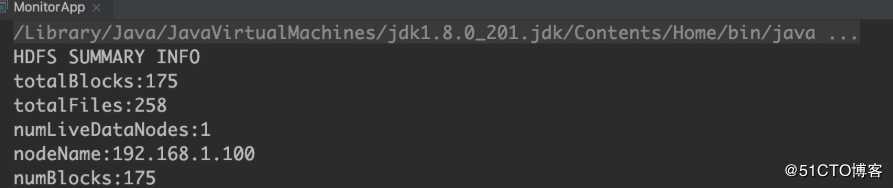
关于YARN指标的获取,思路类似,这里就不再展示了
你懂集群monitoring么?(二)—— HDFS部分指标
标签:sum local cal 过程 ISE getbean map ini ssi
原文地址:https://blog.51cto.com/14309075/2415632