标签:home clu 高可用性 分析 信息 hdfs order 直接 jdk
1.hbase的架构
|
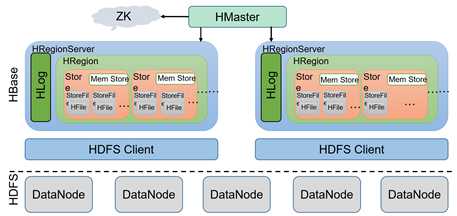
Hbase主要由master,regionserver,zookeeper,client,hdfs文件系统构成.
Zk:记录hbase的表的元数据信息 hamster:进行region的分配,发出操作指令 Hlog:记录HregionServer的操作日志,保证数据的可靠性 HRegion:存储Hbase表的信息 store:Hbase表的不同列族的存储 DataNode:存储Hbase的Hlog及Hbase表的Hfile的文件持久化存储 |
2.hbase的组件及作用
|
1)Client 访问Hbase的接口, Client中具有 cache来加速Hbase的访问,比如cache的.META.元数据的信息。 2)Zookeeper HBase通过Zookeeper来做master的高可用、RegionServer的监控、元数据的入口以及集群配置的维护等工作。 通过Zoopkeeper来保证集群中只有1个master在运行,如果master异常,会通过竞争机制产生新的master提供服务 通过Zoopkeeper来监控RegionServer的状态,当RegionSevrer有异常的时候,通过回调的形式通知Master RegionServer上下线的信息 通过Zoopkeeper存储元数据的统一入口地址 3)Hmaster master节点的主要职责如下: 为RegionServer分配Region 维护整个集群的负载均衡 维护集群的元数据信息 发现失效的Region,并将失效的Region分配到正常的RegionServer上 当RegionSever失效的时候,协调对应Hlog的拆分 4)HregionServer HregionServer直接对接用户的读写请求,是真正的“干活”的节点。它的功能概括如下: 管理master为其分配的Region 处理来自客户端的读写请求 负责和底层HDFS的交互,存储数据到HDFS 负责Region变大以后的拆分 负责Storefile的合并工作 5)HDFS HDFS为Hbase提供最终的底层数据存储服务,同时为HBase提供高可用(Hlog存储在HDFS)的支持,具体功能概括如下: 提供元数据和表数据的底层分布式存储服务 数据多副本,保证的高可靠和高可用性 |
3.hbase的读写流程
|
HBase读数据流程: 1)Client先访问zookeeper,从meta表读取region的位置,然后读取meta表中的数据。meta中又存储了用户表的region信息; 2)根据namespace、表名和rowkey在meta表中找到对应的region信息; 3)找到这个region对应的regionserver; 4)查找对应的region; 5)先从MemStore找数据,如果没有,再到BlockCache里面读; 6)BlockCache还没有,再到StoreFile上读(为了读取的效率); 7)如果是从StoreFile里面读取的数据,不是直接返回给客户端,而是先写入BlockCache,再返回给客户端。 |
|
写入数据流程: 1)Client向HregionServer发送写请求; 2)HregionServer将数据写到HLog(write ahead log)。为了数据的持久化和恢复; 3)HregionServer将数据写到内存(MemStore); 4)反馈Client写成功。
|
4.hbase集群搭建
|
伪分布式 : 1.hbase-env.sh中配置JAVA_HOME 2.配置hbase-site.xml如下 <property> <name>hbase.rootdir</name> <value>file:///root/hbaserootdir</value> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/root/zookeeper/data</value> </property>
|
||||
|
完全分布式搭建: 设置使用自定义的zookeeper: 需要在hbase-env.sh中设置HBASE_MANAGES_ZK为false backup-masters配置:
hbase-env.sh配置:
hbase-site.xml配置:
regionservers配置:
将hdfs-site.xml拷贝到hbase的conf目录 或者使用软链接,将Hadoop的配置文件软连接到hbase的配置目录 bin/start-hbase.sh bin/stop-hbase.sh bin/hbase shell HBase的WEB UI访问: HMaster:http://node1:60010 |
标签:home clu 高可用性 分析 信息 hdfs order 直接 jdk
原文地址:https://www.cnblogs.com/eric666666/p/11118197.html