标签:main cluster def virtual 图片 com bin 创建 又能
说明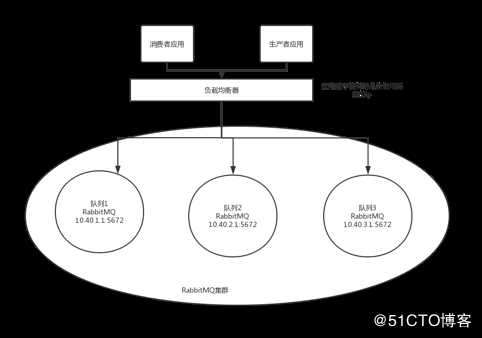
N多生产者和消费者会被负载均衡器以某种算法把请求打到后端rabbit节点上。
连接丢失和故障转移
当集群节点出现故障时,应用程序必须要做出决定:下一个该连向哪里?为了能有效回答这个问题,你必须在事情发生前就有所准备。优雅地处理节点故障需要思维的转变。
集群并不意味着可以完全避免rabbit相关的所有问题,而是意味着当某节点出现故障时保证整个集群是可用的。
所以,首先需要退一步思考一下,在编写代码前可以做怎样的假设:
(1) 如果我重新连接到新的服务器,那么我的信道以及以上的所有消费循环会怎样呢? 答:它们都将失效,所以程序必须对它们进行重建。
(2) 当程序进行重连时,能否假设所有的交换器、队列和绑定仍然存在于集群之中?能否重连之后立即开始从队列消费呢?答案是否定的。不能假设队列和绑定可以从节点故障中恢复。必须假定在消费的所有队列都附加在该节点之上------并且已不复存在。(咱们的RabbitMQ集群都是开启了镜像队列功能的,消息和队列不会丢失,所以这一条可以不用考虑。)
从上面两个例子可以得出结论,当故障集群中某一节点发生故障时,任何人都无法对集群的状态做任何假定。虽然RabbitMQ集群可以让你重连到新节点上,但你不能做任何假设。
从某种角度而言,你应该总是将故障转移视为连接到了一个完全无关的RabbitMQ服务器,而不是有着共享状态的集群节点。因此,不论节点故障什么时候发生,在检测到故障并进行重连之后的首要任务就是构造交换器、队列和绑定,以便应用程序的运作。
重连示例(python)
未添加集群感知的消费者主体
① conn_broker = pika.BlockingConnection(conn_params)
?
② channel = conn_broker.channel()
③ channel.exchange_declare(exchange="cluster_test",
????????????????????????type="direct",
????????????????????????auto_delete=False)
channel.queue_declare(queue="cluster_test",
????????????????????????auto_delete=False)
channel.queue_bind(queue="cluster_test",
????????????????????exchange="cluster_test",
????????????????????routing_key="cluster_test")
?
print("Ready for testing!")
④channel.basic_consume(msg_rcvd,
????????????????????????queue="cluster_test",
????????????????????????no_ack=False,
????????????????????????consumer_tag="cluster_test")
channel.start_consuming()
?
###
在①处,你使用已经构造好的参数来连接服务器。你建立了信道②,并开始声明③交换器、队列和绑定(消息通信结构)。在消息通信结构构造完成之后,你创建了④消费订阅(由msg_rcvd函数提供),并开始消费消息。这时,如果遇到了节点故障,那么程序就会由于未处理的异常而崩溃。这时因为代码不知道在连接发生错误发起重连。但是从哪里开始呢?主要代码块中的哪部分需要在故障后重新运行呢?答案是整个代码都需要。如果你假设消息通信结构的任何部分都无法从节点故障中恢复的话,那么久需要在每次错误发生的时候运行整个代码块。记住这一点,然后重写主代码块,那么就会像下面的代码这样。添加集群感知的消费者主体
while True:
????try:
????????conn_broker = pika.BlockingConnection(conn_params)
?
????????channel = conn_broker.channel()
????????channel.exchange_declare(exchange="cluster_test",
????????????????????????????????type="direct",
????????????????????????????????auto_delete=False)
????????channel.queue_declare(queue="cluster_test",
????????????????????????????????auto_delete=False)
????????channel.queue_bind(queue="cluster_test",
????????????????????????????exchange="cluster_test",
????????????????????????????routing_key="cluster_test")
print("Ready for testing!")
channel.basic_consume(msg_rcvd,
????????????????????????queue="cluster_test",
????????????????????????no_ack=False,
????????????????????????consumer_tag="cluster_test")
channel.start_consuming()
except Exception, e:
????traceback.print_exc()
?
###
通过将主代码块放入try...except块中,你就可以检测连接故障,消费者也不会因此而崩溃。在该示例中,会捕获所有的错误并将它们打印到屏幕上。生产的应用,“except Exception, e”这部分里的代码应该是设置重连的。集群感知的消费者代码
到目前为止,在我们从应用程序的角度讨论集群节点故障时,我们反复说明应用程序连接的是节点。
你也许会做这样的假设:只要应用程序连接的那个节点没有崩溃,那么就没什么好担心的了。这并非完全正确。
如果你记得队列在集群环境下的运作方式的话,就会注意到它们只存在于某一个节点上。由于在开始消费的时候,应用程序并不知道队列在哪个节点上,因此应用程序很有可能连接到了集群中的A节点但却从B节点的队列上消费消息。所以,当B节点发生故障时会发生什么呢?虽然应用程序不会遭受连接错误,但是消费的那个队列却已不复存在,此时消费者会收到通知。在pika中,这种通知的表现为消费代码抛出异常,这会被异常处理代码捕获,然后重连并重建通信结构。
将所有这些结合起来,消费者代码就会如下所示:
import sys, json, pika, traceback
?
def msg_rcvd(channel, method, header, body):
????message = json.loads(body)
????print("Received: %(content)s/%s(timd)d" % message)
????channel.basic_ack(delivery_tag=method.delivery_tag)
?
if __name__ == "__main__":
????AMQP_SERVER = sys.argv[1]
????AMQP_PORT = int(sys.argv[2])
?
????creds_broker = pika.PlainCredentials("guest", "guest")
????conn_params = pika.ConnectionParameters(AMQP_SERVER,
????????????????????????????????????????????port=AMQP_PORT,
????????????????????????????????????????????virtual_host="/",
????????????????????????????????????????????credentials=creds_broker)
?
????while True:
????????try:
????????????conn_broker = pika.BlockingConnection(conn_params)
?
????????????channel = conn_broker.channel()
????????????channel.exchange_declare(exchange="cluster_test",
????????????????????????????????????type="direct",
????????????????????????????????????auto_delete=False)
????????????channel.queue_declare(queue="cluster_test",
????????????????????????????????????auto_delete=False)
????????????channel.queue_bind(queue="cluster_test",
????????????????????????????????exchange="cluster_test",
????????????????????????????????routing_key="cluster_test")
????print("Ready for testing!")
????channel.basic_consume(msg_rcvd,
????????????????????????????queue="cluster_test",
????????????????????????????no_ack=False,
????????????????????????????consumer_tag="cluster_test")
????channel.start_consuming()
????except Exception, e:
????????traceback.print_exc()如上所见,将消费者应用转换为集群感知的并不困难,只需要对在节点发生故障时RabbitMQ内部运作有所了解,并将那些应对措施融入到代码之中。
生产者应用也需要添加对应的集群感知代码。
不使用负载均衡时需要注意的事
有些模块可能不适合使用负载均衡,适合把所有的rabbit节点的ip配置上,它自己就实现断线重连了。
如果是这种情况,一定得注意这个连接rabbit的模块是实现了负载均衡策略的,比如配置为”[‘1.1.1.1‘,‘2.2.2.2‘,‘3.3.3.3‘]“,那模块第一次连接1.1.1.1,第二次连接2.2.2.2,第三次连接3.3.3.3,不能总摁着一个连,这样对第一台机器的压力很有影响。
总结
比较推荐的使用方法是:拥有一个完整的RabbitMQ集群、配置一套高可用的负载均衡器以及兼容集群的消费者和生产者(能在集群节点发生故障时保持通信)。
RabbitMQ集群只是构建快速恢复的消息通信基础架构的一半,另一半取决于应用程序。应用程序可以在面对集群节点故障时快速恢复:通过重新连接新的节点并重建通信结构以使得程序继续运行。
同样重要的是,可以设置并使用负载均衡来确定哪个集群节点有故障,同时在应用程序重连时智能地路由到新的节点。
这些技术和RabbitMQ集群相结合,才能带来更健壮的消息通信基础架构而不会受到故障影响,也不会让应用程序停顿。
?
RabbitMQ配置负载均衡的意义及RabbitMQ集群是否可以随意使用
标签:main cluster def virtual 图片 com bin 创建 又能
原文地址:https://blog.51cto.com/10546390/2416124