标签:默认 sele 返回 数据库地址 创建ca 变更 mamicode 位置 pip
准备前--otter配置流程otter配置比较繁琐,并不会特别复杂,我这里先大概说下流程和几个关键名词解释
**otter名词解释:**
数据源:读取的源实例信息,和写入的目标实例信息
数据表:配置映射用的,用于配置,源实例,什么库,什么表,同步到目标什么库,什么表
canal:otter是做增量同步的,增量同步基于mysql的binlog日志,并且是row格式。这里需要配置你读取binlog的信息,和数据源里面的源实例信息可以说是同一个。
通道配置: otter采用一个实例一个通道方式。一个实例可以多个配置多个库
pipeline:主要核心功能如下
(1)选择你的canal配置,读取哪个实例的binlog。
(2)选择整个同步是在哪个节点上进行,例如我们部署了三个node节点,可以由node1进行读取的操作,可以由node2进行目标实例写入操作。也可以同时放到一个节点上。
(3)binlog位置,默认不写就读最新位置的。
(4)高级配置里面有是否跳过DDL,传输模式,负载均衡算法等,一般保持默认即可。
**流程:**
(1)新增数据源,一般最少配置2个,一个读取的源库,一个目标
(2)数据表,配置映射关系,从哪里同步到哪里。
(3)Canal,配置读取binlog的信息
上面步骤创建好后,我们就可以正式开始配置通道了
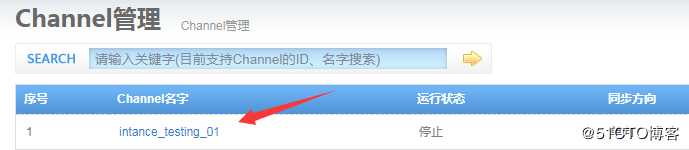
(4)创建通道
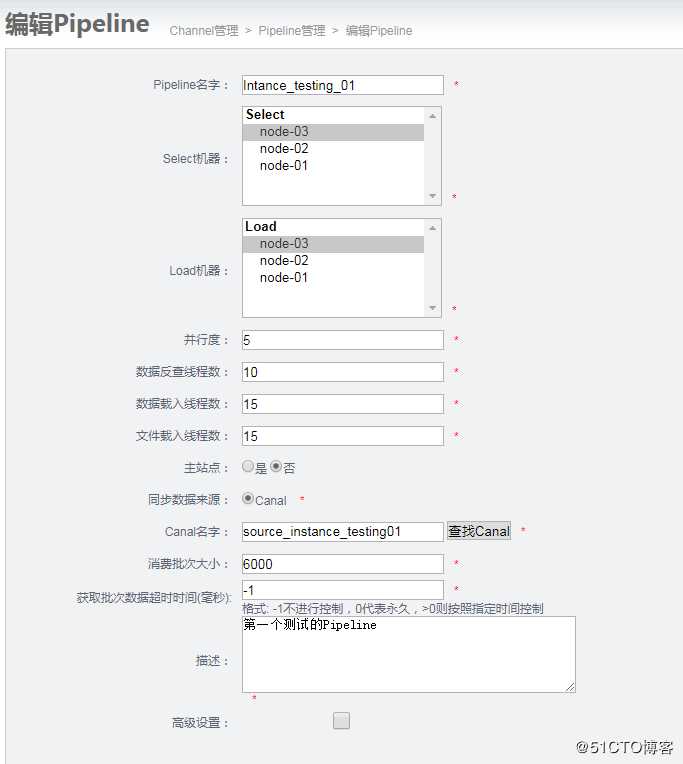
(5)创建pipeline
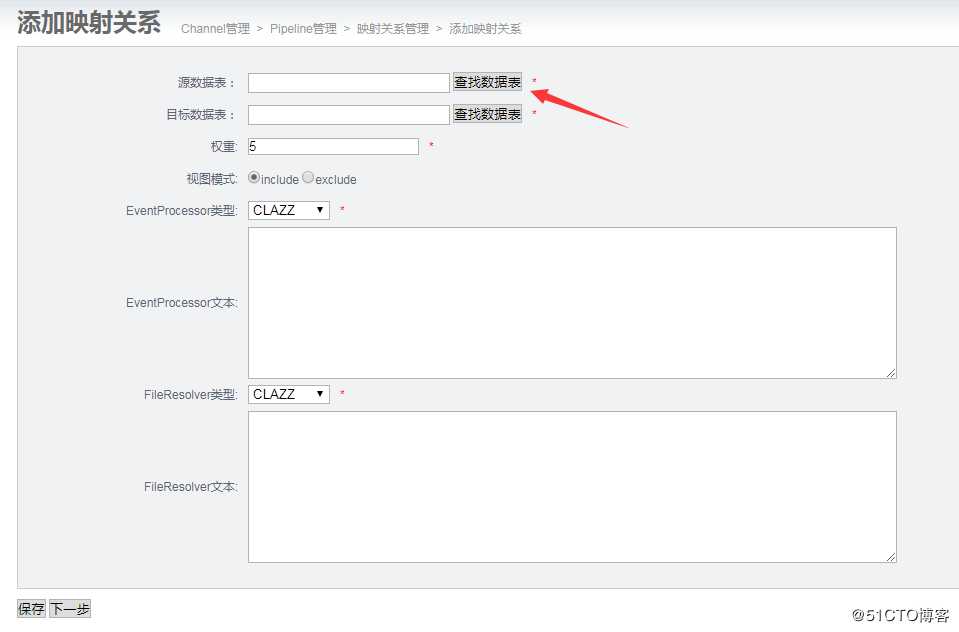
(6)创建表映射关系
(7)启动通道
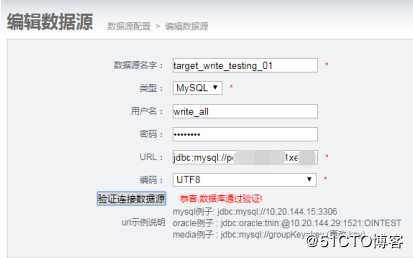
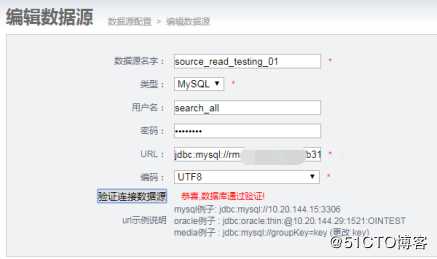
我这里新增了两个数据源,一个叫read(读取源)实例,一个叫write(写入的目标)实例.
(1)详细编辑配置如下
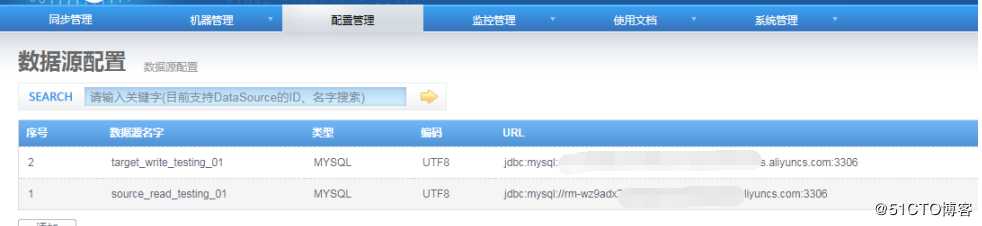
(2)配置成功后的列表
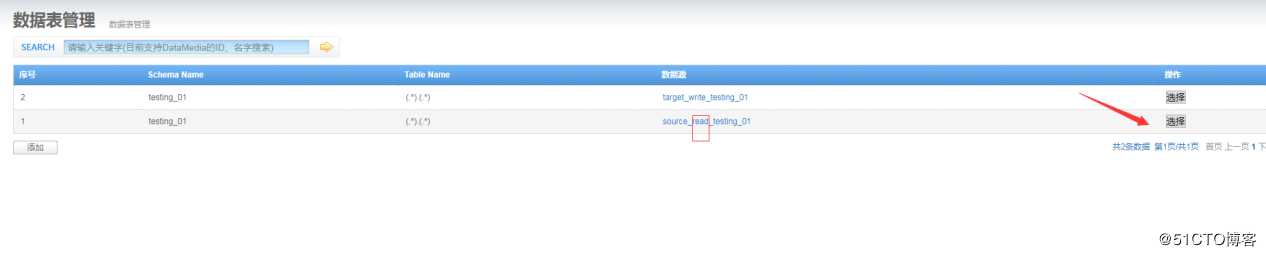
source_read_testing_01: 要读取数据的实例
target_write_testing_01: 要写入数据的实例2. 同步表配置
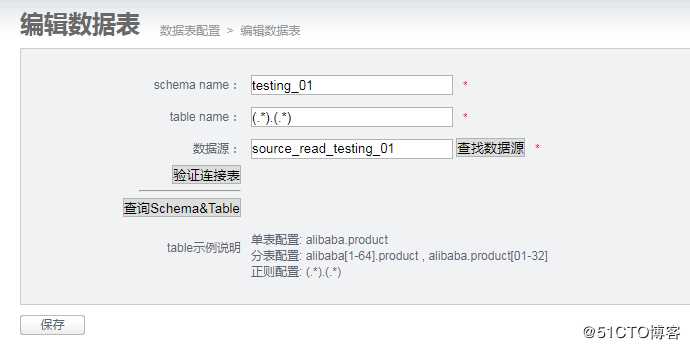
(1)读库表配置-详细信息编辑
这里主要是配置你要读取的数据库名,表名。
schema name: 配置库名称
Table name:因为我们是同步库下面的所有表,所以就填写了一个正则表达式;
数据源:选择源库(上面的步骤实例配置已配置,选择即可)
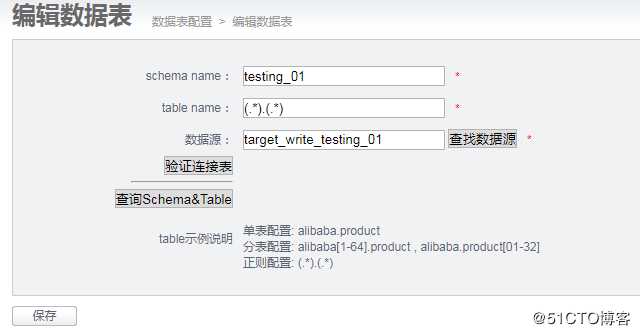
(2)写库表配置-详细信息编辑
这里主要是配置你要写入的数据库名,表名。
Schema name: 配置库名称
Table name:因为我们是同步库下面的所有表,所以就填写了一个正则表达式;
数据源:选择目标库(上面的步骤实例配置已配置,选择即可)
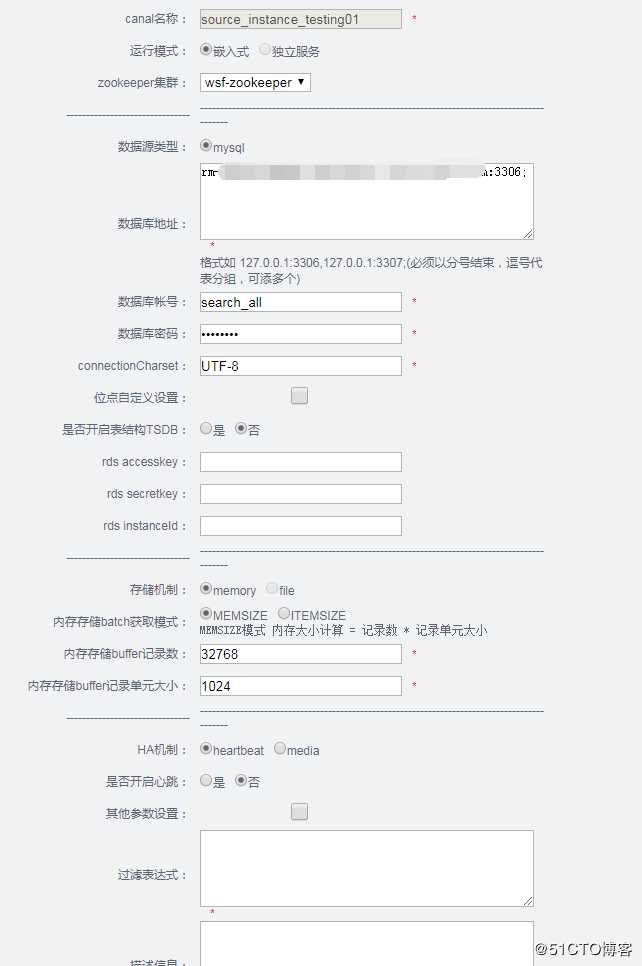
Canal配置,主要是读取的源实例的binlog日志用的
Canal名称: 自定义
Zookeeper:默认会自动选择,前面已配置过了
数据库类型:Mysql
数据库地址:就是你要获取数据库binlog的地址【和源库实例一样】
账号密码:需要有获取binlog权限的账号噢。
其他内容可不填写
创建Canal
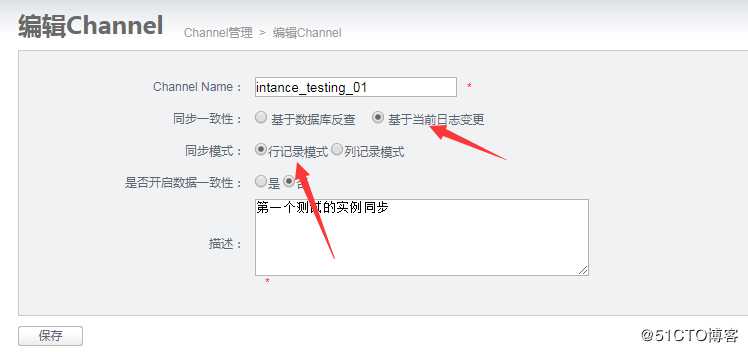
选择基于当前日志变更,选择行记录;名称可自定义;5.Pipeline配置
步骤1 : 点击Channel通道名称,进入下一步步骤2 : 新增Pipleline,点击添加
选择select 和load 的节点。一个是读,一个是写。选择同一个节点,减少网络之间的传输。
Canal名称: 选择刚才canal配置添加的,其他保持不变6.映射关系配置
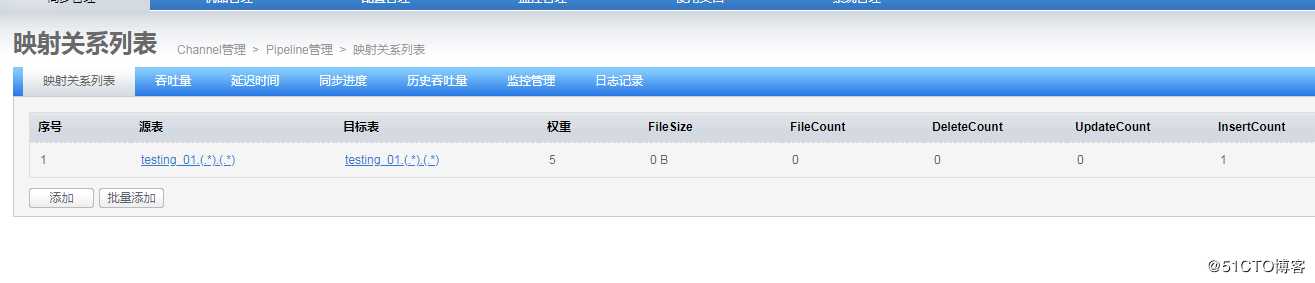
意思就是,你要在这条通道上,什么样的规则进行同步,就是表与表之间的配置
步骤1: 点击Pipeline进入映射关系配置步骤2:添加映射关系
步骤3:查找数据表
源数据表: 选择只读源库表
目标数据表: 选择目标库表
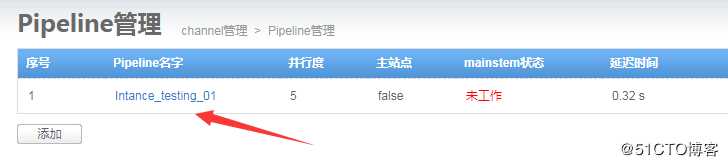
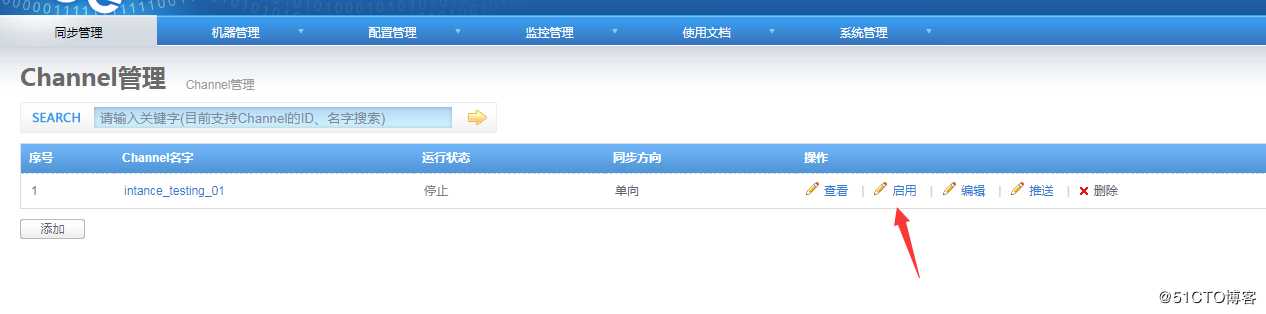
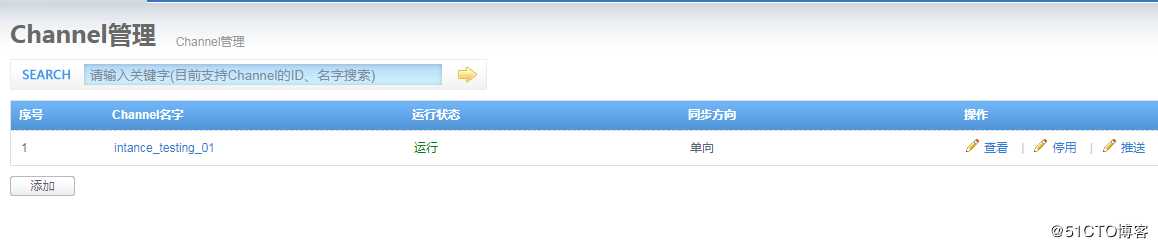
保存后,内容如下,返回通道首页7.启动通道
在源库新增数据,验证目标库表是否正常
标签:默认 sele 返回 数据库地址 创建ca 变更 mamicode 位置 pip
原文地址:https://blog.51cto.com/jiajinh/2416265