标签:href 概率 info 逻辑回归 导出 梯度下降 tps inf 回归
参考地址:
https://www.zhihu.com/question/65350200
https://github.com/GreedyAIAcademy/Machine-Learning
https://zhuanlan.zhihu.com/p/70587472
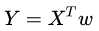
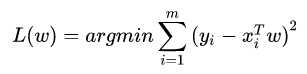

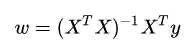
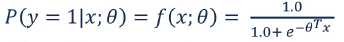
函数的图像:
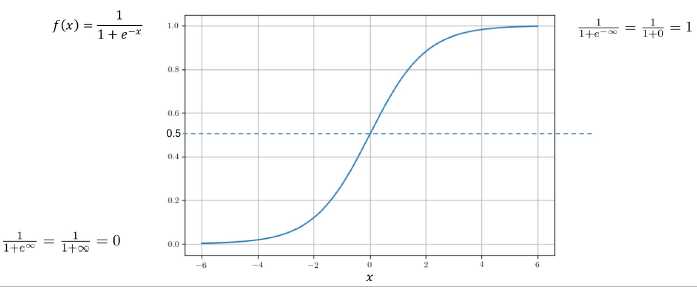
当P(y=1|x)的值>0.5时输出1,否则输出0
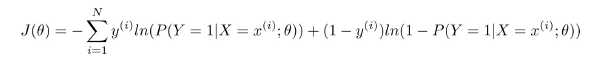
梯度值:
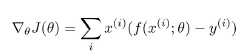
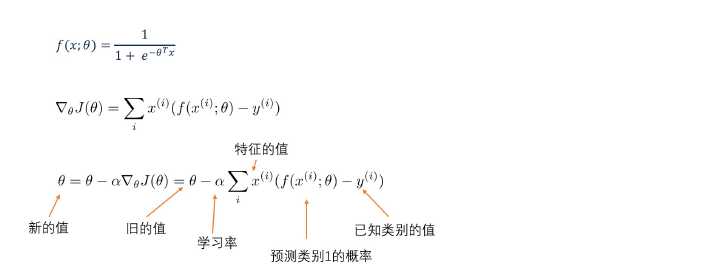
假设分段函数f(x)结果只两个值0,1,为1的概率为p,为0的概率就是1-p,规范一些,可以描述如下:
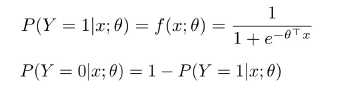
我们把训练数据(X,y)代入公式,让矩阵中所有的p(1-p)相乘。
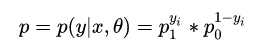
为什么要相乘?有人说是因为要用一个函数将y=0和y=1的形式统一起来,其实不准确,应该是为了“最大似然估计”。
参考:https://www.zhihu.com/question/65350200
通过最大似然估计,推导出损失函数
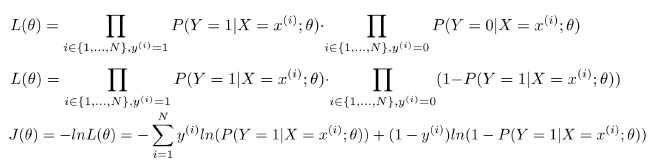
似然函数:
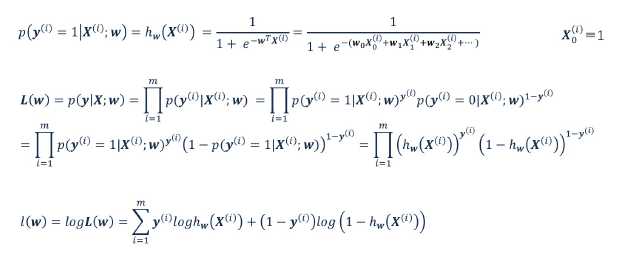
似然函数,对权值求偏导数
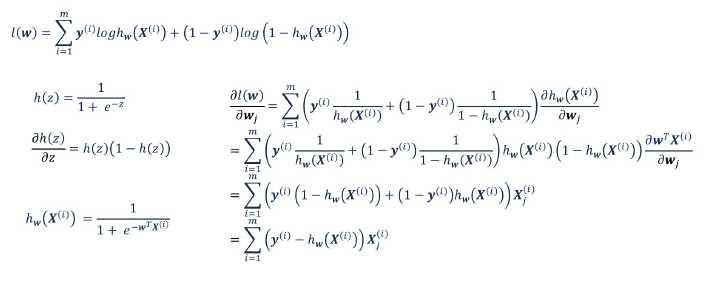
标签:href 概率 info 逻辑回归 导出 梯度下降 tps inf 回归
原文地址:https://www.cnblogs.com/bugutian/p/11123484.html