标签:hugo 存在 是的 最小 enter enc conf format 组成
分类问题就像披着羊皮的狼,看起来天真无害用起来天雷滚滚。比如在建模前你思考过下面的问题么?
要是您都想到了拜拜??。要是有1各您感兴趣的问题,那就接着往下看吧。本来是想先回顾一下各个分类问题中可能用到的metric,但是又觉得读的人可能觉得无聊,就分成了两章。要是有的指标断片了就来这里回忆一下: 回忆篇
分类问题可以根据对输出形式的要求分成两类
有人会问,上述两种需求究竟对解决一个二分类问题有什么影响? 答案是损失函数/评价指标
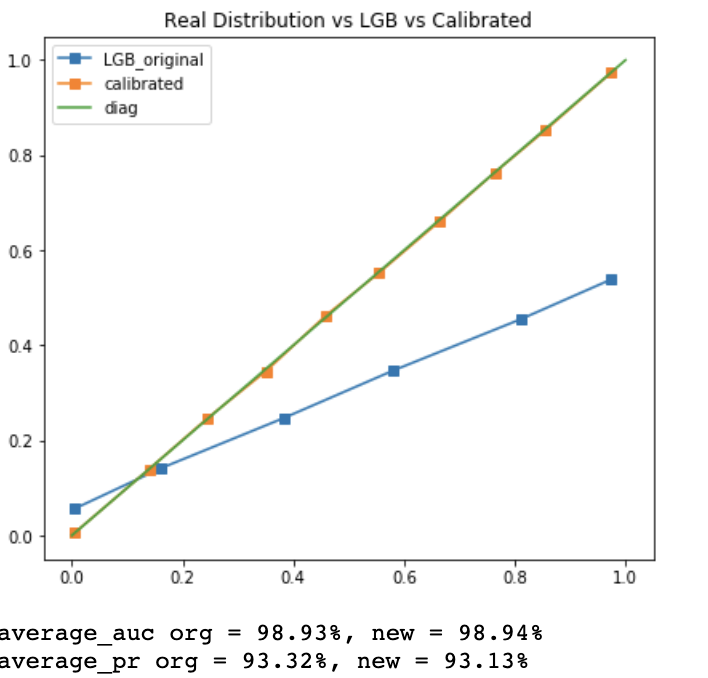
让我们来看一个直观的例子,下图我们尝试用LightGBM解决一个二分类问题,我们选择的拟合指标是最大化AUC。
X轴是预测概率,Y轴是真实概率,蓝线是LGB的预测结果,绿线对应真实概率=预测概率。为什么模型的AUC高达98.93%(这里还有ImbalancedSample的影响,让我们先忽略这一点),但是预测概率和真实概率却差到了姥姥家。
让我们对预测概率再做一层处理,黄线可以简单理解为我们对LGB的预测结果做了一层映射 \(\hat{p} \to f(\hat{p})\),这时校准后的预测概率和真实概率基本一致了。但是有趣的是校准后的预测概率AUC = 98.94%和原始预测基本没差别?!
Duang Duang Duang!敲黑板!AUC是对相对概率排序的检验!其实只要用心(我学AUC的时候一定没用心>_<)看一下AUC的计算方式就会发现,AUC只关心给定各个阈值,把样本按照预测概率分成0/1,并计算正负样本预测的准确率。
举个最夏天的例子,两个瓜一个甜一个不甜,我们训练一个西瓜模型来预测它们甜(1)/不甜(0)。
模型1: 甜的瓜预测概率是0.8,不甜的瓜预测概率是0.1,
模型2: 甜的瓜预测概率是0.51,不甜的瓜预测概率是0.49
两个模型的AUC是相同的,因为它们都完美对两个瓜进行了分类。
所以当使用最大化AUC作为损失函数时,当正负样本的预测准确率不再提高,模型就会停止学习。这时模型的预测概率并不是对真实概率的拟合。那如何才能得到对真实概率的预测? 答案是logloss/cros-entropy
\[ \begin{align} L &= \sum_{i=1}^N y_i * log(p_i) + (1-y_i) *log(1-p_i)\\end{align} \]
我们可以从两个角度来理解为什么logloss是对真实概率的估计
从极大似然估计的角度
logloss可以由极大似然函数取对数得到,最小化logloss对应的最大化似然函数。\(p_i\)是对\(p(y_i=1)\)的估计
\[
argmax_p \prod_{i=1}^N {p_i}^{y_i} * {(1-p_i)}^{1-y_i}
\]
从信息论的角度
不熟悉信息论的同学看这里 Intro to Information Theory
logloss也叫cross-entropy(交叉熵),用来衡量两个分布的相似程度。
交叉熵本身可以分解为P本身的信息熵+分布P和分布q之间的距离。这里P是样本的真实分布信息,信息熵一定。所以最小化交叉熵就变成了最小化分布p和q之间的距离,也就是样本分布和模型估计间的距离,如下
\[
\begin{align}
crossentropy &= H(p,q)\ &= -\sum_{c=1}^C p(c) * log(q(c))\ & = - \sum_{c=1}^C p(c) * log(p(c)) + \sum_{c=1}^C p(c)[log(p(c) - log(q(c)))] \ &= H(p) + KL(p||q)\\end{align}
\]
乍一看会觉得交叉熵和logloss长的不像一家人。因为在训练模型时分布p是从训练样本的分布中抽象得到的。二分类问题中C=2, 让我们把上述交叉熵再推一步
\[
\begin{align}
H(p,q) &= p *log(q) + (1-p) *log(1-q) \p& = \sum_{i=1}^N I(y_i=1)/N \H(p,q) &= \frac{1}{N} \sum_i I(y_i=1) *log(q)+ I(y_i=0) *log(1-q) \\end{align}
\]
所以下次解决分类问题,如果你的目标是计算对真实概率的估计的话,别选错指标哟?
兴趣卡片- 预测概率校准
其实黄线用了Isotonic Regression来校准预测概率。是一种事后将预测概率根据真实概率进行校准的方法。感兴趣的可以看一下Reference里面的材料1,2。原理并不复杂,但在分析特定算法,尤其是boosting,bagging类的集合算法为什么使用loggloss对概率估计依旧会有偏的部分蛮有趣的
正负样本分布不均大概是分类问题中最常遇到的问题。正确解决Imbalane问题需要注意的并不只是评价指标,往往还要注意采样和训练集测试集的划分。但这里我们只讨论在解决样本分布不均的问题时,我们应该选择什么指标来评价模型表现。让我们挨个来剔除不好用的指标。
举个极端的例子,100个样本里只有1个正样本
这种情况下即便我们全部预测为负,我们的准确率依旧高达99%。所以Accuracy只适用于正负样本均匀分布的情况,因为它把正负样本的预测准确率柔和在一起看了。
AUC是fpr和tpr(recall)组成的ROC的曲线下面积。还记得我们在【回忆篇】里面说过fpr,tpr是分别衡量在正负样本上的准确率的。
而fpr和tpr之间的trade-off,在正样本占比很小的情况下,这种trad-off会被样本量更大的一方主导。所以当正样本占比很小的时候,AUC往往会看起来过于优秀。
但就像硬币的正反面一样,从另一个角度看这也是AUC的优点,就是AUC本身不会很大的受到样本实际分布的影响,相同的模型相同的样本,你把正样本downsample /upsample 1倍,AUC不会有很大的改变。
下图来自An introduction to ROC analysis, 上面的AUC和PR是正负样本1:1的预测表现,下面是1:10的表现。我们会发现AUC基本没有变化,但是precision-recall发生了剧烈变化。
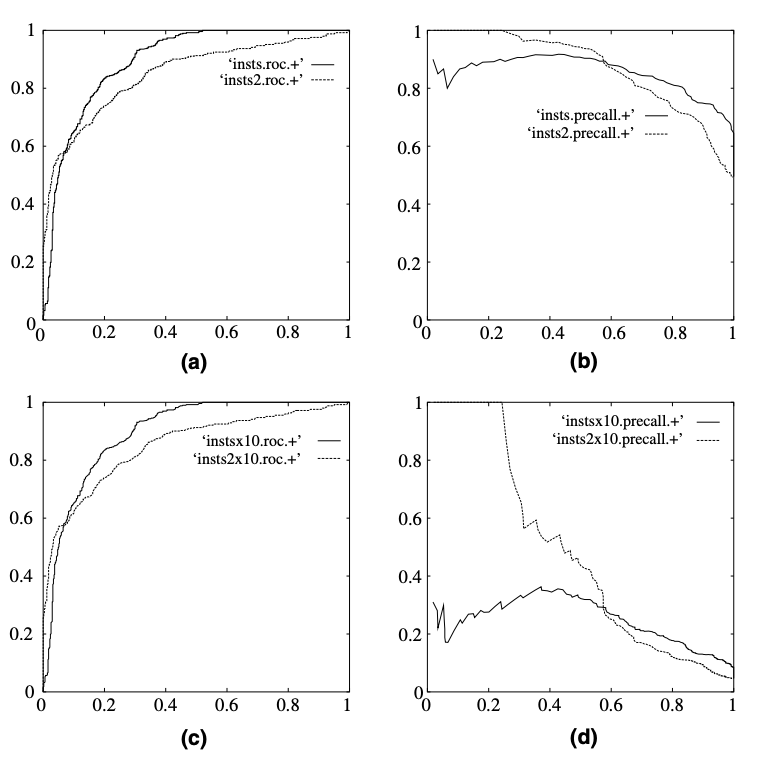
AP是recall和precision组成的PR的曲线下面积。这里recall和precision分别从真实分布和预测分布两个角度衡量了对正样本的预测准确率。说到这里已经有人反应过来了。是的这一对trade-off指标都是针对正样本的,在计算中没有用到True negative.所以当你的数据集存在Imbalance的时候,AP一般会是更好的选择。
Reference
Binary classification - 聊聊评价指标的那些事儿【实战篇】
标签:hugo 存在 是的 最小 enter enc conf format 组成
原文地址:https://www.cnblogs.com/gogoSandy/p/11123688.html