标签:次数 自己 必须 base 启动 ima url 记录 时间段
Dockerfile中使用HEALTHCHECK的形式有两种:
1、HEALTHCHECK [options] CMD command
2、HEALTHCHECK NODE 意思是禁止从父镜像继承的HEALTHCHECK生效
下面我们主要介绍第一种形式的应用:
options的可设定参数:
interval:间隔(s秒、m分钟、h小时),从容器运行起来开始计时interval秒(或者分钟小时)进行第一次健康检查,随后每间隔interval秒进行一次健康检查;还有一种特例请看timeout解析。
--start-period=DURATION 启动时间, 默认 0s, 如果指定这个参数, 则必须大于 0s ;--start-period 为需要启动的容器提供了初始化的时间段, 在这个时间段内如果检查失败, 则不会记录失败次数。 如果在启动时间内成功执行了健康检查, 则容器将被视为已经启动, 如果在启动时间内再次出现检查失败, 则会记录失败次数。
timeout:执行command需要时间,比如curl 一个地址,如果超过timeout秒则认为超时是错误的状态,此时每次健康检查的时间是timeout+interval秒。
retries:连续检查retries次,如果结果都是失败状态,则认为这个容器是unhealth的
CMD关键字后面可以跟执行shell脚本的命令或者exec数组。CMD后面的命令执行完的返回值代表容器的运行状况,可能的值:0 health状态,1 unhealth状态,2 reserved状态,这个没细研究,用的也很少。
注意:在Dockerfile中只能有一个HEALTHCHECK指令。如果您列出多个,则只有最后一个HEALTHCHECK将生效。
下面我们进行几个测试:
我手里有一个nginx的镜像,我们以它为base镜像进行一些简单的测试,以下是我的Dockerfile和测试脚本。
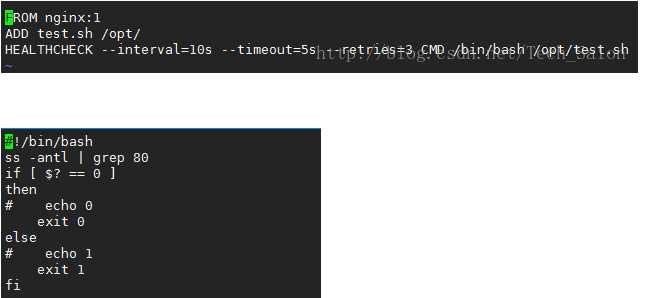
通过Dockerfile可以预计,容器启动10s内HEALTCHECK的状态为starting,10s后为healthy状态。脚本是监听容器的80端口,存在返回0,不存在返回1。
执行1、docker build -t test_nginx:2生成镜像
2、docker run -d test_nginx:2 启动容器。
3、通过docker ps查看HEALTHCHECK的状态 
验证:10s内health状态为starting,10s后状态为healthy
下面我们需要进到容器把nginx服务停掉,然后观察health的状态,预计变成unhealthy使用时间为30s(关于时间上不好展示,有兴趣的话可以自己去做测试)

登到容器先确认80端口存在,停掉nginx服务,80端口消失,查看容器health状态 ![]()
验证:关掉nginx服务后,脚本检测到80端口不存在,返回1,容器状态为unhealthy(应该是执行了三次这个脚本得到结果都是1才确认这个容器是不健康的)
关于上面变成unhealthy状态使用了30s的时间,认真看的同事可能会发现不应该是timeout+interval秒后变吗。我的command是执行一个脚本,很快就能得到结果,不存在timeout的情况,所以我设置timeout的意义并不大。
如果我这样设置HEALTHCHECK –interval=10s –timeout=3s –retries=3 CMD curl http://192.168.30.5:5000/v2。可能会出现curl这个地址3秒内没响应则认为失败,然后再开始interval的时间进行下次检测。最后显示unhealthy的状态应该是39s。这就不做测试了。
下面分享一个指令,通过docker指令得到指定容器id的健康状态
docker inspect –format ‘{{json .State.Health.Status}}’ 41f1414fab75
标签:次数 自己 必须 base 启动 ima url 记录 时间段
原文地址:https://www.cnblogs.com/shawhe/p/11126450.html