标签:charm for cpu 存储 补充 har 传输 文件 格式
1.运行程序的三个核心硬件 cpu 内存 硬盘 任何一个程序要想运算,必选先有硬盘加载到内存,然后cpu去内存取指执行 运行着的应用程序产生的数据 必先存在内存 2.python解释器运行一个py文件(xxx.py)步骤 1.将python解释器的代码由硬盘读到内存 2.将xxx.py以普通文本文件形式读到内存 3.python读取文件内容 识别python语法 执行相应操作 ps:普通的文本编辑器与python解释器前两步都是一样的
字符编码针对的是文字,只跟文本文件有关 文本编辑器的输入和输出是两个过程 人在操作计算机的时候输入的是人能够看懂的字符 但计算机只能识别0101这样的二进制数据 输入的字符 >>>通过字符编码表翻译成>>> 二进制数字 字符编码表就是字符与数字的对应关系 最早的字符编码为ASCII 用八位二进制表示一个英文字符 2*8=256所以ASCII码最多只能表示 256 个符号 所有的英文字符+符号最多也就在125位左右
现代计算机起源于美国,最早诞生也是基于英文考虑的ASCI 当我们编程语言都用英文没问题,ASCII够用 处理数据时,不同的国家有不同的语言 ASCII不够用 各国就定制的自己的语言对应的编码表 #为了满足中文和英文,中国人定制了GBK GBK:2Bytes代表一个中文字符1Bytes表示一个英文字符 规定了包含中文在内的字符->数字的对应关系 如果单纯采用一种国家的编码格式,那么其他国家语言的文字在解析时就会出现乱码,所以能包含全世界的语言的unicode编码表应运而生 #unicode 需要掌握 #1、能够兼容万国字符 #2、与全世界所有的字符编码都有映射关系,这样就可以转换成任意国家的字符编码 #ascii用1个字节(8位二进制)代表一个字符 #unicode常用2个(Bytes)字节(16位二进制)代表一个字符,生僻字需要用4个字节 乱码问题消失了,如果我们的文档通篇都是英文 #unicode相对ascii有两个缺点 #1.浪费存储空间 #2.io次数增加,程序运行效率降低(这是致命问题) #于是产生了UTF-8(可变长,全称Unicode Transformation Format),
对英文字符只用1Bytes表示,对中文字符用3Bytes,对其他生僻字用更多的Bytes去存 #总结:内存中统一采用unicode,浪费空间来换取可以转换成任意编码(不乱码),硬盘可以采用各种编码,如utf-8,保证存放于硬盘或者基于网络传输的数据量很小,提高传输效率与稳定性。
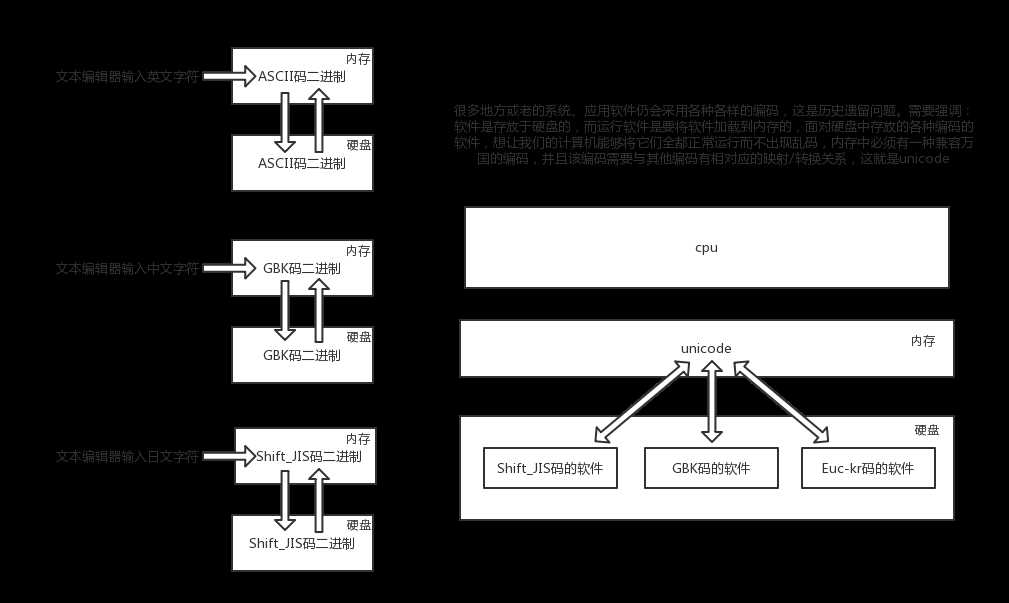
(必须掌握的) 数据由内存保存到硬盘 1.内存中的unicode格式二进制数字 >>>>编码(encode)>>>>> utf-8格式的二进制数据 硬盘中的数据由硬盘读到内存 1.硬盘中的utf-8格式的二进制数据 >>>>>解码(decode)>>>>> 内存中unicode格式的二进制数据 保证不乱码在于 文本文件以什么编码编的就以什么编码解 python2 将py文件按照文本文件读入解释器中默认使用ASCII码(因为在开发python2解释器的unicode还没有盛行) python3 将py文件按照文本文件读入解释器中默认使用utf-8 文件头 # coding:utf-8 1.因为所有的编码都支持英文字符,所以文件头才能够正常生效 基于Python解释器开发的软件,只要是中文,前面都需要加一个u 为了的就是讲python2(当你不指定文件头的时候,默认用ASCII存储数据,如果指定文件头那么就按照文件头的编码格式存储数据) python3中字符串默认就是unicode编码格式的二进制数 补充: 1.pycharm终端用的是utf-8格式 2.windows终端采用的是gbk
标签:charm for cpu 存储 补充 har 传输 文件 格式
原文地址:https://www.cnblogs.com/george-007/p/11140988.html