标签:air imp features mamicode 分类 函数的参数 ima 计算机视觉 inf
数据集介绍LFW (Labeled Faces in the Wild) 人脸数据库是由美国马萨诸塞州立大学阿默斯特分校计算机视觉实验室整理完成的数据库,主要用来研究非受限情况下的人脸识别问题。LFW 数据库主要是从互联网上搜集图像,而不是实验室,一共含有13000 多张人脸图像,每张图像都被标识出对应的人的名字,其中有1680 人对应不只一张图像,即大约1680个人包含两个以上的人脸。LFW数据集主要测试人脸识别的准确率。
from time import time #记录时间
import logging #打印程序的运行日志
import matplotlib.pyplot as plt
from sklearn.cross_validation import train_test_split #划分训练集和测试集
from sklearn.datasets import fetch_lfw_people #导入数据集(名人)
from sklearn.grid_search import GridSearchCV #调试函数的参数
from sklearn.metrics import classification_report #显示分类报告,显示主要的分类指标,准确率,召回率以及F1得分
from sklearn.metrics import confusion_matrix #对真实类别和预测类别做出判断,用矩阵形式表示出来
from sklearn.decomposition import RandomizedPCA #pca降维
from sklearn.svm import SVC #svm的svc方程
from sklearn.cluster.tests.test_k_means import n_samples
#训练集:sklearn自带的人脸图片数据集
lfw_people = fetch_lfw_people(min_faces_per_person=70,resize=0.4)
n_samples,h,w = lfw_people.images.shape #实例数目、h、w
x = lfw_people.data #所有的训练数据,1288张图片,每张图片1850个特征值
n_features = x.shape[1] #特征向量的维度1850
y =lfw_people.target #对应的人脸标记
target_names = lfw_people.target_names #需要识别的人名字
n_class = target_names.shape[0] #几个人需要识别
print("total dataset size:")
print("n_samples: %d" % n_samples)
print("n_features: %d" % n_features)
print("n_class: %d" % n_class)
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.25)
n_components = 150
t0 = time()
#随机将高维的特征向量降低为低维的,先建立模型
pca = RandomizedPCA(n_components=n_components,whiten=True).fit(x_train)
print("done in %0.3fs" %(time() - t0))
#提取人脸的特征值
eigenfaces = pca.components_.reshape((n_components,h,w)) #将人脸特征转化为特征向量集
print(‘projecting the input data on the eigenfaces orthonomal basis‘)
t0 = time()
#进行数据模型降维,降成了150
x_train_pca = pca.transform(x_train)
x_test_pca = pca.transform(x_test)
print("done in %0.3fs" % (time() - t0))
print("fitting the classfier to the training set")
t0 = time()
#C 是对错误部分的惩罚;gamma 合成点
para_grid = {‘C‘:[1e3,5e3,1e4,5e4,1e5],‘gamma‘:[0.0001,0.0005,0.0001,0.005,0.01,0.1],}
#rbf处理图像较好,C和gamma组合,穷举出最好的一个组合 使用GridSearchCV进行自由组合,最终确定合适的组合
clf = GridSearchCV(SVC(kernel=‘rbf‘),para_grid)
clf = clf.fit(x_train_pca,y_train)
print("done in %0.3fs" % (time() - t0))
print("best estimator found by grid search:")
print(clf.best_estimator_) #最好的模型的信息
print("predict the people‘s name on the test set")
t0 = time()
y_pred = clf.predict(x_test_pca)
print("done in %0.3fs" % (time() - t0))
print(classification_report(y_test,y_pred,target_names=target_names))
print(confusion_matrix(y_test,y_pred,labels=range(n_class)))
def plot_gallery(images,titles,h,w,n_row = 3,n_col = 4):
plt.figure(figsize=(1.8*n_col,2.4*n_row))
plt.subplots_adjust(bottom = 0,left = .01,right = .99,top = .90,hspace = .35)
for i in range(n_row * n_col):
plt.subplot(n_row,n_col,i+1)
plt.imshow(images[i].reshape((h,w)),cmap=plt.cm.gray)
plt.title(titles[i],size = 12)
plt.xticks()
plt.yticks()
def title(y_pred,y_test,target_names,i):
pred_name = target_names[y_pred[i]].rsplit(‘ ‘,1)[-1]
true_name = target_names[y_test[i]].rsplit(‘ ‘,1)[-1]
return ‘predicted : %s \nture: %s‘ % (pred_name,true_name)
prediction_titles = [title(y_pred,y_test,target_names,i) for i in range(y_pred.shape[0])]
plot_gallery(x_test,prediction_titles,h,w)
eigenface_title = ["eigenface %d" % i for i in range(eigenfaces.shape[0])]
plot_gallery(eigenfaces,eigenface_title,h,w)
plt.show()total dataset size:
n_samples: 1288
n_features: 1850
n_class: 7
done in 0.270s
projecting the input data on the eigenfaces orthonomal basis
done in 0.040s
fitting the classfier to the training set
done in 30.796s
best estimator found by grid search:
SVC(C=1000.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=‘ovr‘, degree=3, gamma=0.005, kernel=‘rbf‘,
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
predict the people‘s name on the test set
done in 0.125s precision recall f1-score support
Ariel Sharon 0.91 0.67 0.77 15
Colin Powell 0.80 0.82 0.81 45
Donald Rumsfeld 0.96 0.61 0.75 41
George W Bush 0.79 0.96 0.87 144
Gerhard Schroeder 0.95 0.63 0.76 30
Hugo Chavez 1.00 0.79 0.88 19
Tony Blair 0.86 0.89 0.88 28
avg / total 0.85 0.84 0.83 322混淆矩阵
[[ 10 2 0 3 0 0 0]
[ 1 37 0 7 0 0 0]
[ 0 1 25 13 1 0 1]
[ 0 4 1 138 0 0 1]
[ 0 1 0 8 19 0 2]
[ 0 1 0 3 0 15 0]
[ 0 0 0 3 0 0 25]]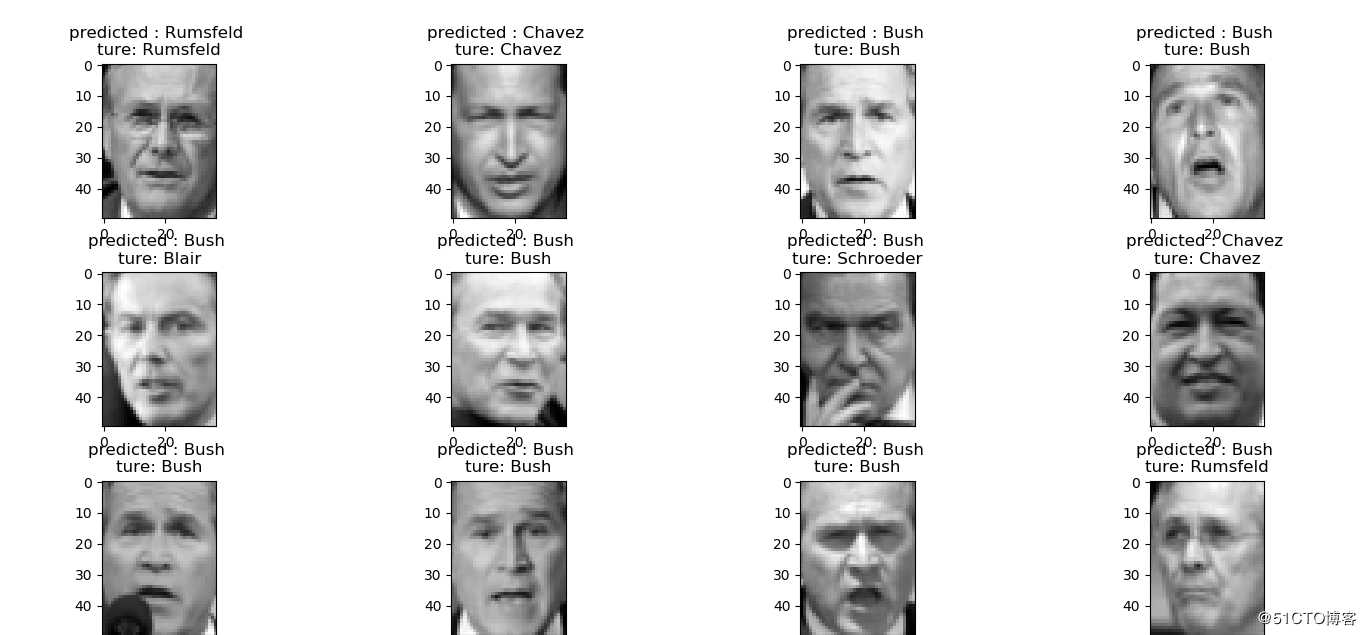
标签:air imp features mamicode 分类 函数的参数 ima 计算机视觉 inf
原文地址:https://blog.51cto.com/13646338/2417291