在实际开发中我们往往需要自己定义一些对于 RDD 的操作,那么此时需要主要的
是,初始化工作是在 Driver 端进行的,而实际运行程序是在 Executor 端进行的,这就涉及
到了跨进程通信,是需要序列化的。下面我们看几个例子:
2.6 RDD 依赖关系
2.6.1 Lineage
RDD 只支持粗粒度转换,即在大量记录上执行的单个操作。将创建 RDD 的一系列
Lineage(血统)记录下来,以便恢复丢失的分区。RDD 的 Lineage 会记录 RDD 的元数据
信息和转换行为,当该 RDD 的部分分区数据丢失时,它可以根据这些信息来重新运算和
恢复丢失的数据分区。
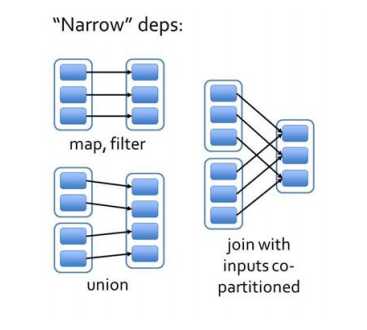
2.6.2 窄依赖
窄依赖指的是每一个父 RDD 的 Partition 最多被子 RDD 的一个 Partition 使用,
窄依赖我们形象的比喻为独生子女
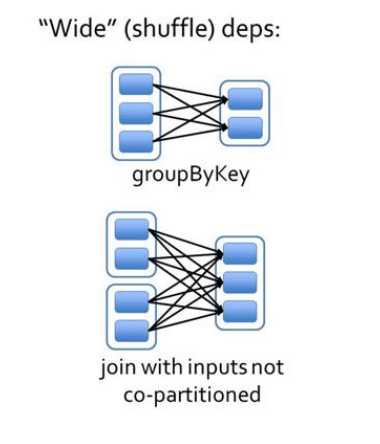
2.6.3 宽依赖
宽依赖指的是多个子 RDD 的 Partition 会依赖同一个父 RDD 的 Partition,会引起 shuffle,
总结:宽依赖我们形象的比喻为超生
2.6.4 DAG
DAG(Directed Acyclic Graph)叫做有向无环图,原始的 RDD 通过一系列的转换就就
形成了 DAG,根据 RDD 之间的依赖关系的不同将 DAG 划分成不同的 Stage,对于窄依
赖,partition 的转换处理在 Stage 中完成计算。对于宽依赖,由于有 Shuffle 的存在,只能
在 parent RDD 处理完成后,才能开始接下来的计算,因此宽依赖是划分 Stage 的依据。
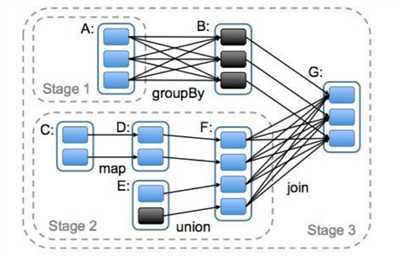
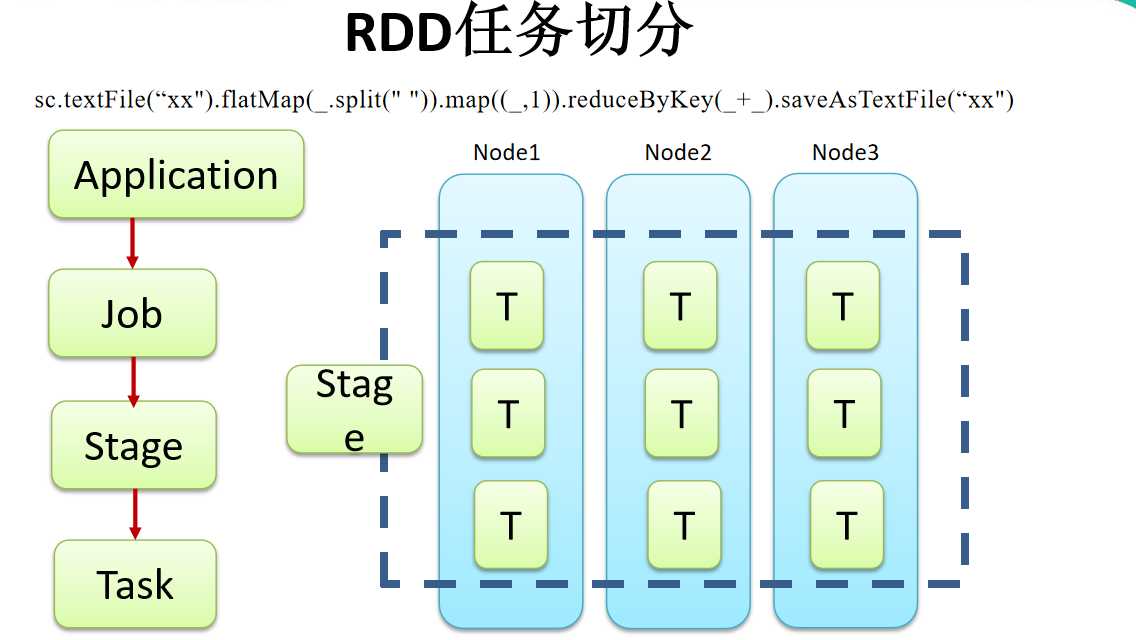
2.6.5 任务划分(面试重点)
RDD 任务切分中间分为:Application、Job、Stage 和 Task
1)Application:初始化一个 SparkContext 即生成一个 Application(一个 jar 包相当于一个 Application)
一个 Application 可以有多个 Job。
2)Job:一个 Action 算子就会生成一个 Job
一个 Job 中可以有多个 Stage。
3)Stage:根据 RDD 之间的依赖关系的不同将 Job 划分成不同的 Stage,遇到一个宽依赖则划分一个 Stage。
4)Task:Stage 是一个 TaskSet,将 Stage 划分的结果发送到不同的 Executor 执行即为一个 Task。
一个 Task 就是一个并行度,并行度和数据分片有关
注意:Application->Job->Stage->Task 每一层都是 1 对 n 的关系。
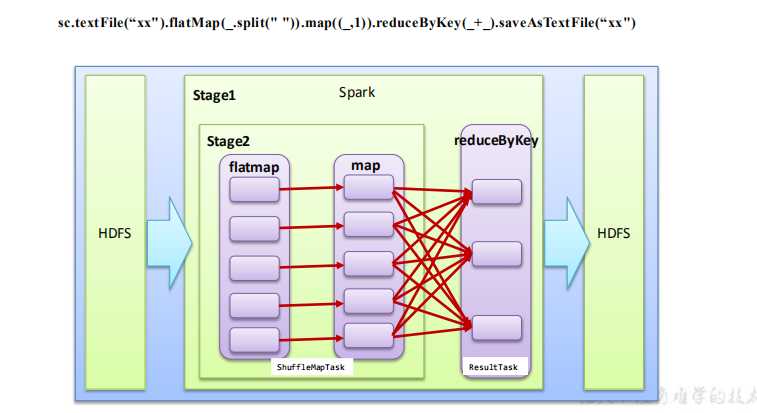
划分 Stage 从后往前划分,遇到一个宽依赖则划分一个 Stage,将其放入栈。
运行从前往后执行。
2.7 RDD 缓存
RDD 通过 persist 方法或 cache 方法可以将前面的计算结果缓存,默认情况下 persist()
会把数据以序列化的形式缓存在 JVM 的堆空间中。
但是并不是这两个方法被调用时立即缓存,而是触发后面的 action 时,该 RDD 将会
被缓存在计算节点的内存中,并供后面重用。