标签:strong 机器学习 bsp under image 样本 不同 兴趣 没有
性能度量是衡量模型泛化能力的评价标准,模型的好坏是相对的,模型的好坏不仅取决于算法和数据,还决定于任务的需求。
回归任务中常用的性能度量是:均方误差(越小越好),解释方差分(越接近1越好)。
分类任务中常用的性能度量:
1)错误率:分类错误的样本数占样本总数的比例。
2)精度:分类正确的样本数占样本总数的比例。
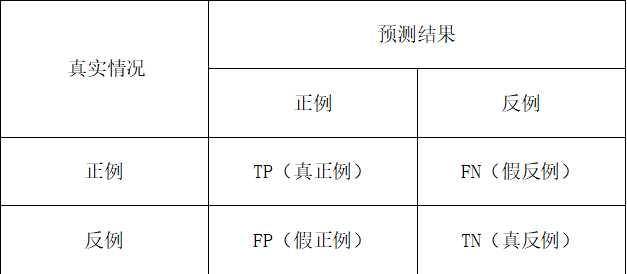
3)查准率也叫准确率(Precision):在所有的预测为正例的结果中,真正例所占的比率
查准率=真正例/(真正例+假正例)
检索出的信息中有多少比例是用户感兴趣的”,在推荐系统中为了尽少的打扰用户,更希望推荐的内容是用户感兴趣的,此时查准率更重要。
4)查全率也叫召回率(Recall):在所有的正例中有多少被成功预测出来了
查全率=真正例/(真正例+假反例)
用户感兴趣的信息中有多少被检索出来了。
查准率与查全率是一对矛盾的度量。一般度量学习器的好坏用F1得分
F1 = 2*(Precision*Recall)/(Precision+Recall)
5)ROC曲线与AUC
详细介绍参考:
https://zhuanlan.zhihu.com/p/26293316
http://alexkong.net/2013/06/introduction-to-auc-and-roc/
AUC是ROC曲线下的面积
ROC曲线的纵轴是真正例率,横轴是假正例率。
真正例率(TPR):真实的正例中,被预测正确的比例
计算公式:真正例/(真正例+假反例)
假正例率(FPR):真实的反例中,被预测错误的比例
计算公式:假正例/(真反例+假正例)
首先明确:ROC曲线的横坐标和纵坐标其实是没有相关性的,所以不能把ROC曲线当做一个函数曲线来分析,应该把ROC曲线看成无数个点,这些点代表着一个分类器在不同阈值下的分类效果。
ROC如何画?
假设我们获得了每个测试样本属于正例的概率输出,把这些概率从大到小进行排序,我们从高到低,依次将Score值作为阈值threshold,当测试样本属于正样本的概率大于或等于这个threshold时,我们认为它为正样本,否则为负样本。每次选取一个不同的threshold,我们就可以得到一组FPR和TPR,即ROC曲线上的一点。ROC曲线越接近于左上角说明分类器的性能越好(因为横轴是假正利率纵轴是真正利率,越接近于左上角说明纵轴值越大真实的正例中,被预测正确的比例越大;横轴越小,真实的反例中,被预测错误的比例越小,说明模型性能越好,具体衡量就是AUC的值越大)。
标签:strong 机器学习 bsp under image 样本 不同 兴趣 没有
原文地址:https://www.cnblogs.com/dyl222/p/11144055.html