标签:ann 乘法 image img spark info 正是 学习 erro
我有过阿里、腾讯、滴滴、宜信等等的面试经历,这是我死的最惨的一次,腾讯排第二。
如下问题:
1.你觉得大数据生态圈从技术角度来看,未来会朝什么方向发展?
1.2.大数据处理的时候为什么选择spark而不是hadoop
答:1.spark是内存计算的,而hadoop是磁盘计算的,所以spark比hadoop快
2.spark兼容性高,开发简单而且spark能够读取hadoop上任何的数据
2.逻辑回归与线性回归的原理与区别
答:逻辑回归多了一个Sigmoid函数,使样本能映射到[0,1]之间的数值,用来做分类问题。线性回归用来预测,逻辑回归用来分类。线性回归是拟合函数,逻辑回归是预测函数。线性回归的参数计算方法是最小二乘法,逻辑回归的参数计算方法是梯度下降。
3.kmeans聚类最后收敛的依据是什么
答:每个样本点到其质心的距离平方和不变
4.梯度下降和反向传播的原理与区别
答:梯度下降算法用来修正权值以达到减小目标函数的目的,梯度下降算法在执行过程中要使用到各层神经元输出权值的偏导数(动态变化的,所以是微分形态出现),而反向传播算法正是计算各层神经元输出权值偏导数的利器。

反向传播算法是神经网络中最有效的算法,其主要的思想是将网络最后输出的结果计算其误差,并且将误差反向逐级传下去。
5.交叉熵的公式?以及为什么选择这个损失函数
答:均方误差(error of mean square)、最大似然误差(maximum likelihood estimate)、最大后验概率(maximum posterior probability)、交叉熵损失函数(cross entropy loss)。
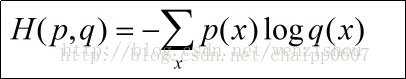
6.分类和回归算法各有哪些?
答:输入变量与输出变量均为连续变量的预测问题是回归问题;输出变量为有限个离散变量的预测问题成为分类问题;
转:https://www.cnblogs.com/yuanninesuns/p/9801257.html
标签:ann 乘法 image img spark info 正是 学习 erro
原文地址:https://www.cnblogs.com/Ph-one/p/11145764.html