标签:== reporting 分区 exception lis appname lob txt workload
1 采集模块整体架构
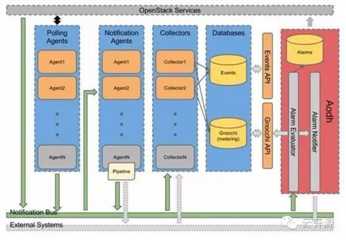
采集模块主要分为三大块。
Ceilometer:用于采集数据并处理数据后发送到gnocchi服务去存储
Gnocchi:用于将采集数据进行计算合并和存储并提供rest api方式接收和查询监控数据
Aodh:主要负责告警功能
1.1 Ceilometer架构
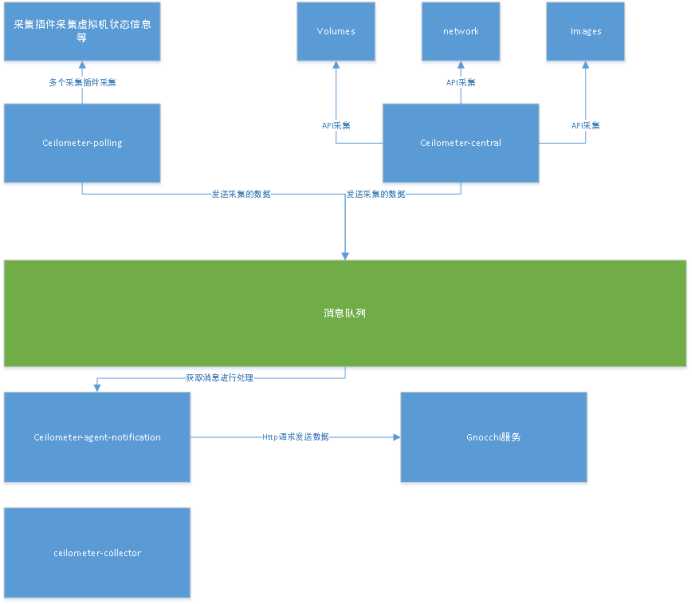
Ceilometer-polling服务:通过调用多个采集插件(采集插件在setup.cfg中有定义,ceilometer.poll.compute对应的就是采集插件)收集信息,这个服务收集的是有关虚拟机资源使用情况相关的数据,比如cpu、内存占用率等,通过libvirt获取这些信息,并发送到notifications.sample队列中保存。
Ceilometer-central服务:也是采集数据的服务,但它是通过API的轮询方式去获取一些服务的信息,采集的是Ceilometer-polling服务采集以外的信息,比如磁盘服务的状态和总共使用了多少。
Ceilometer-agent-notification:polling服务采集到的原始数据称为Meter。Meter是资源使用的计量项,它的属性包括:名称(name)、单位 (unit)、类型(cumulative:累计值,delta:变化值、gauge:离散或者波动值)以及对应的资源属性等,不符合相关格式,因此可以在发送数据前进行一些转换,这个转换称为Transformer,一条Meter数据可以经过多个Transformer处理后再由publisher发送。
这个是处理数据并进行数据转换的服务,该服务先是从notifications.sample队列中取出消息,
然后经过处理和转换成measure结构后发送数据到gnocchi服务中去。
Ceilometer-collector服务:该服务在以前的版本中是用来获取监控数据消息然后统一处理后发给Gnocchi-api服务的,但现在通过配置pipeline.yaml配置文件的publisher为gnocchi,则不经过ceilometer-collector中转了,直接发送到gnocchi-api服务里去处理。
Gnocchi服务:对监控数据进行聚合计算并存储到后端存储并提供获取监控数据的rest api接口。
1.2 Gnocchi架构
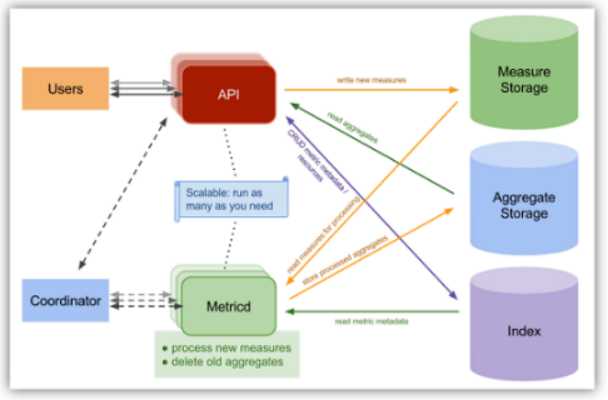
这个图看着不清晰,但可以看以下解释就能知道它的处理流程
从图可以看出Gnocchi的服务主要包含两大服务,API和Metricd服务。同时可以看到有三个存储,Measure Storage、Aggregate Storage和Index。
Measure Storage:是经过ceilometer-agent-notification服务处理后发送过来的数据,是实际的监控数据,但这些数据还需要经过gnocchi服务处理,处理后就会删除掉。比如这部分数据就可以保存到file中,当然也支持保存到ceph,但这属于临时数据,所以用file保存就可以了。
Aggregate Storage:Aggreate是总数、合计的意思,gnocchi服务采用的是一种独特的时间序列存储方法,这个存储存放的是按照预定义的策略进行聚合计算后的数据,这样在获取监控数据展示时速度就会很快,因为已经计算过了。用户看到的是这层数据。后端存储包括file、swift、ceph,influxdb,默认使用file。可以保存到ceph中,这样可在任意一个节点上获取,但由于存储的都是大量小文件,大量的小文件对ceph来说并不友好。
Index:通常是一个关系型数据库(比如MYSQL),是监控数据的元数据,用以索引取出resources和metrics,使得可以快速的从Measure Storage和Aggregate Storage中取出所需要的数据。
API:gnocchi-api服务进程,可以托管到httpd服务一起启动,通过Indexer和Storage的driver,提供查询和操作ArchivePolicy,Resource,Metric,Measure的接口,并将新到来的Measure(也就是ceilometer-agent-notification发送到gnocchi-api服务的数据)存入Measure Storage。
Metricd:gnocchi-metricd服务进程,根据Metric定义的ArchivePolicy规则周期性的从Measure Storage中获取未处理的Measure数据并进行处理,将处理结果保存到Aggregate Storage中,同时也对Aggregate Storage中的数据进行聚合计算和清理过期的数据。
API和Metricd服务都是设计成了无状态的服务,可以横向拓展来加快数据的处理。
2 代码流程解析
2.1 Ceilometer-polling服务采集数据流程
首先看该程序的入口函数:
File:ceilometer/cmd/polling.py
def main(): conf = cfg.ConfigOpts() conf.register_cli_opts(CLI_OPTS) service.prepare_service(conf=conf) # cotyledon库是用来替代oslo.service库的,提供跟oslo.service类似的管理服务功能 sm = cotyledon.ServiceManager() # 添加一个AgentManager管理类来运行 # 初始化该实例会进行插件加载和消息发送实例初始化 sm.add(create_polling_service, args=(conf,)) oslo_config_glue.setup(sm, conf) # 调用AgentManager类实例的run方法启动服务 sm.run()
可以看到这里进行了一些配置文件获取的初始化,最重要的是代用create_polling_service函数进行AgentManager类初始化。查看该类初始化代码:
File:ceilometer/agent/manager.py
class AgentManager(service_base.PipelineBasedService): def __init__(self, worker_id, conf, namespaces=None, pollster_list=None, ): # ceilometer-compute服务传入的是namespaces是compute namespaces = namespaces or [‘compute‘, ‘central‘] pollster_list = pollster_list or [] ...... # we‘ll have default [‘compute‘, ‘central‘] here if no namespaces will # be passed ‘‘‘ 加载采集插件 # 根据namespance加载setup.cfg文件下的ceilometer.poll.compute、ceilometer.poll.central或 ceilometer.builder.poll.central 这三个namespaces下对应的插件 ‘‘‘ extensions = (self._extensions(‘poll‘, namespace, self.conf).extensions for namespace in namespaces) # get the extensions from pollster builder extensions_fb = (self._extensions_from_builder(‘poll‘, namespace) for namespace in namespaces) if pollster_list: extensions = (moves.filter(_match, exts) for exts in extensions) extensions_fb = (moves.filter(_match, exts) for exts in extensions_fb) self.extensions = list(itertools.chain(*list(extensions))) + list( itertools.chain(*list(extensions_fb))) if self.extensions == []: raise EmptyPollstersList() # 加载ceilometer.discover.compute的插件,从setup.cfg中来看只有 # ceilometer.compute.discovery:InstanceDiscovery用来发现宿主机下的云主机 discoveries = (self._extensions(‘discover‘, namespace, self.conf).extensions for namespace in namespaces) self.discoveries = list(itertools.chain(*list(discoveries))) self.polling_periodics = None # 获取一个工作负载分区协调类实例,用来协调多个采集程序worker时的分工处理 self.partition_coordinator = coordination.PartitionCoordinator( self.conf) self.heartbeat_timer = utils.create_periodic( target=self.partition_coordinator.heartbeat, spacing=self.conf.coordination.heartbeat, run_immediately=True) # Compose coordination group prefix. # We‘ll use namespaces as the basement for this partitioning. namespace_prefix = ‘-‘.join(sorted(namespaces)) self.group_prefix = (‘%s-%s‘ % (namespace_prefix, group_prefix) if group_prefix else namespace_prefix) # 从该服务发送出去的消息都会携带ceilometer.polling这个publisher_id # notifier是oslo_messaging/notifier.py的Notifier类实例 # 从配置文件中可以看到默认的driver是messagingv2,对应的是oslo_messageing/notify/messaging.py的MessagingV2Driver类实例 # telemetry_driver = messagingv2 self.notifier = oslo_messaging.Notifier( messaging.get_transport(self.conf), driver=self.conf.publisher_notifier.telemetry_driver, publisher_id="ceilometer.polling") self._keystone = None self._keystone_last_exception = None
这段代码主要做了以下几件事:
(1)从setup.cfg中加载ceilometer.poll.compute对应的采集插件
(2)获取用来发送采集数据样本到消息队列的notifier对象
接着是执行了sm.run()代码,则是调用到了AgentManager类实例的run方法:
File:ceilometer/agent/manager.py:AgentManager.run
def run(self): super(AgentManager, self).run() # 获取polling.yaml文件内容保存到列表中 # 该文件中保存了需要监控的项目,默认设计*所有,但其实是可以自定义下,从而减少监控项,减少不必要的监控项 # 调用ceilometer/pipeline.py的setup_polling函数 self.polling_manager = pipeline.setup_polling(self.conf) self.join_partitioning_groups() # 启动polling采集任务 self.start_polling_tasks() self.init_pipeline_refresh()
这段代码主要功能:
(1)调用setup_polling方法解析/etc/ceilometer/polling.yaml文件,返回一个资源采集列表管理实例(PollingManager类实例),就是把文件定义的要监控的资源信息保存到一个列表(PollingManager类实例的sources列表)中来管理
(2)调用start_pollings_tasks方法启动polling采集任务,调用各插件采集方法进行采集
查看start_pollings_tasks方法实现:
File:ceilometer/agent/manager.py:AgentManager.start_polling_tasks
def start_polling_tasks(self): ...... # 把要监测的资源全加载到polling_tasks中去 # 返回的就是polling_tasks data = self.setup_polling_tasks() # Don‘t start useless threads if no task will run if not data: return # One thread per polling tasks is enough # 对于相同时间间隔的共用一个线程即可 self.polling_periodics = periodics.PeriodicWorker.create( [], executor_factory=lambda: futures.ThreadPoolExecutor(max_workers=len(data))) # 对于每个时间间隔的polling_task都调用一次interval_task执行 # interval_task又调用到了poll_and_notify方法 for interval, polling_task in data.items(): delay_time = (interval + delay_polling_time if delay_start else delay_polling_time) @periodics.periodic(spacing=interval, run_immediately=False) def task(running_task): self.interval_task(running_task) # spawn_thread就是开一个线程,以daemon方式运行 utils.spawn_thread(utils.delayed, delay_time, self.polling_periodics.add, task, polling_task) utils.spawn_thread(self.polling_periodics.start, allow_empty=True)
这段代码主要功能:
(1)调用setup_polling_tasks方法将要监测的资源以时间间隔为分类保存到polling_tasks列表中去,列表中的每一项是一个PollingTask类实例,每个PollingTask里包含了相同采集时间间隔的插件
(2)对于每一个polling_task开启一个线程运行interval_task方法,其中又调用了poll_and_notify方法来轮询每个插件的采集方法并发送
查看poll_and_notify方法实现:
File:ceilometer/agent/manager.py:PollingTask.poll_and_notify
# 将这个时间间隔的polling_task里的插件进行插件里的get_samples调用来采集数据并进行发送 def poll_and_notify(self): """Polling sample and notify.""" ..... # 对于每个source进行轮询 for source_name in self.pollster_matches: # 对于每个插件进行轮询采集 for pollster in self.pollster_matches[source_name]: key = Resources.key(source_name, pollster) candidate_res = list( self.resources[key].get(discovery_cache)) if not candidate_res and pollster.obj.default_discovery: candidate_res = self.manager.discover( [pollster.obj.default_discovery], discovery_cache) # 将要在该插件中采集的资源加入到polling_resources列表中 # 比如对于cpu插件来说,这里的resources单元就是虚拟机 polling_resources = [] ...... try: polling_timestamp = timeutils.utcnow().isoformat() # 调用插件的get_samples方法进行数据采集保存到samples变量中 # 比如当前是采集cpu的插件,则是调用ceilometer.compute.pollsters.cpu:CPUPollster类的get_samples方法 samples = pollster.obj.get_samples( manager=self.manager, cache=cache, resources=polling_resources ) sample_batch = [] for sample in samples: # Note(yuywz): Unify the timestamp of polled samples sample.set_timestamp(polling_timestamp) sample_dict = ( publisher_utils.meter_message_from_counter( sample, self._telemetry_secret )) # 判断是否可以进行批量发送,默认是批量的,可以提高效率 if self._batch: sample_batch.append(sample_dict) else: self._send_notification([sample_dict]) if sample_batch: # 批量发送采集到的数据 self._send_notification(sample_batch) except plugin_base.PollsterPermanentError as err: ...... except Exception as err: ......
这段代码的主要功能:
(1)对每个插件进行轮询调用,通过调用插件的采集方法获取sample数据
(2)通过调用_send_notification方法发送样本数据到消息队列(发送到了notifications.sample队列中)中
查看_send_notification函数实现:
File:ceilometer/agent/manager.py:PollingTask._send_notification
def _send_notification(self, samples): # <class ‘oslo_messaging.notify.notifier.Notifier‘> # ‘telemetry.polling‘是定义了event_type,消息事件类型 self.manager.notifier.sample( {}, ‘telemetry.polling‘, {‘samples‘: samples} )
这里调用到了oslo_messaging库的sample函数里去发送消息,sample方法又调用了_notify方法,该方法对采集数据进行序列化并调用do_notify方法进行发送。
查看do_notify方法实现:
File:oslo_messaging/notify/notifier.py:Notifier.do_notify
def do_notify(ext): try: # oslo_messaging.notify.messaging.MessagingV2Driver ext.obj.notify(ctxt, msg, priority, retry or self.retry) except Exception as e: .....
查看notify实现:
File:oslo_messaging/notify/messaging.py:MessagingV2Driver.notify
def notify(self, ctxt, message, priority, retry): priority = priority.lower() for topic in self.topics: target = oslo_messaging.Target(topic=‘%s.%s‘ % (topic, priority)) try: # 该transport是oslo_messaging/transport.pyTransport实例 # 调用该实例的_send_notification方法其实又调用到它引用的driver的send_notification方法 # 该driver根据配置文件定义是oslo_messaging/_drivers/impl_rabbit.py的RabbitDriver类实例 # 调用了该父类的的send_notification方法进行消息发送 self.transport._send_notification(target, ctxt, message, version=self.version, retry=retry) except Exception: .....
由此采集的数据就发送到消息队列上了,我们再来看下采集插件采集数据的代码,以采集cpu的插件为例。
比如从setup.cfg我们可以看到这个采集插件:
cpu = ceilometer.compute.pollsters.cpu:CPUPollster
找到对应的采集方法(由上面可以知道都会调用插件的get_samples方法):
File:ceilometer.compute.pollsters.cpu:CPUPollster.get_samples
def get_samples(self, manager, cache, resources): for instance in resources: LOG.debug(‘checking instance %s‘, instance.id) try: # inspector是LibvirtInspector类实例 # inspect_cpus方法其实是调用libvirt的接口去获取cpu的 cpu_info = self.inspector.inspect_cpus(instance) LOG.debug("CPUTIME USAGE: %(instance)s %(time)d", {‘instance‘: instance, ‘time‘: cpu_info.time}) cpu_num = {‘cpu_number‘: cpu_info.number} # 将cpu数据封装为一个sample类对象并返回 # ceilometer/sample.py文件的sample类 yield util.make_sample_from_instance( self.conf, instance, name=‘cpu‘, type=sample.TYPE_CUMULATIVE, unit=‘ns‘, volume=cpu_info.time, additional_metadata=cpu_num, monotonic_time=monotonic.monotonic() ) except virt_inspector.InstanceNotFoundException as err: ......
(1)inspector是在加载插件时通过配置文件取得该实例的,该实例是LibvirtInspector类实例
(2)调用该实例方法从而调用到libvirt的api去获取cpu信息
2.2 Ceilometer-agent-notification服务采集数据流程
首先看程序的入口:
File:ceilometer/cmd/notification.py
def main(): conf = service.prepare_service() sm = cotyledon.ServiceManager() # 初始化一个ceilometer/notification.py的NotificationService类实例 sm.add(notification.NotificationService, workers=conf.notification.workers, args=(conf,)) oslo_config_glue.setup(sm, conf) # 执行NotificationService类实例的run方法开始运行 sm.run()
这段代码主要功能:
(1)初始化一个NotificationService类实例,加入管理服务中
(2)调用该实例的run方法启动服务
查看run方法实现:
File:ceilometer/notification.py:NotificationService.run
def run(self): ...... self.pipeline_listener = None # pipeline、tranformer和publisher相关插件加载 # 返回一个PipelineManager类实例 self.pipeline_manager = pipeline.setup_pipeline(self.conf) # 跟setup_pipeline类似 self.event_pipeline_manager = pipeline.setup_event_pipeline(self.conf) # 加载对应的driver实现,这里是oslo_message/_drivers/impl_rabbit.py的RabbitDriver类实现 self.transport = messaging.get_transport(self.conf) # 如果是workload_partitioning设置为true,则需要初始化一个PartitionCoordinator类实例来协调 if self.conf.notification.workload_partitioning: self.group_id = self.NOTIFICATION_NAMESPACE self.partition_coordinator = coordination.PartitionCoordinator( self.conf) # coordinator协调器 self.partition_coordinator.start() else: ...... # 该函数里判断了是否支持工作负载,如果是则返回SamplePipelineTransportManager类实例替换掉 # PipelineManager类实例,否则还是PipelineManager类实例 # 这两者的区别在于publisher函数实现是不一样的 # SamplePipelineTransportManager的在调用publisher函数时会再发到消息队列中去保存,之后会再取出来处理再发到gnocchi-api上 # PipelineManager的则直接去发到gnocchi-api服务上去了 self.pipe_manager = self._get_pipe_manager(self.transport, self.pipeline_manager) self.event_pipe_manager = self._get_event_pipeline_manager( self.transport) # 获取ceilometer.notification的插件,并通过这些插件获取对应的target,再根据targets来找到要监听的 # 队列在上面建立消费者获取消息并处理消息 self._configure_main_queue_listeners(self.pipe_manager, self.event_pipe_manager) if self.conf.notification.workload_partitioning: ....... # configure pipelines after all coordination is configured. with self.coord_lock: # 监听比如ceilometer-pipe-cpu_source:cpu_delta_sink-0.sample这样的队列的消费者 # 因为配置了支持workload_partitioning后,经过转换的消息并没有直接发到gnocchi-api中去,而是 # 分类保存到这些队列里了,再由这些队列接收到消息后再发送出去 self._configure_pipeline_listener() self.init_pipeline_refresh()
这段代码的主要功能:
(1)解析pipeline.yaml配置文件获取监控的项的transforms和publishers,保存到PipelineManager类实例中
(2)调用_get_pipe_manager函数以根据workload_partitioning是否为true获取一个pipe_manager对象,当workload_partitioning为true时是SamplePipelineTransportManager类对象,否则是PipelineManager类对象,区别上面代码注释有说
(3)获取ceilometer.notification的插件,并通过这些插件获取对应的target,并对这些target上的队列创建消费者进行监听
(4)如果workload_partitioning为true,则还需要创建一些监听用于多个agent协作时进行IPC通信的队列
先看setup_event_pipeline函数的实现:
File:ceilometer/pipeline.py
def setup_pipeline(conf, transformer_manager=None): """Setup pipeline manager according to yaml config file.""" # 加载setup.cfg文件中的ceilometer.transformer对应的模块 default = extension.ExtensionManager(‘ceilometer.transformer‘) # 该配置文件对应的是/etc/ceilometer/pipeline.yaml cfg_file = conf.pipeline_cfg_file # SAMPLE_TYPE是一个字典,包含了SamplePipeline、SampleSource和SampleSink等类 # 返回一个PipelineManager实例,该实例管理了SamplePipeline类实例数组,SamplePipeline又是管理了 # SampleSource和SampleSink,用SampleSource中标志的sink来对应SampleSink中具体制定的transform和publisher return PipelineManager(conf, cfg_file, transformer_manager or default, SAMPLE_TYPE)
这段代码主要功能:
(1)加载setup.cfg文件中的ceilometer.transformer对应的模块以用以PipelineManager类实例初始化
(2)初始化PipelineManager类实例
查看初始化PipelineManager类实例代码:
File:ceilometer/pipeline.py:PipelineManager.__init__
class PipelineManager(ConfigManagerBase): def __init__(self, conf, cfg_file, transformer_manager, p_type=SAMPLE_TYPE): ...... # p_type[‘name‘]比如是sample # 这里只是获取一个PublisherManager类实例,还没有进行加载 # 当需要获取时会通过调用该类实例的get方法动态获取对应的publisher publisher_manager = PublisherManager(self.conf, p_type[‘name‘]) unique_names = set() sources = [] # 解析sources,封装为SimpleSource for s in cfg.get(‘sources‘): name = s.get(‘name‘) if name in unique_names: raise PipelineException("Duplicated source names: %s" % name, self) else: unique_names.add(name) # p_type[‘source‘]对应的是SampleSource sources.append(p_type[‘source‘](s)) unique_names.clear() # 解析sinks,封装为SimpleSink sinks = {} for s in cfg.get(‘sinks‘): name = s.get(‘name‘) if name in unique_names: raise PipelineException("Duplicated sink names: %s" % name, self) else: unique_names.add(name) # p_type[‘sink‘]对应的是SampleSink sinks[s[‘name‘]] = p_type[‘sink‘](self.conf, s, transformer_manager, publisher_manager) unique_names.clear() # 将加载的SampleSource和SampleSink封装成SamplePipeline for source in sources: source.check_sinks(sinks) for target in source.sinks: # p_type[‘pipeline‘]对应的是SamplePipeline pipe = p_type[‘pipeline‘](self.conf, source, sinks[target]) if pipe.name in unique_names: raise PipelineException( "Duplicate pipeline name: %s. Ensure pipeline" " names are unique. (name is the source and sink" " names combined)" % pipe.name, cfg) else: unique_names.add(pipe.name) # 所以最后的结果都是保存到self.pipelines里 self.pipelines.append(pipe) unique_names.clear()
可以看到整段代码其实都是在把pipeline.yaml中定义的内容转换成相对应的类,最后封装成SamplePipeline类实例为单元进行保存
再来看run方法中的_get_pipe_manager方法实现:
File:ceilometer/notification.py:NotificationService._get_pipe_manager
def _get_pipe_manager(self, transport, pipeline_manager): if self.conf.notification.workload_partitioning: pipe_manager = pipeline.SamplePipelineTransportManager(self.conf) for pipe in pipeline_manager.pipelines: key = pipeline.get_pipeline_grouping_key(pipe) pipe_manager.add_transporter( (pipe.source.support_meter, key or [‘resource_id‘], self._get_notifiers(transport, pipe))) else: pipe_manager = pipeline_manager return pipe_manager
从这段代码我们可以看出,主要是检测workload_partitioning参数是否设置为true,如果是则重现构建一个SamplePipelineTransportManager类实例并返回,否则还是返回之前的PipelineManager类实例。
这两个类的最大不同之处在于publisher方法实现的不同,查看PipelineManager类实例的publisher方法实现:
File:ceilometer/pipeline.py:PipelineManager.publisher
def publisher(self): return PublishContext(self.pipelines) class PublishContext(object): ..... def __enter__(self): def p(data): for p in self.pipelines: p.publish_data(data) return p .....
File:ceilometer/pipeline.py:SamplePipeline.publish_data
def publish_data(self, samples): ..... supported = [s for s in samples if self.source.support_meter(s.name) and self._validate_volume(s)] # 调用SinkSample类实例的publish_samples方法将监控数据通过_transform_sample处理后发送到gnocchi-api中去 self.sink.publish_samples(supported)
由上面的代码可以看出publisher方法实现就是直接将监控数据通过转换后发送到gnocchi-api服务中去保存
看SamplePipelineTransportManager类实例的publisher方法实现:
File:ceilometer/pipeline.py:SamplePipelineTransportManager.publisher
def publisher(self): ...... class PipelinePublishContext(object): def __enter__(self): def p(data): data = [data] if not isinstance(data, list) else data for datapoint in data: serialized_data = serializer(datapoint) for d_filter, grouping_keys, notifiers in transporters: if d_filter(serialized_data[filter_attr]): key = (hash_grouping(serialized_data, grouping_keys) % len(notifiers)) notifier = notifiers[key] # <class ‘oslo_messaging.notify.notifier.Notifier‘> # 这里的event_type是ceilometer.pipeline,不是ceilometer.polling了 # 发送到类似ceilometer-pipe-xxx_source:xxx_sink-x.sample这样的队列去 notifier.sample({}, event_type=event_type, payload=[serialized_data]) return p def __exit__(self, exc_type, exc_value, traceback): pass return PipelinePublishContext()
由这个方法我们可以看出消息时通过notifier对象发送到其它队列中去的,不是直接发到gnocchi-api中去的,但它会再从对应队列里收集到然后再统一发送到gnocchi-api服务中去。这是因为在run方法中有调用_configure_pipeline_listener方法来创建消费者监听这些队列,并且这些监听的收到消息是调用SamplePipelineEndpoint类的sample方法的,这是由endpoints决定的。可在_configure_pipeline_listener方法中看到endpoints对象的获取代码:
endpoints.append(pipeline.SamplePipelineEndpoint(pipe)),所以在消费者监听到消息进行处理时会回调到该类的sample方法。
查看sample方法:
# 对于类似ceilometer-pipe-cpu_source:cpu_delta_sink-0.sample这样的队列来的消息会调用这里的sample方法进行处理
File:ceilometer/pipeline.py:SamplePipelineEndpoint.sample
def sample(self, messages): ..... with self.publish_context as p: # 这里的p就又回到了ceilometer.pipeline.PipelineManager.publisher.PublishContext.p这个方法了 # 将数据发送到gnocchi-api服务上去 p(sorted(samples, key=methodcaller(‘get_iso_timestamp‘)))
所以这里总结下workload_partitioning如果设置为true,则监控数据在发到gnocchi-api之前多做了层分类处理,将消息根据类型分派到更细分的队列中,方便多个agent协同工作。
接着再看run方法的_configure_main_queue_listeners方法的实现:
File:ceilometer/notification.py:NotificationService._configure_main_queue_listeners
def _configure_main_queue_listeners(self, pipe_manager, event_pipe_manager): # 获取ceilometer.notification命令空间里的插件 notification_manager = self._get_notifications_manager(pipe_manager) ack_on_error = self.conf.notification.ack_on_event_error # 这里的endpoints是很关键的,因为当收到消息进行处理时会分派消息,分派时就是根据消息的类型分派到指定的插件类来处理消息 endpoints = [] endpoints.append( event_endpoint.EventsNotificationEndpoint(event_pipe_manager)) targets = [] for ext in notification_manager: handler = ext.obj # 针对每一个加载的插件获取它们的targets # 其中_sample的target为1个,<Target exchange=ceilometer, topic=notifications> # 比如http.request的则有多个,比如<Target exchange=nova, topic=notifications>,<Target exchange=glance, topic=notifications> for new_tar in handler.get_targets(self.conf): if new_tar not in targets: targets.append(new_tar) # 每个插件的对象实例保存到endpoints endpoints.append(handler) urls = self.conf.notification.messaging_urls or [None] for url in urls: transport = messaging.get_transport(self.conf, url) # 初始化一个solo_messaging/notify/listener.py文件的BatchNotificationServer类实例 listener = messaging.get_batch_notification_listener( transport, targets, endpoints) # 启动监听,创建消费者,绑定收到消息时的回调函数 listener.start() self.listeners.append(listener)
这段代码的主要功能:
(1)获取ceilometer.notification命令空间里的插件对象
(2)从插件对象里获取target
(3)根据获取到的targets创建对应队列的消费者进行监听
这里比较关键的代码是初始化一个listener并调用start方法。
先看get_batch_notification_listener方法实现,该方法又直接调用到oslo_messaging/notify/listener.py的get_batch_notification_listener方法:
File:oslo_messaging/notify/listener.py
def get_batch_notification_listener(transport, targets, endpoints, executor=‘blocking‘, serializer=None, allow_requeue=False, pool=None, batch_size=None, batch_timeout=None): # 初始化一个oslo_messaging/notify/dispatcher.py的BatchNotificationDispatcher类实例 dispatcher = notify_dispatcher.BatchNotificationDispatcher( endpoints, serializer) return BatchNotificationServer( transport, targets, dispatcher, executor, allow_requeue, pool, batch_size, batch_timeout )
这段代码的功能:
(1)初始化一个dispatcher对象,该对象的功能是当接收到消息时将消息分配到对应插件进行处理
(2)初始化BatchNotificationServer类实例并返回该对象
现在看listener调用start方法,调用该start方法主要是调用了_create_listener方法获取PollStyleListenerAdapter类对象并调用start方法启动,查看_create_listener方法的实现:
File:oslo_messaging/notify/listener.py:BatchNotificationServer._create_listene
# 会被start方法调用 def _create_listener(self): return self.transport._listen_for_notifications( self._targets_priorities, self._pool, self._batch_size, self._batch_timeout )
Transport对象其实又是通过driver调用_listen_for_notifications方法:
File:oslo_messaging/_drivers/amqpdriver.py:AMQPDriverBase.listen_for_notifications
def listen_for_notifications(self, targets_and_priorities, pool, batch_size, batch_timeout): conn = self._get_connection(rpc_common.PURPOSE_LISTEN) conn.connection.rabbit_qos_prefetch_count = batch_size listener = AMQPListener(self, conn) # 根据每个target创建对应队列上的消费者 for target, priority in targets_and_priorities: conn.declare_topic_consumer( exchange_name=self._get_exchange(target), topic=‘%s.%s‘ % (target.topic, priority), callback=listener, queue_name=pool) return base.PollStyleListenerAdapter(listener, batch_size, batch_timeout)
这段代码的主要功能:
(1)在要监听的队列上创建消费者进行监听
(2)初始化PollStyleListenerAdapter类实例并返回
PollStyleListenerAdapter类对象初始化时会生成一个线程对象:
File:oslo_messaging/_drivers/base.py:PollStyleListenerAdapter.__init__
self._listen_thread = threading.Thread(target=self._runner)
然后调用start后就会生成一个线程运行_runner函数,该函数主要功能是不断的去获取消息,并通过调用_process_incoming函数来处理消息:
File:oslo_messaging/notify/listener.py:NotificationServer._process_incoming
def _process_incoming(self, incoming): message = incoming[0] try: res = self.dispatcher.dispatch(message) except Exception: ......
可以看到该处理函数会调用dispatcher对象来分派消息,在查看dispatch方法实现前,先来看下该实例初始化时做的事情:
File:oslo_messaging/notifydispatcher.py:NotificationDispatcher
class NotificationDispatcher(dispatcher.DispatcherBase): def __init__(self, endpoints, serializer): # endpoints:Notification插件集合 # 对应ceilometer.notification加载的插件,该插件会接受它对应的消息并进行处理且最后调用publisher将处理后的消息发送出去 self.endpoints = endpoints self.serializer = serializer or msg_serializer.NoOpSerializer() self._callbacks_by_priority = {} for endpoint, prio in itertools.product(endpoints, PRIORITIES): if hasattr(endpoint, prio): # 这里的方法就是sample、info、debug等,在ceilometer/agent/plugin_base.py中的NotificationBase类都会对应名字的方法实现 # 注意了如果是ceilometer-pipe-cpu_source:cpu_delta_sink-0.sample类似这些队列来的则处理函数就不是sample、info、debug那些了 # 而是SamplePipelineEndpoint类的sample方法了,因为endpoints不一样了 method = getattr(endpoint, prio) screen = getattr(endpoint, ‘filter_rule‘, None) self._callbacks_by_priority.setdefault(prio, []).append( (screen, method))
这段代码的主要功能是初始化_callbacks_by_priority字典对象,使得可以根据消息类型找到对应的插件进行对应方法的调用。
现在看dispatch方法实现:
File:oslo_messaging/notify/dispatcher.py:NotificationDispatcher.dispatch
def dispatch(self, incoming): """Dispatch notification messages to the appropriate endpoint method. """ # 将资源分配到合理的处理插件上去处理消息 priority, raw_message, message = self._extract_user_message(incoming) if priority not in PRIORITIES: LOG.warning(_LW(‘Unknown priority "%s"‘), priority) return for screen, callback in self._callbacks_by_priority.get(priority, []): if screen and not screen.match(message["ctxt"], message["publisher_id"], message["event_type"], message["metadata"], message["payload"]): continue ret = self._exec_callback(callback, message) if ret == NotificationResult.REQUEUE: return ret return NotificationResult.HANDLED
这里重点看通过消息的priority字段查找self._callbacks_by_priority字典里匹配的插件的对应方法,也即是获取到callback函数,然后进行调用。
举例子:比如notifications.sample上的消息会匹配到TelemetryIpc类的sample方法去处理
_sample = ceilometer.telemetry.notifications:TelemetryIpc
但该类实例是调用了它父类的sample方法:
File:ceilometer/agent/plugin_base.py:NotificationBase.sample
def sample(self, notifications): self._process_notifications(‘sample‘, notifications) _process_notifications方法又调用了to_samples_and_publish方法: File:ceilometer/agent/plugin_base.py:NotificationBase.to_samples_and_publish def to_samples_and_publish(self, notification): with self.manager.publisher() as p: # 这里处理好的sample的格式类似于 # <name: bandwidth, volume: 252, resource_id: a16d3949-29a6-4d88-b9a1-c7fdc97d0e4f, timestamp: 2019-07-04 03:02:25.181893> # p是ceilometer.pipeline.SamplePipelineTransportManager.publisher.PipelinePublishContext.p方法,这个会再发到消息队列上去 # 如类似ceilometer-pipe-cpu_source:cpu_delta_sink-0.sample这种队列 # 如果workload_partitioning设置为false则调用的是ceilometer.pipeline.PipelineManager.publisher.PublishContext.p方法,这个是 # 直接发送gnocchi-api上去的 # 这个process_notification是调用对应的插件的process_notification方法对监控数据进行处理 p(list(self.process_notification(notification)))
接着我们查看调用p函数的实现:
File:ceilometer/pipeline.py:PublishContext.__enter__.p
def p(data): for p in self.pipelines: p.publish_data(data)
查看publish_data实现:
File:ceilometer/pipeline.py:SamplePipeline.publish_data
def publish_data(self, samples): ...... # 调用SampleSink类实例的publish_samples方法将监控数据通过_transform_sample处理后发送到gnocchi-api中去 self.sink.publish_samples(supported)
这个sink对象是之前解析pipeline.yaml文件后每种类型资源生成的SampleSink类对象,publish_samples又调用了_publish_samples方法:
File:ceilometer/pipeline.py:SampleSink._publish_samples
def _publish_samples(self, start, samples): transformed_samples = [] if not self.transformers: transformed_samples = samples else: for sample in samples: sample = self._transform_sample(start, sample) if sample: transformed_samples.append(sample) if transformed_samples: # 配置文件配的是gnocchi,根据setup.cfg中的指定 # gnocchi = ceilometer.publisher.direct:DirectPublisher # 所以这里其实是调用到ceilometer/publisher/direct.py文件的DirectPublisher类实例的publish_samples方法 for p in self.publishers: try: # 所以这里其实是调用到ceilometer/publisher/direct.py文件的DirectPublisher类实例的publish_samples方法 p.publish_samples(transformed_samples) except Exception: .....
这段代码的主要功能是:
(1)调用对应的transform插件对samples数据进行转换处理
(2)将转换后的数据通过publisher插件发送出去
查看DirectPublisher类实例的publish_samples方法:
File:ceilometer/publisher/direct.py:DirectPublisher.publish_samples
def publish_samples(self, samples): ..... # 这里是调用到ceilometer/dipatcher/gnocchi.py里的record_metering_data self.get_sample_dispatcher().record_metering_data([ utils.meter_message_from_counter(sample, secret=None) for sample in samples])
查看record_metering_data方法实现:
File:ceilometer/dispatcher/gnocchi.py:GnocchiDispatcher.record_metering_data
# 将sample进行加工后发送到gnocchi中去 def record_metering_data(self, data): # 处理data ....... try: # 连接gnocchiclient发送数据到gnocchi中去保存数据 self.batch_measures(measures, gnocchi_data, stats) except (gnocchi_exc.ClientException, ka_exceptions.ConnectFailure) as e: ......
查看batch_measures方法实现:
def batch_measures(self, measures, resource_infos, stats): try: # 调用gnocchiclient/v1/metric.py的batch_resources_metrics_measures方法发起http的post请求 self._gnocchi.metric.batch_resources_metrics_measures( measures, create_metrics=True) except gnocchi_exc.BadRequest as e: ......
这里发送出去后,数据流就到达到gnocchi-api服务上了,交由gnocchi服务来进行计算处理和存储
2.3 Gnocchi-api服务接收数据流程
该服务现在在比较新的版本中默认配置为是由httpd服务拉起的,拉起时执行的代码:
File:gnocchi/rest/app.wsgi
from gnocchi.rest import app application = app.build_wsgi_app()
build_wsgi_app又调用了load_app函数:
File:gnocchi/rest/app.py
def load_app(conf, indexer=None, storage=None, not_implemented_middleware=True): global APPCONFIGS # NOTE(sileht): We load config, storage and indexer, # so all if not storage: storage = gnocchi_storage.get_driver(conf) if not indexer: indexer = gnocchi_indexer.get_driver(conf) indexer.connect() # Build the WSGI app cfg_path = conf.api.paste_config if not os.path.isabs(cfg_path): cfg_path = conf.find_file(cfg_path) if cfg_path is None or not os.path.exists(cfg_path): raise cfg.ConfigFilesNotFoundError([conf.api.paste_config]) config = dict(conf=conf, indexer=indexer, storage=storage, not_implemented_middleware=not_implemented_middleware) configkey = str(uuid.uuid4()) APPCONFIGS[configkey] = config LOG.info("WSGI config used: %s", cfg_path) appname = "gnocchi+" + conf.api.auth_mode app = deploy.loadapp("config:" + cfg_path, name=appname, global_conf={‘configkey‘: configkey}) return cors.CORS(app, conf=conf)
这段代码的主要功能:
(1)根据配置文件加载对应存储driver插件,对应的是measure storage和Index的插件
(2)建立api服务并运行起来,是使用pecan框架进行建立的
我们这里看一个接收采集数据的过程,数据是从notification-polling->notification-agent-notification->gnocchiclient->gnocchi-api的。
我们看下在gnocchiclient这边的发送数据代码逻辑:
File:gnocchiclient/v1/metric.py:MetricManager. batch_resources_metrics_measures
def batch_resources_metrics_measures(self, measures, create_metrics=False): # v1/batch/resources/metrics/measures # 对应gnocchi服务的pecan url路径查找可知识调用了gnocchi/rest/__init__.py的ResourcesMetricsMeasuresBatchController类的post方法 return self._post( self.resources_batch_url, headers={‘Content-Type‘: "application/json"}, data=jsonutils.dumps(measures), params=dict(create_metrics=create_metrics))
可以看到是通过post的方式发送一个http的请求到gnocchi-api服务的,这里关键的是看url路径,可以通过该url路径找到在gnocchi-api对应的接收方法,这里我们按照pecan框架的路径查找方法找到了是在gnocchi/rest/__init__.py的ResourcesMetricsMeasuresBatchController类的post方法:
File:gnocchi/rest/__init__.py:ResourcesMetricsMeasuresBatchController.post
class ResourcesMetricsMeasuresBatchController(rest.RestController): @pecan.expose(‘json‘) def post(self, create_metrics=False): # 判断该监控名字是否已存在和封装数据等逻辑 ...... # 保存监控数据,等待gnocchi-metricd服务对它异步处理 # pecan.request.storage这个对象是<class ‘gnocchi.storage.ceph.CephStorage‘> # pecan.request.storage.incoming这个是<class ‘gnocchi.storage.incoming.file.FileStorage‘> # 这个应该就是我们配置文件中配置的临时的先放file里(可查看配置文件的[incoming]项,存到/var/lib/gnocchi/该目录下),最终的聚合计算后的数据放ceph里 pecan.request.storage.incoming.add_measures_batch( dict((metric, body_by_rid[metric.resource_id][metric.name]) for metric in known_metrics)) ....
add_measures_batch方法通过格式化数据后调用_store_new_measures方法来保存:
File:gnocchi/storage/incoming/file.py:FileStorage._store_new_measures
def _store_new_measures(self, metric, data): tmpfile = tempfile.NamedTemporaryFile( prefix=‘gnocchi‘, dir=self.basepath_tmp, delete=False) tmpfile.write(data) tmpfile.close() # 这个目录下/var/lib/gnocchi/ path = self._build_measure_path(metric.id, True) while True: try: os.rename(tmpfile.name, path) break except OSError as e: ......
2.4 Gnocchi-metricd服务存储数据流程
首先看该服务的程序入口:
File:gnocchi/cli.py
# 程序启动时入口点 def metricd(): conf = cfg.ConfigOpts() conf.register_cli_opts([ cfg.IntOpt("stop-after-processing-metrics", default=0, min=0, help="Number of metrics to process without workers, " "for testing purpose"), ]) conf = service.prepare_service(conf=conf) if conf.stop_after_processing_metrics: metricd_tester(conf) else: MetricdServiceManager(conf).run()
入口代码的关键代码在于最后一行的MetricdServiceManager类初始化和调用run方法开始运行服务。
我们先看MetricdServiceManager类初始化:
File:gnocchi/cli.py:MetricdServiceManager
class MetricdServiceManager(cotyledon.ServiceManager): def __init__(self, conf): super(MetricdServiceManager, self).__init__() oslo_config_glue.setup(self, conf) self.conf = conf self.queue = multiprocessing.Manager().Queue() # 从measure storage中取出监控数据存放到queue队列中 self.add(MetricScheduler, args=(self.conf, self.queue)) # 不断的从queue队列中获取数据并进行聚合计算并保存到aggregate storage中去 self.metric_processor_id = self.add( MetricProcessor, args=(self.conf, self.queue), workers=conf.metricd.workers) if self.conf.metricd.metric_reporting_delay >= 0: self.add(MetricReporting, args=(self.conf,)) # 用来删除在index数据库中资源标志为delete的监控数据 self.add(MetricJanitor, args=(self.conf,)) self.register_hooks(on_reload=self.on_reload)
这段代码的主要功能:
(1)获取一个queue对象用于保存从measure storage取出的监控数据
(2)初始化一个MetricScheduler类实例并添加到待启动功能对象中,运行服务后会开启线程不断的调用该对象的_run_job方法以不断的从measure storage中取出数据放到queue队列中
(3)初始化一个MetricProcessor类实例并添加到待启动功能对象中,运行服务后开启线程不断的调用该对象的_run_job方法以不断的从queue取出数据根据聚合计算规则进行计算并将结果存储到aggregate storage中
(4)MetricReporting类添加流程类似如上,它的作用是报告measure storage中有多少条待处理数据需要处理
(5)MetricJanitor类添加流程如上,它的作用是删除在index数据库中资源标志为delete的监控数据,比如删除掉measure storage已经处理过的数据或者aggregate storage中已经过期的数据
初始化完后就会调用run方法把上面添加好的功能类都运行起来,从而整个处理流程就跑起来了:
def run(self): # run方法会一直运行 super(MetricdServiceManager, self).run() # 在程序结束或停止时关闭queue self.queue.close()
标签:== reporting 分区 exception lis appname lob txt workload
原文地址:https://www.cnblogs.com/luohaixian/p/11145939.html