标签:行存储 edit ima 访问量 了解 原因 秘书 解决 数据处理
记得从上大学的时候就已经听说过这个词语 以前的理解可能就是数据量超大很多嘛 到这几年大数据这个词语被人们谈论得也越来越频繁 也越来越想了解它的所以自己才会去学习 我觉得做任何事之前肯定有某种驱使你去了解它的过程 以下仅是自己个人的理解
大数据不仅是数据量大 (G,TB,PB.....)达到甚至更大 ,试想一下我给你一个数据量达到TB级别的数据 但是里面的数据都是一些你看不懂或者没有什么可用的信息的 那它也不过是一个数据量很大的文件而已(仅此而已没有什么可以提供的价值信息) ,所以说大数据不仅是拥有海量的数据而且是多维度的(能够获取到很多有价值的信息)我们经常会把数据存放到硬盘 硬盘大嘛可以存放几百G的容量 但是我们的大数据就不行了 因为大数据的数据量是庞大的是你都无法想象的(有时候会在脑海里想想 全世界有接近70多亿的人口说全世界可能范围太大 就单单一个中国13亿人每天产生的数据量就大的惊人)这么大的数据量怎么可能去存放到硬盘里呢(在多弄几台电脑不就行了 几台不行在搞个几十台当初就是这么想的) 这时候我们的大数据就派上用场了
大数据的核心是解决海量数据 场景下的数据存储加运算问题(拿到数据后肯定会进行一些计算然后提取到我们所需要的信息) 而海量数据 场景下的数据存储加运算问题的核心又是分布式技术
我们经常会上网购物 淘宝天猫京东呀 每次只要搜索的时候一件物品(比如电脑)那么下次再进来的时候你就会发现很多有关电脑的购物信息 当我选择一件物品进入到购物车 就会立即跟我推荐很多跟我购物车相关的物品 以前可能回想这是怎么回事 为什么不推荐其他的物品呢 现在可能有了一些些了解
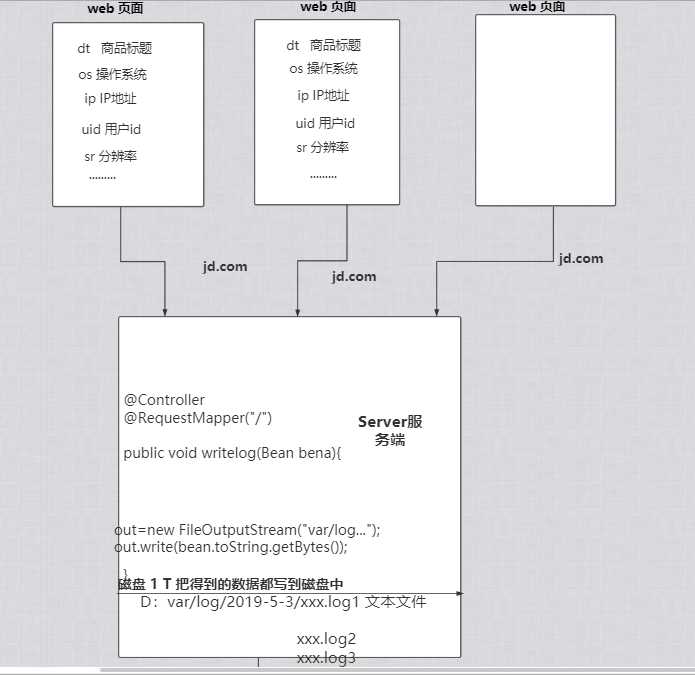
首先当我们访问一个页面的时候 例如京东的网站 每当我们在浏览一个页面点击每一件商品的时候 会像服务端server发送很多信息 (商品标题 ip地址 用户id.......)都会发到server 服务端收到信息之后 就会把这些信息获取到然后保存到硬盘中 相当一个日志吧 每天都会存放一些信息 并且会不断的更新数据会越来越大必须做一些处理 那么问题也就来了
Q1:试想以下像京东天猫每天同时浏览人数没有上亿也有好几千万的访问量 ,假如一个人访问数据量为几k 一天总共请求的数据也有百g了 如果一个月 一年 那么数据就会越来越大那么它的数据又是如何保存的呢?
如果用硬盘存放肯定不现实 而京东(不止是京东 天猫 谷歌 阿里)也是运用了分布式文件存储系统(HDFS) 将数据存放到多台服务器上面 然后进行数据操作
1.HDFS是做什么的?
HDFS分布式计算中数据存储管理的基础 是用来存储超大数据文件的系统
2.HDFS有什么优点为什么这么多公司会用?
(1)高容错性
数据自动保存多个副本 当一个副本丢失会自动恢复
(2)适合大数据处理
1) 数据规模:能够处理数据规模达到 GB、TB、甚至PB级别的数据。
2) 文件规模:能够处理百万规模以上的文件数量,数量相当之大。
(3) 流式数据访问
1) 一次写入,多次读取,不能修改,只能追加。
2) 它能保证数据的一致性。
(4) 可构建在廉价机器上
1) 它通过多副本机制,提高可靠性。
2) 它提供了容错和恢复机制。比如某一个副本丢失,可以通过其它副本来恢复。
(5) 适合批处理
1) 它是通过移动计算而不是移动数据。
2) 它会把数据位置暴露给计算框架。
3.HDFS如何存储数据?
(1) 我们要想知道HDFS如何存储数据 就必须先了解到HDFS Client、NameNode、DataNode和Secondary NameNode
1) HDFS Cilent hdfs客户端
文件上传到HDFS的时候 会将文件进行分块 然后再进行存储
与NameNode交互 获取到文件的位置信息 NameNode管理DataNode 应该将文件存储到哪个节点
与DataNode交互 存储获读取数据
Client 提供一些命令来管理 HDFS,比如启动或者关闭HDFS。
2)NameNode
处理客户端的请求
管理数据块的信息
管理DataNode
3)DataNode
是真正干事的节点 它负责存储数据
4)Secondary NameNode
辅助 NameNode,分担其工作量(有点像秘书的角色) 但是当NameNode挂掉的时候 它并不能马上替换 NameNode 并提供服务
定期合并 fsimage和fsedits,并推送给NameNode。
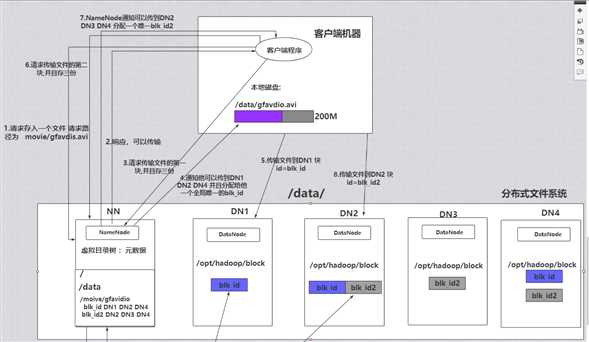
1 当客户端发送一个请求说有一个文件需要存储(gfvadio.avi)
2.NameNode会接收到这个请求 并且会在虚拟目录树下面找是否有这个文件 如果有就响应可以传输
3.然后客户端就会去传输数据(并且会分块传输 默认是128M是一块 而我要传输的文件是200M 它会分为两块去传) 并且会保存三份副本 以免数据丢失
4.NameNode通知客户端可以将数据传到 DN1 DN2 DN4 并且会给它分配一个全局唯一的blk_id
5.客户端收到消息后就会将文件传到DN1 DN2 DN4 第一块传输完成
6.客户端请求传输文件的第二块 并且也保存三份 接着NameNode通知可以将文件传到DN2 DN3 DN4 并且会分配给它一个布局唯一的blk_id2
7.客户端收到消息后传输文件到DN2 DN3 DN4 存储完成
至于为什么HDFS会这么存储数据 肯定是有它的道理的 接下来这几个问题问题也许可以解决这个疑问
Q2:如果多个客户端传输同一个文件名 可能造成什么后果?
之前的数据肯定会被覆盖 数据丢失 正是因为这个原因所以在传输文件的时候NameNode会分配一个全局唯一的编号
Q3:如果客户端传输一个超大文件100G会发生什么?
100G的数据读起来肯定非常慢 所以会分块 每个机器读取不同的块 可以大大增加读取效率
Q4:传输数据的时候数据存储服务器挂掉(如果DN1,DN2 )了会发生什么?
这里就可以解决为什么会备份副本 传输文件的时候会备份多份 这样可以防止某台服务器突然挂掉 数据出现丢失的情况
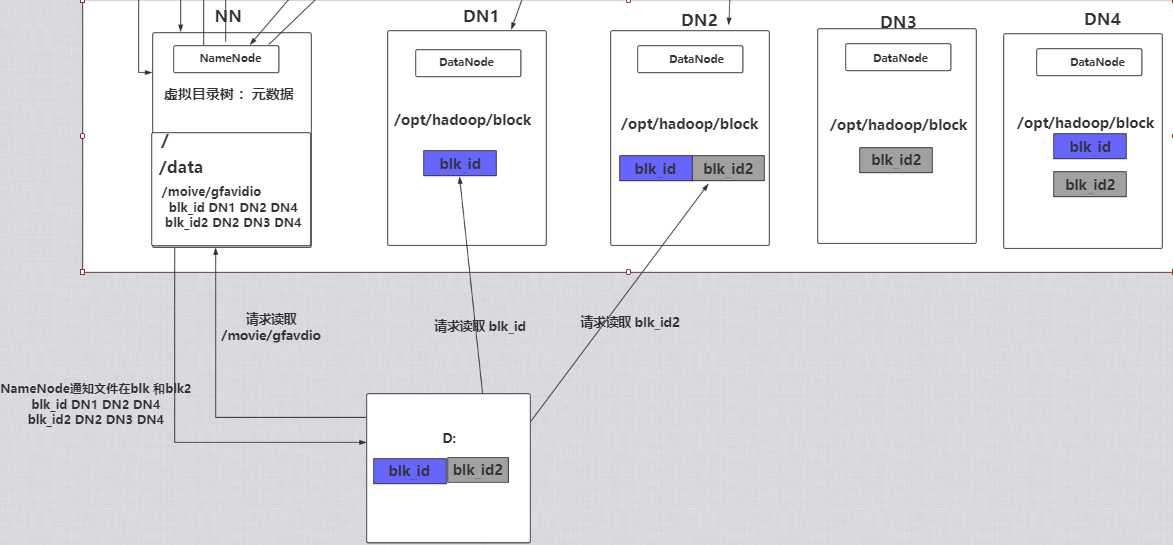
1.客户端发送请求读取数据
2.NameNode会在元数据中查找是否存在这个文件 如果存在 然后就会通知客户端blk_id在DN1 blk_id2在DN2
3.客户端然后再去DN1中取第一块数据 取完之后再在DN2中取第二块
标签:行存储 edit ima 访问量 了解 原因 秘书 解决 数据处理
原文地址:https://www.cnblogs.com/hengly/p/11147425.html