标签:影响 形式 编译型 如何 哥德巴赫猜想 oca 为我 print 相同
1、
def f(x,l=[]): for i in range(x): l.append(i*i) print(l) f(2) f(3,[3,2,1]) f(3)
考查知识点:列表,深浅copy。弄清楚就ok
[0, 1] [3, 2, 1, 0, 1, 4] [0, 1, 0, 1, 4]
2、
用python , 123456789变成987654321‘
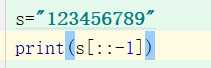
太简单
考查知识点:切片
3、
python 的re模块中match() search()findall() compile()的区别
match与search函数功能一样,match匹配字符串开始的第一个位置,search是在字符串全局匹配第一个符合规则的。
简单来说就是:
re.match与re.search的区别:re.match只匹配字符串的开始,
如果字符串开始不符合正则表达式,则匹配失败,函数返回None;
而re.search匹配整个字符串,直到找到一个匹配。
re.findall函数返回的总是正则表达式在字符串中所有匹配结果的列表list,此处主要讨论列表中“结果”的展现方式,即findall中返回列表中每个元素包含的信息。
使用re的一般步骤是先使用re.compile()函数,将正则表达式的字符串形式编译为Pattern实例,
然后使用Pattern实例处理文本并获得匹配结果(一个Match实例),最后使用Match实例获得信息,进行其他的操作。
4、a/b/.././c/QN1UH78VKP2T7)IA]ZM(FW.gif) test.jpg变成a/c/test.jpg
test.jpg变成a/c/test.jpg
为上一级为本级
稍微欠缺的方法,这个写死了:
s="a/b/.././c/test.jpg" s1=s.split("/") s1.pop(s1.index("..")-1) s1.pop(s1.index("..")) s1.pop(s1.index(".")) l = [] for i in s1: l.append(i) print("/".join(l))
正常思路:
s="a/b/.././c/test.jpg" s1=s.split("/") l = [] for i in s1: if i == "..": l.pop() elif i == ".": continue else: l.append(i) print("/".join(l))
考查知识点:列表的几个常用方法
99乘法表
for x in range(1, 10): for y in range(1, x+1): print("%s*%s=%s" % (y, x, x * y), end=‘ ‘) print() # print默认参数‘换行’,没有此条语句输出打印时将不会换行
一行代码实现:
print(‘\n‘.join([‘ ‘.join([‘{}*{}={}‘.format(y,x,y*x) for y in range(1, x+1)]) for x in range(1,10)]))
6、
找到1000以内的龙腾数,各个位数的和为5的数为龙腾数
for i in range(1000): a = i // 100 # 获得百位上的数字 b = i // 10 % 10 # 获得十位数的数字 c = i % 10 # 获得个位数的数字 if a + b + c == 5: print(i)
主要思路:怎么获取百位数字,用这个数整除100就会得到百位上的数字
怎么获取十位数字,用这个数整除10再对10取余,就会得到十位上的数字
怎么获取个位上的数字,用这个数对10取余就会得到个位上的数字
7、
python给一个有序列表,求出插入值的索引
def index(nlist, k): if k < nlist[0]: # 假如插入的元素比第一个元素小,则就直接插在第一个元素的位置,第一个元素的索引是0 p = 0 elif k > nlist[-1]: # 假如插入的元素比最后一个元素大,则就直接插在最后元素的位置,最后一个元素的索引为len(l)-1 p = len(nlist) - 1 else: p = 0 # p=0归位 for item in nlist: # 然后对传过来的列表进行循环打印 if k < item: # 判断插入的元素的大小 break # 直到插入的元素大于item了 p += 1 return p lis = [1, 3, 5, 7, 8, 9, 11] result = index(lis, 10) print(result)
8、
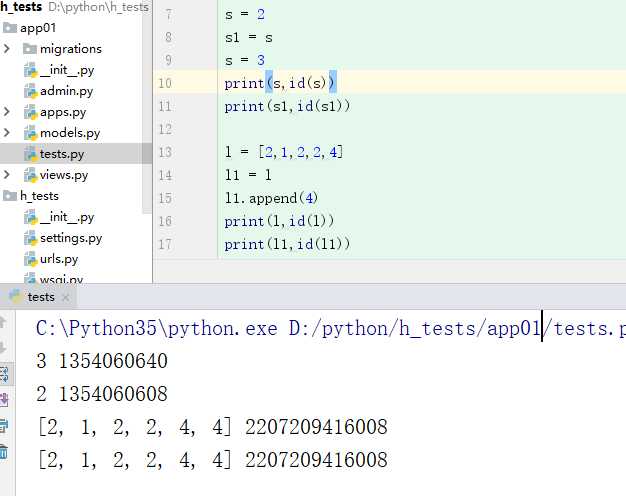
赋值是指向同一个对象吗
在python中,对象的赋值就是简单的对象引用
赋值操作(包括对象作为参数、返回值)不会开辟新的内存空间,它只是复制了新对象的引用。也就是说,除了list_b这个名字以外,没有其它的内存开销。
浅拷贝会创建新对象,其内容是原对象的引用。
深拷贝:和浅拷贝对应,深拷贝拷贝了对象的所有元素,包括多层嵌套的元素。因而,它的时间和空间开销要高。
总结:赋值是指的同一个对象。
深浅拷贝都是创建了新对象。
赋值就是内存地址给另外一个被赋值的变量。
浅copy是第一层复制,创建新的内存地址,二层以上的内存地址不变。
深copy是完全复制,创建新的对象,跟被copy的对象没有联系
9、
s1="aabacbcccab"输出连续的最多的那个数
s1="aabacbcccab" li = [] count = 0 for i in list(s1): if not li: li.append(i) elif li[0] == i: li.append(i) if count < len(li): s = li[-1] count = len(li) else: li = [] li.append(i) print(count, s)
10、
s=["a","b","c","d","e","f"] s[1:5:1]=s[-2:0:-1] print(s)
11、
题目:计算字符串倒数第二个单词的长度,单词以空格隔开。输入一行字符串,非空,长度小于2000。 最后给出一个整数N,即倒数第二个单词的长度。
示例 :
输入:hello my world
输出:2
s = input("请输入一个字符串:") len = len(s.split()[-2:][0]) print(len)
12、
哥德巴赫猜想:任一大于2的偶数都可写成两个质数之和,验证输入一个偶数,将所有的符合条件的等式输出,如下所示
请输入一个任意的偶数:22
22=3+19
22=5+17
22=11+11
import math def isEven(num): # 判断是否是偶数 if num % 2 == 0: return True else: return False def isPrime(n): #判断素数 if n == 1: return False elif n == 2: return True else: for i in range(2,int(math.sqrt(n)+1)): if n%i == 0: return False return True def isNum(string): # 判断是否是数值 if string.isdigit(): return True else: return False respone = input(‘请输入一个大于2的偶数:‘) if isNum(respone): #判断输入是否为整数 respone = int(respone) #判断是否是大于2的偶数 if (respone > 2) and isEven(respone): #进行猜想判断 i_list = [] for i in range(1,respone): j = respone - i #分解为两个数字 # print(j,i) if isPrime(i) and isPrime(j): i_list.append(i) #记录已显示的数字 # print(i_list) if j in i_list and j != i: pass else: print(‘{0} = {1} + {2}‘.format(respone, i, j)) else: print(‘输入错误!‘) else: print(‘输入错误!‘)
13.
下面那个语句Python中是非法的
A、x=y=z=1 B、x=(y=z+1) C、x,y=y,x D、x + =y
答案:B 原因:因为将 x = (y = z + 1) 中右半部分括起来后,相当于把一个赋值表达式赋值给变量 x,因此出现语法错误。等号右边是不能赋值的。 其实把x = (y = z + 1) 改为x = y = z + 1 这样是正确的 这才是正确的赋值语句,这种赋值方式可称为 连续赋值、批量赋值、多元赋值、多变量赋值 等
14、关于python内存管理,下列说法错误的是
A、变量不必事先声明 B、变量无须先创建和赋值而直接使用 C、变量无须指定类型 D、可以使用del释放资源
答案:B 原因:变量如果不赋值的话,会报错。is not defined
15、下面哪个不是Python合法的标识符
A、int32 B、40XL C、self D、name
变量的规则:变量名只能是字母,数字或者下划线的任意组合
但是变量名的第一个字符不能是数字
16、下列哪种说法是错误的
A、除字典类型外,所有标准对象均可以用于布尔测试
B、空字符串的布尔值是False
C、空列表对象的布尔值是False
D、值为0的任何数字对象的布尔值是False
空字符串或空列表等不代表值为0,值为0是a=0,BOOL为TRUe
17、下列表达式的值为True的是
A、5+4j >2-3j B、3>2>2
C、(3,2)<(‘a‘,‘b‘) D、’abc’ > ‘xyz’ # abc<xyz
C (在Py2.x版本中正确,在Py3.x运行错误)
18、Python不支持的数据类型有
A、char B、int C、float D、list
答案:A(python里无char型数据,有string字符串类型;但C语言中有char数据类型)

19、关于Python中的复数,下列说法错误的是
A、表示复数的语法是real + imagej B、实部和虚部都是浮点数
C、虚部必须后缀j,且必须是小写 D、方法conjugate返回复数的共轭复数
C(复数虚部的后缀也可以是大写的J)
20、关于字符串下列说法错误的是
A、字符应该视为长度为1的字符串
B、字符串以\0标志字符串的结束
C、既可以用单引号,也可以用双引号创建字符串
D、在三引号字符串中可以包含换行回车等特殊字符
python因为字符串有长度限制,到了长度就标志字符串的结束
21、以下不能创建一个字典的语句是
A、dict1 = {} B、dict2 = { 3 : 5 }
C、dict3 ={[1,2,3]: “uestc”} D、dict4 = {(1,2,3): “uestc”}
C(字典的键必须是不变的,而列表是可变的)


可变数据类型如果改变值的话,其中内存地址是不变的,所以可以任意的修改里边的值,这就是可变数据类型
不可变数据类型就是如果改变值的话,内存地址也会改变。
例如:
22、下列Python语句正确的是:
A、min = x if x< y = y
B、max = x > y ?x:y
C、if (x >y) print x
D、while True :pass
23、在(etc/ftab 文件中指定的文件系统加载参数中,以下参数般用于 CD-ROM等移动设备的是
A、defaults B、sW C、rw和ro D、noauto
参数 default表示和使用默认设置
sw 表示自动挂载的可读写分区
ro 表示挂载只读权限的
rw 表示挂载读写权限的
所以选择D。表示手动挂载的,也用于CD-ROW等移动设备
24、Linux文件权限一共10位长度,分成四段,第三段表示的内容是()。
- rwx rwx rwx
类型 用户权限 用户所在组权限 其他用户权限
25、__new__和__init__有什么区别
__init__实际上不能算得上的构造函数,__new__才能创建实例的方法。 __init__是当实例对象创建完成后被调用的,然后设置对象属性的一些初始值。 __new__是在实例创建之前被调用的,因为他的任务就是创建实例然后返回该实例,是个静态方法。 也就是__new__是在__init__之前被调用的,__new__的返回值(实例)将传递给__init__方法的第一个参数,然后__init__给这个实例设置一些参数

26、python是解释型语言吗?会编译吗?pyc文件是什么?
Python是一门解释性语言,直到发现了*.pyc文件的存在。如果是解释型语言,那么生成的pyc文件又是什么?
编译型语言在程序执行之前,先会通过编译器对程序执行一个编译的过程,把程序转变成机器语言。运行时就不需要翻译,而直接执行就可以了。最典型的例子就是C语言。
解释型语言就没有这个编译的过程,而是在程序运行的时候,通过解释器对程序逐行作出解释,然后直接运行,最典型的例子是Ruby。
但是我们也不能一概而论,一些解释型语言也可以通过解释器的优化来在对程序做出翻译时对整个程序做出优化,从而在效率上超过编译型语言。
在程序运行期间,编译结果存在于内存的PyCodeObject对象中,当Python结束运行后,编译结果会被保存到pyc文件中,
在下一次运行相同程序时,Python会根据pyc文件中记录的编译结果直接在内存中重新建立PyCodeObject对象,而不用再次对源文件进行编译。
PyCodeObject结构体在C源代码中有相应的声明,Python的import机制会触发pyc文件的生成,
实际这不是生成pyc文件的唯一姿势。我们可以通过compile内建函数来查看这个PyCodeObject对象的一些信息
pyc文件是导包或者是引用的时候产生的,举个例子我有一个b.py文件,我从a.py中引用b.py文件,执行a.py文件时,就会产生b.py文件的pyc文件,
这个pyc文件是字节码文件。当再次运行a.py时,如果a.py没有发生变化,则运行pyc文件,当a.py发生变化时,就会重新生成pyc文件,然后在执行pyc文件。
pyc文件是再次转化成机器码才执行的。
还有那个正在运行的py文件,在未运行的代码处修改时不会执行的,也就是运行原代码,原因是代码是加载到内存中执行的,你手动修改时只是在硬盘中的。
27、生成器、迭代器的区别
可以被迭代要满足的要求就叫做可迭代协议。可迭代协议的定义非常简单,就是内部实现了__iter__方法。
可以被for循环的都是可迭代的,要想可迭代,内部必须有一个__iter__方法。
迭代器遵循迭代器协议:必须拥有__iter__方法和__next__方法。
我们知道的迭代器有两种:一种是调用方法直接返回的,一种是可迭代对象通过执行iter方法得到的,迭代器有的好处是可以节省内存。
如果在某些情况下,我们也需要节省内存,就只能自己写。我们自己写的这个能实现迭代器功能的东西就叫生成器。
yield可以为我们从函数中返回值,但是yield又不同于return,return的执行意味着程序的结束,
调用生成器函数不会得到返回的具体的值,而是得到一个可迭代的对象。每一次获取这个可迭代对象的值,就能推动函数的执行,获取新的返回值。直到函数执行结束。
import time def func1(): a=1 print("a变量") yield a b=2 print("b变量") yield b g1=func1() print(g1) print(next(g1)) # next一次,取出来一次值 print(next(g1)) # 再next一次,再取值
def func(): print(123) content = yield 1 print("——",content) print(333) yield 2 g = func() # ret = g.__next__() # print("****",ret) print(next(g)) ret = g.send("hh") #send的效果和next一样 print(ret) #send 获取下一个值的效果和next基本一致 #只是在获取下一个值的时候,给上一yield的位置传递一个数据 #使用send的注意事项 # 第一次使用生成器的时候 是用next获取下一个值 # 最后一个yield不能接受外部的值
#列表解析 sum([i for i in range(100000000)])#内存占用大,机器容易卡死 #生成器表达式 sum(i for i in range(100000000))#几乎不占内存
使用生成器的优点:
1.延迟计算,一次返回一个结果。也就是说,它不会一次生成所有的结果,这对于大数据量处理,将会非常有用。
2.提高代码可读性
28、@classmethod和@staticmethod的区别
@classmethod和@staticmethod都可以不实例化类而直接使用类名.类方法名()的方式进行调用,二者都是修饰方式。
区别就是当基类被删除时,再次使用@staticmethod方式进行调用时,会报错;但是@classmethod不会受到影响。可以继续使用。
@classmethod和@staticmethod都不需要再传入self,但是@classmethod装饰的函数第一位必须传入一个参数,
多用cls,这个cls则代表当前的类。其他参数则看自己的使用情况进行传参。
class A(object): a = "哈哈哈" def b(self): return self.a @staticmethod def c(): return A.a @classmethod def d(cls): return cls.a class B(A): pass print(A.a) print(A.b()) # 报错 必须实例化类才可以 print(A.c()) print(A.d()) del A # print(B.a) print(B.b()) # 报错 必须实例化类 print(B.c()) #报错 A not defined print(B.d())
29、判断回文多种方式
# 方法一:递归切片 def is_huiwen(s): if len(s) < 2: return True if s[0] == s[-1]: return is_huiwen(s[1:-1]) else: return False print(is_huiwen("abcdcba"))
# 方法二:将首尾依次对比 s = input("请输入一个字符串:") if not s: print("请不要输入空字符串:") s = input("请重新输入一个字符串:") a = len(s) i = 0 count = 1 while i <= (a/2): if s[i] == s[a-i-1]: count = 1 i +=1 else: count = 0 break if count == 1: print("您输入的字符串是回文") else: print("您输入的字符串不是回文")
# 方法三:reversed()方法 s = input("请输入一个字符串:") if not s: print("请不要输入空字符串") s = input("请重新输入一个字符串") s1 = reversed(list(s)) if list(s1) == list(s): print("您输入的是一个回文字符串") else: print("您输入的不是一个回文字符串")
30、写代码寻找一个字符串中的所有回文子串,回文串是一个正读和反读都一样的字符串,比如“level”或者“noon”等就是回文串。
def is_huiwen(s): # 判断当前字符串是否是回文字符串 for i in range(len(s)): if s[i] != s[len(s)-i-1]: return False return True def find_huiwen(s): huiwenchuan = [] for i in range(len(s)): for j in range(i+1,len(s)): s1 = s[i:j+1] if is_huiwen(s1): huiwenchuan.append(s1) return huiwenchuan if __name__ == ‘__main__‘: s = "aabcbaadedffcde" huiwen = find_huiwen(s) print(huiwen)
31、编写一个查询及打印功能的话数要求能在当前目录以及当前目录的所有子目录下查找文件名包含指定字符串的文件。井打印出完整路径
import os def search_file(path, str): # 传入当前的绝对路径以及指定字符串 # 首先先找到当前目录下的所有文件 for file in os.listdir(path): # os.listdir(path)是当前这个path路径下的所有文件的列表 this_path = os.path.join(path, file) if os.path.isfile(this_path): # 判断这个路径对应的是目录还是文件,是文件就走下去 if str in file: print(this_path) else: # 不是就再继续再次执行这个函数,递归下去 search_file(this_path, str) # 递归 else: return None search_file(os.path.abspath("."), "t") # 返回path规范化的绝对路径
os.makedirs(‘dirname1/dirname2‘) 可生成多层递归目录 os.removedirs(‘dirname1‘) 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.mkdir(‘dirname‘) 生成单级目录;相当于shell中mkdir dirname os.rmdir(‘dirname‘) 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.listdir(‘dirname‘) 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove() 删除一个文件 os.rename("oldname","newname") 重命名文件/目录 os.stat(‘path/filename‘) 获取文件/目录信息 os.system("bash command") 运行shell命令,直接显示 os.popen("bash command).read() 运行shell命令,获取执行结果 os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd os.path os.path.abspath(path) 返回path规范化的绝对路径 os.path.split(path) 将path分割成目录和文件名二元组返回 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) 如果path是绝对路径,返回True os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间 os.path.getsize(path) 返回path的大小
基础知识点
列表:切片
当时第一反应就是普通思路
# 1、l = [2, 3, 4, 7, 9] 用切片实现取出偶数位+1的值求和 l = [2, 3, 4, 7, 9] l1 = l[::2] sum = 0 for i in l1: i1 = i + 1 sum += i1 print(sum)
但是面试官提醒说用lambda会更简单
数据库:
table: user|dep|salary uuu | A |22222 jjj | B |3333 kkk | C |33333 kas | A |3456
查询部门中前三名的工资(原生sql)
select * from t1 order by salary desc limit 3;
标签:影响 形式 编译型 如何 哥德巴赫猜想 oca 为我 print 相同
原文地址:https://www.cnblogs.com/hnlmy/p/10738087.html