标签:form def 包含 区块 链接 link 节点 lxml style
从0开始学爬虫3之xpath的介绍和使用
Xpath:一种HTML和XML的查询语言,它能在XML和HTML的树状结构中寻找节点
安装xpath:
pip install lxml
HTML
超文本标记语言(HyperText Mark-up Language),是一种规范,一种标准,是构成网页文档的主要语言
URL
统一资源定位器(Uniform Resource Locator),互联网上的每个文件都有一个唯一的URL,它包含的信息之处文件的位置以及浏览器应该怎么处理它
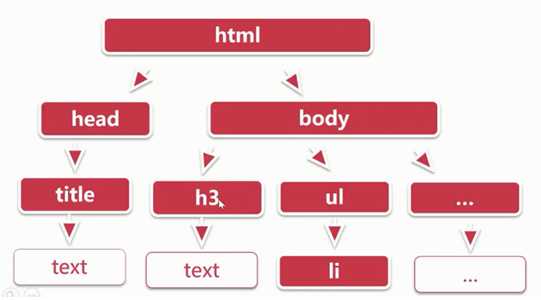
Xpath的使用语法:
获取文本:
//标签1[@属性1=”属性值1”]/标签2[@属性2=”属性值2”]/…/text()
获取属性值
//标签1[@属性1=”属性值1”]/标签2[@属性2=”属性值2”]/…/@属性n

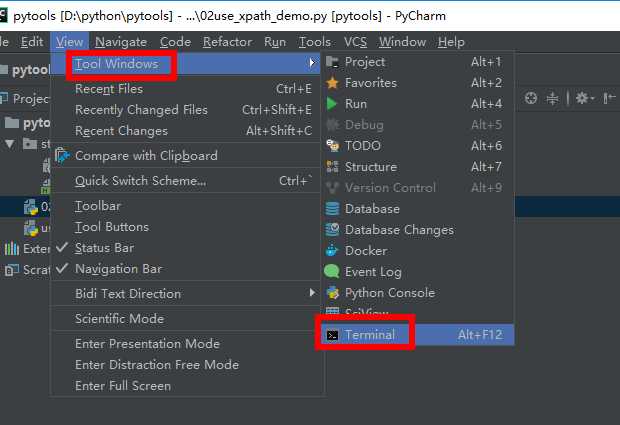
使用pycharm虚拟环境安装xpath模块
Xpath使用示例
用来进行xpath测试的网页 static/index.html
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <title>网页测试</title> <link rel="stylesheet" href=""> </head> <body> <h3>标题</h3> <ul> <li>内容1</li> <li>内容2</li> <li class="important">内容3important</li> <li>内容4</li> <li>内容5</li> </ul> <div> 内容未知 </div> <p> 段落内容 from p </p> <div id="container"> 段落文字 <a href="http://www.baidu.com" title="超链接">跳转到百度首页</a> <p class="content"> 区块内容1 </p> <p class="content"> 区块内容2 </p> <p class="content"> 区块内容3 </p> <p class="content"> 区块内容4 </p> <p class="content-block"> 区块内容5 from block </p> <p class="content-block"> 区块内容6 末尾内容 </p> <a href="http://www.so.com" title="超链接">跳转到360搜索首页</a> </div> <p> 最后一段文字 </p> </body> </html>
xpath使用示例
#coding=utf-8 from lxml import html def parse(): """将html文件中的内容,使用xpath进行提取""" # 读取文件中的内容 f = open(‘./static/index.html‘, ‘r‘, encoding=‘utf-8‘) s = f.read() selector = html.fromstring(s) # 解析H3标题 h3 = selector.xpath(‘/html/body/h3/text()‘) print(h3[0]) # 解析ul下面的内容 # ul = selector.xpath(‘/html/body/ul/li‘) # 双斜线语法 ul = selector.xpath("//ul/li") print(len(ul)) for li in ul: print(li.xpath(‘text()‘)[0]) # 解析ul指定的元素值 ul2 = selector.xpath(‘/html/body/ul/li[@class="important"]/text()‘) print(ul2) # 解析a标签的内容,拆分的方式 # a = selector.xpath(‘//div[@id="container"]/a‘) # 标签内的内容 # print(a[0].xpath("text()")[0]) # 得到标签的属性 # print(a[0].xpath("@href")[0]) # div[id="container"] 的第二个a标签内容 # print(a[1].xpath("text()")) # print(a[1].xpath("@href")[0]) # 解析a标签的内容,一次性解析的方式 a1 = selector.xpath(‘//div[@id="container"]/a/text()‘) # 标签内容 print(a1[0]) # 标签数学 alink = selector.xpath(‘//div[@id="container"]/a/@href‘) print(alink[0]) # 解析p标签 p = selector.xpath(‘/html/body/p[last()]/text()‘) print(p[0]) f.close() if __name__ == "__main__": parse()
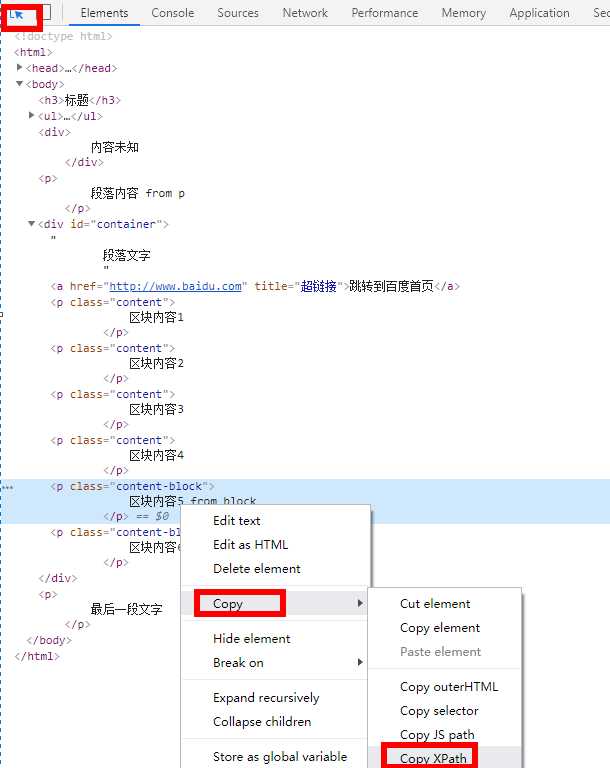
当我们在页面中找不到xpath的时候可以使用chrome的copy xpath进行参考
标签:form def 包含 区块 链接 link 节点 lxml style
原文地址:https://www.cnblogs.com/reblue520/p/11150316.html