标签:utc 取出 limit 直接 oca 定位 src har leo
Buffer 是java NIO中三个核心概念之一 缓存, 在java的实现体系中Buffer作为顶级抽象类存在
我们知道,在java IO中体系中, 因为InputStream和OutputStream是抽象类,而java又不可以多重继承,于是任何一个流要么只读,要么只写.而无法完成同时读写的工作
于是: Buffer来了
NIO中,对数据的读写,都是在Buffer中完成的,也就是说,同一个buffer我们可以先读后写, 它底层维护着一个数组,这个数组被三个重要的属性控制,有机的工作结合,使buffer可读可写;
此外,Buffer是线程不安全的,并发访问需要同步
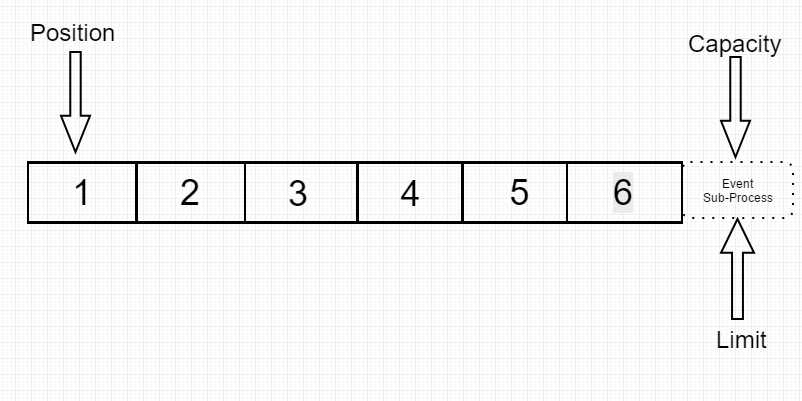
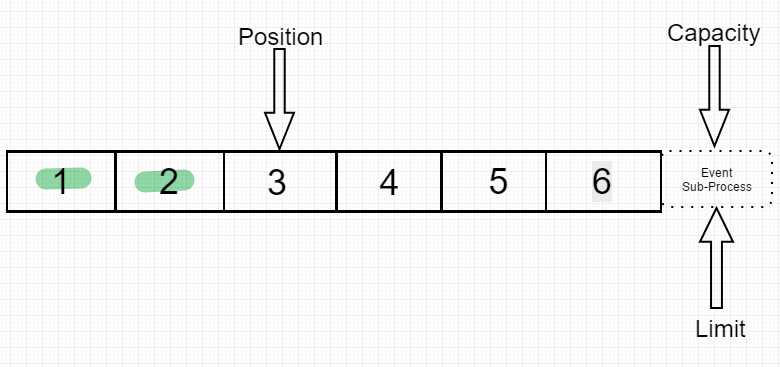
接着我们读入两个数据.position跳转到下一个将被读的index
接下来,准备写把buffer中的数据写出去两个, 于是我们需要反转数值
buffer.flip();反转的逻辑:
limit=position;
position=0;于是从0写 ,写到哪个位置? 写到limi前
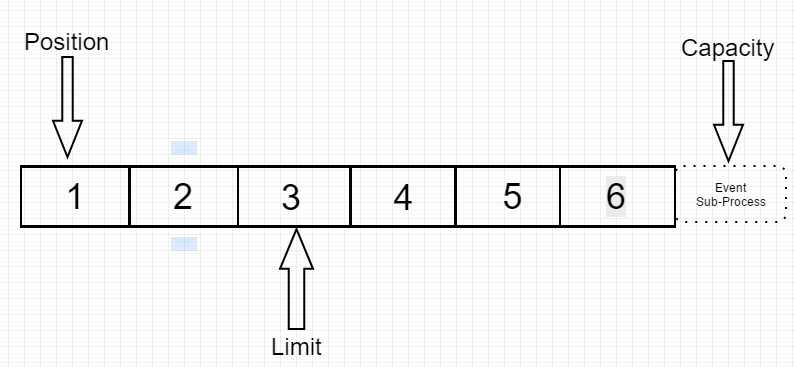
写完毕后:如下图:

现在可以看到,pisition == limit
如果再想读入新的数据,同样需要反转数据flip()
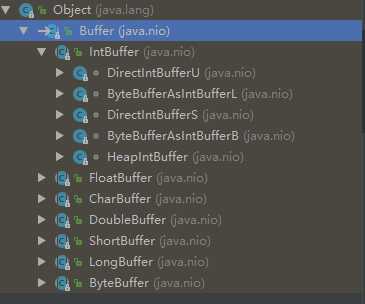
模拟Buffer实现一个相同的继承体系,进一步了解成员变量在他们之间是怎么维护的
首先,和Buufer等级一样的顶级父类
public abstract class ParentSupper {
private int position;
private int capacity;
ParentSupper(int position,int capacity){
this.position=position;
this.capacity=capacity;
System.out.println("ParentSupper 的构造方法执行了... ");
}
final int nextPutIndex(){
if (position>=capacity){
throw new RuntimeException("索引异常");
}
return position++;
}
int i=0;
final int nextGetIndex(){
if (i >=position){
throw new RuntimeException("索引异常");
}
return i++;
}
}接着是它的实现类, 和IntBuffer 等级一样
public abstract class Parent extends ParentSupper {
// 抽象类中的成员变量,必须放在构造方法中
final int[] arr1;
int tag;
// todo 执行父类的构造方法
Parent(int a, int[] arr1) {
// 调用父类的构造函数
super(0,a);
this.arr1 = arr1;
this.tag = a;
}
// 构造器
public static Parent allocate(int capacity) {
return new Child(capacity);
}
// 抽象的方法
public abstract int get();
public abstract void put(int number);
}作为抽象类的它,有自己的抽象方法, get put, 同时它里面维护着 核心数组, final不可变类型的, 抽象类中的变量不能单独存在,必须依附构造函数,于是我们添加它的构造函数
再就是它的实现类:
class Child extends Parent {
public Child(int capacity) {
super(capacity,new int[capacity]);
}
// todo 重写父类的构造方法
@Override
public int get() {
return arr1[nextGetIndex()];
}
@Override
public void put(int num) {
arr1[nextPutIndex()]=num;
}
}注意,Child的类上并没有public 修饰,意味着他只是可以包内访问
下面测试:
public class text {
public static void main(String[] args) {
// 初始化
Parent allocate = Parent.allocate(9);
for (int i=0;i<9;i++){
allocate.put(i);
}
for (int i=0;i<=8;i++){
System.out.println( allocate.get());
}
}
}运行流程是怎样的呢?
当我们使用
Parent.allocate(10);创建对象时,底层确实 new Child(int i), 同时把传递给Child, 而在Child()相应的构造函数中,接着调用的是spuer()方法,同时把10 传递给super也就是Parent,同时实例化了Parent的 数组, 在Supper的构造方法中,把0,和传递进来的10 传递给了SuperParent, 让他维护两个值
思考, 各个部分之间的作用
数组的维护工作是一样的,所以抽象成Buffer
不同类型的数据,具体的读写是有区别的,所有抽象成不同的子类
在回去看,allocate(); 显然我们得到的是最外层的子类对象,这也就意味着他是最强的那个对象,它拥有父类的数据,并且这个数据的读写由它的爷爷替自己把关,这就是Buffer的设计模式
get() 和 put()的方法clear()将buffer置为初始状态的值,实际上就是让新读入buffer中的值,覆盖掉原来的值
position=0;
limit=capacity;flip()反转buffer
limit = position;
positon=0;isReadOnly()判断是否是只读的buffer
//限制前后 准备切片
byteBuffer.position(2);
byteBuffer.limit(6);
// 切片
ByteBuffer slice = byteBuffer.slice();新得到的buffer和原buffer共享内存空间
ByteBuffer allocate = ByteBuffer.allocate(123);
allocate.putInt(1);
allocate.putChar('你');
allocate.putDouble(123.123123);
allocate.putShort((short) 2);
allocate.putLong(3L);
allocate.flip();
System.out.println(allocate.getInt());
System.out.println(allocate.getChar());
System.out.println(allocate.getDouble());
System.out.println(allocate.getShort());
System.out.println(allocate.getLong());类型化 的put和get 但是呢!!! 怎么存进去的 就得怎么取出来 , 否者会出现乱码
// 获取输入流
FileInputStream fileInputStream = new FileInputStream("123.txt");
FileOutputStream fileOutputStream = new FileOutputStream("output123.txt");
// 获取一个通道,关联上数据
FileChannel channel = fileInputStream.getChannel();
FileChannel outputStreamChannel = fileOutputStream.getChannel();
ByteBuffer byteBuffer = ByteBuffer.allocate(128);
while (true) {
// todo 每次读满一次缓存后, 重新初始化buffer
byteBuffer.clear();
// 将数据读入 缓存
int read = channel.read(byteBuffer);
System.out.println("read == "+read);
if (read == -1) {
break;
}
// 反转 limit=position position=0
byteBuffer.flip();
// 通过channel 往输出流中写入缓存的数据
outputStreamChannel.write(byteBuffer);
}
// 释放资源
fileInputStream.close();
fileInputStream.close();
System.out.println("结束...");
}每次循环一开始,都要重置buffer,否则第一轮读取结束之后, limit==position 从而channel里面新的数据读不进去,而 limit==position也不会引发异常,随后的flip()将buffer反转,position为0, 使得当前buffer中的数据被循环写到文件中,成为死循环
标签:utc 取出 limit 直接 oca 定位 src har leo
原文地址:https://www.cnblogs.com/ZhuChangwu/p/11150492.html