标签:文件读写 ascii码 告诉 encode res 参照物 lse splay 关系

8bit = 1Bytes 1024Bytes = 1KB 1024KB = 1MB 1024MB = 1GB 1024GB = 1TB 1024TB = 1PB 字符编码 字符编码的发展史 字符编码表 ASCII码 只有英文字母和符号与数字的对应关系 用8位二进制(1bytes)表示一个英文字符 GBK:中文 英文 符号与数字对应关系 用2bytes表示一个中文符号 兼容英文字符 shift euck 乱码: 编码与解码不一致 内存中unicode >>>编码(encode) 硬盘中utf-8编码 硬盘中utf-8编码 >>>解码(decode) 内存中的unicode 现在的计算机内存中统一用的都是unicode unicode两大特点: 1.用户无论输入哪个国家的字符都能够正常显示(兼容万国) 2.与任意国家的编码都有对应关系 文件头 # coding:gbk 指定python解释器读取该文件使用gbk编码,而不再用默认的 python2在读取文件默认使用的是ASCII码 python3在读取文件默认使用的是utf-8码 识别python语法执行python代码 x = ‘上‘ python2 如果不指定文件头 中文没法存储 那是因为python2解释器识别语法存储数据的时候默认使用的是ASCII 如果指定了文件头 python2解释器识别语法存储数据的时候使用文件头指定的编码 python2中通常都会在中文的字符串前面加一个u x = u‘上‘ 告诉python2解释器将上存成unicode的形式 python3 里面的字符串直接存成unicode(******) 保证不乱码的核心: 当初以什么编码存的(encode) 就以什么编码取(decode) 转换方式 res1 = b x = ‘上‘ # 第一种ytes(x,encoding=‘utf-8‘) print(res1,type(res1)) res2 = str(res1,encoding=‘utf-8‘) print(res2,type(res2)) # 第二种转换方式 res = x.encode(‘utf-8‘) print(type(res)) print(res.decode(‘utf-8‘)) 文件处理 一套完整的计算机系统 应用程序 操作系统 计算机硬件 什么是文件 操作系统暴露给用户操作复杂硬盘的简易接口 python代码操作文件 f = open(文件路径,mode=‘读写模式‘,encoding=‘utf-8‘) f.close() print(f) f:遥控器 文件句柄 文件的上下文管理 with open(....) as f: 文件操作 文件路径 相对路径:必须有一个参照物 通常是相对于执行文件所在的文件夹 绝对路径:类似于GPS全球定位,不需要有任何的参照物 r用来取消转义 r‘D:av\ttt\xxx\ooo\rrr‘ mode不写默认用的是rt encoding参数只在mode位文本模式的情况下才加 文件读写模式 r:只读模式 1.文件不存在的情况下 直接报错 2.文件存在的情况下 光标在文件开头 w:只写模式 1.文件不存在的情况下 自动创建新文件 2.文件存在的情况下 先清空文件内容再执行写入 a:只追加模式(只能在文件末尾添加内容) 1.文件不存在的情况下 自动创建新文件 2.文件存在的情况下 光标直接在文件末尾 文件操作单位 t:文本模式 只能和r/w/a连用 并且不写的情况下 默认就是t b:原生的二进制数据 只能和r/w/a连用 该模式通常用来处理非文本文件 直接存储网络上传输过来的二进制数据 有钱就买Mac f.read() 一次性将文件内容全部读到内存 当文件过大的情况下该方法可能会导致内存溢出 f.readline():一行行的读取内容 文件句柄f可以直接被for循环 每次for循环拿出来的就是文件一行行的内容 for line in f: print(line) \r\n:换行符 现在做了优化 可以只写\r或者\n f.readlines():将文件一行行的内存放是列表中 成为一个个元素 f.readable():是否可读 f.write() 写文件 f.writeable() 是否可写 f.writelines() 要接收一个容器类型 for i in l: f.write(i) f.writeline() 写一行
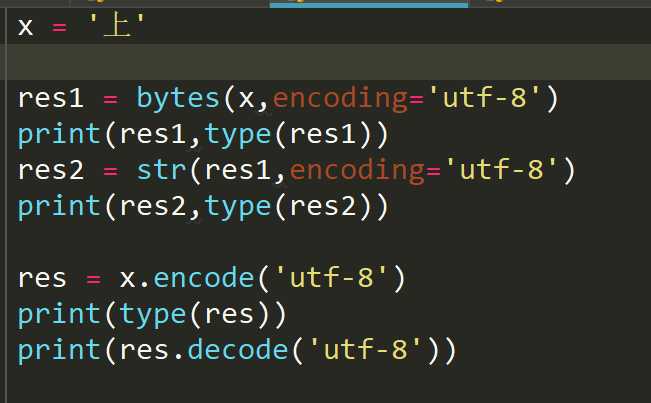
转换的两种方式
其他模式的补充:
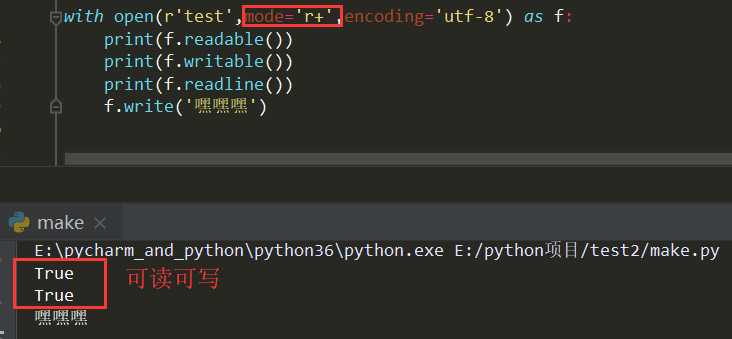
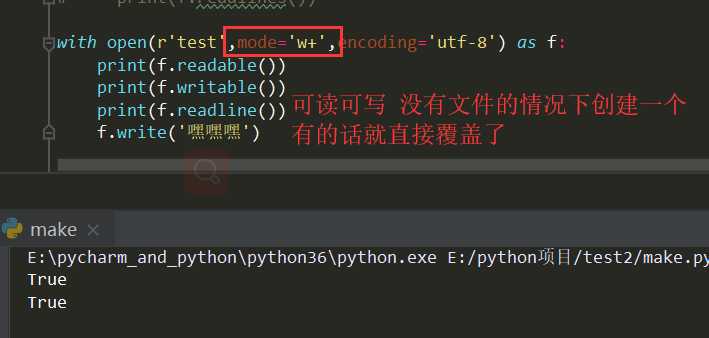
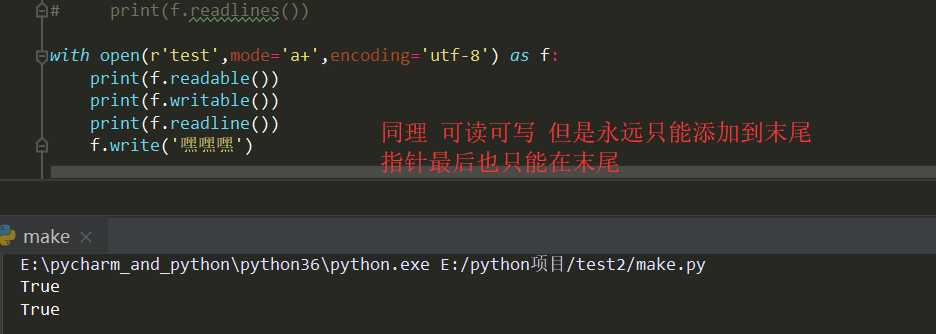
r w a 称为纯净模式 补充:r+ w+ a+
文件光标的移动(f.seek(offset,whence))
在rt模式下 read内的数字 表示的是字符的个数 初次之外,数字表示的都是字节
with open(r‘test‘,‘r‘,encoding=‘utf-8‘) as f: 默认rt
print(f.read(5))
with open(r‘test‘,‘rb‘) as f:
res = f.read(10) # 读的是三个字节bytes
print(res)
print(res.decode(‘utf-8‘))
f.seek(offset,whence)
offset:相对偏移量 光标移动的位数
whence:
0:参照文件的开头 t和b都可以使用
1:参照光标所在的当前位置 只能在b模式下用
2:参照文件的末尾 只能在b模式下使用
with open(r‘test‘,‘rt‘,encoding=‘utf-8‘) as f:
print(f.read(1))
f.seek(6,0) # seek移动都是字节数
f.seek(4,0) # seek移动都是字节数
写日志
import time
res = time.strftime(‘%Y-%m-%d %X‘)
with open(r‘test01.txt‘,‘a‘,encoding=‘utf-8‘) as f:
f.write(‘%s egon给jason发了1个亿的工资\n‘%res)
with open(r‘test01.txt‘,‘rb‘) as f:
# 先将光标移动到文件末尾
f.seek(0,2)
while True:
res = f.readline()
# 查看光标移动了多少位 bytes
# print(f.tell())
if res:
print("新增的文件内容:%s"%res.decode(‘utf-8‘))
# 说明有人操作当前文件
# else:
# # 说明文件没有被任何人操作
# print(‘暂无其他人操作该文件‘)
截断文件
with open(r‘test‘,‘a‘,encoding=‘utf-8‘) as f:
f.truncate(6) # 接收的字节的长度 整型
# 保留0~6字节数 后面的全部删除(截断)
修改文件
# 修改文件
# 先将数据由硬盘读到内存(读文件)
# 在内存中完成修改(字符串的替换)
# 再覆盖原来的内容(写文件)
with open(r‘test02.txt‘,‘r‘,encoding=‘utf-8‘) as f:
data = f.read()
print(data)
print(type(data))
with open(r‘test02.txt‘,‘w‘,encoding=‘utf-8‘) as f:
res = data.replace(‘egon‘,‘jason‘)
print(data)
f.write(res)
"""
优点:任意时间硬盘上只有一个文件 不会占用过多硬盘空间
缺点:当文件过大的情况下,可能会造成内存溢出
"""
# 文件修改方式2
# 创建一个新文件
# 循环读取老文件内容到内存进行修改 将修改好的内容写到新文件中
# 将老文件删除 将新文件的名字改成老文件名
import os
with open(r‘test02.txt‘,‘r‘,encoding=‘utf-8‘) as read_f, open(r‘test02.swap‘,‘a‘,encoding=‘utf-8‘) as write_f:
for line in read_f:
new_line = line.replace(‘jason‘,‘egon‘)
write_f.write(new_line)
os.remove(‘test02.txt‘)
os.rename(‘test02.swap‘,‘test02.txt‘)
"""
优点:内存中始终只有一行内容 不占内存
缺点:再某一时刻硬盘上会同时存在两个文件
"""
标签:文件读写 ascii码 告诉 encode res 参照物 lse splay 关系
原文地址:https://www.cnblogs.com/lddragon/p/11151922.html
