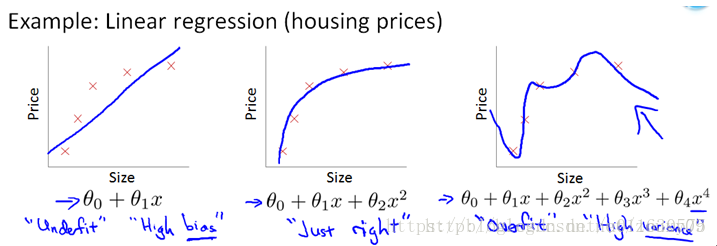
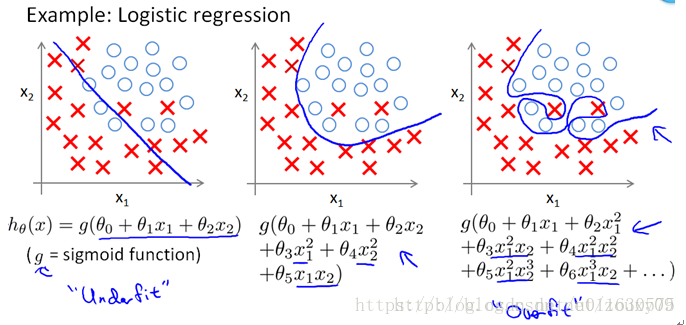
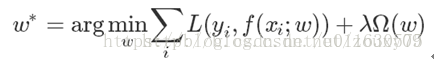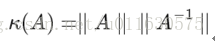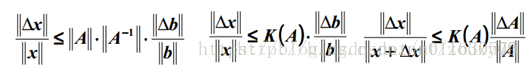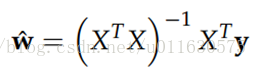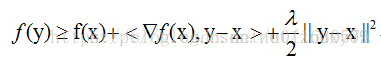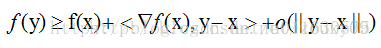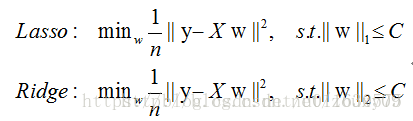标签:adr psi 江湖 参数说明 决策 不重复 分时 str 对比分析
原文:https://blog.csdn.net/zouxy09/article/details/2497199
OK,来个一句话总结:L1范数和L0范数可以实现稀疏,L1因具有比L0更好的优化求解特性而被广泛应用。
好,到这里,我们大概知道了L1可以实现稀疏,但我们会想呀,为什么要稀疏?让我们的参数稀疏有什么好处呢?这里扯两点:
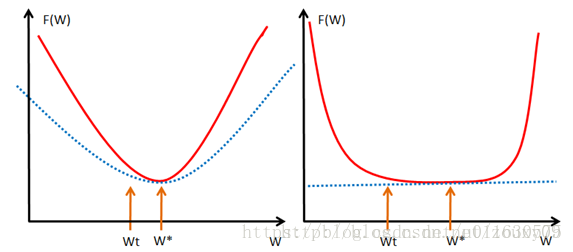
OK,那现在到我们非常关键的问题了,为什么L2范数可以防止过拟合?回答这个问题之前,我们得先看看L2范数是个什么东西。
这里也一句话总结下:通过L2范数,我们可以实现了对模型空间的限制,从而在一定程度上避免了过拟合。
从学习理论的角度来说,L2范数可以防止过拟合,提升模型的泛化能力。
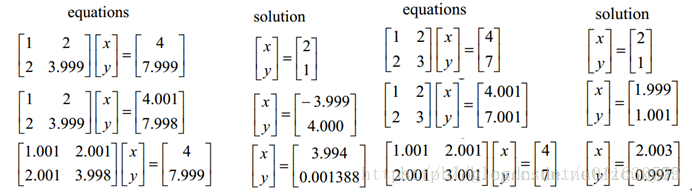
从优化或者数值计算的角度来说,L2范数有助于处理 condition number不好的情况下矩阵求逆很困难的问题。哎,等等,这condition number是啥?我先google一下哈。
如果方阵A是非奇异的,那么A的conditionnumber定义为:
也就是我们的解x的相对变化和A或者b的相对变化是有像上面那样的关系的,其中k(A)的值就相当于倍率,看到了吗?相当于x变化的界。
但如果加上L2规则项,就变成了下面这种情况,就可以直接求逆了:
时,我们称f为λ-stronglyconvex函数,其中参数λ>0。当λ=0时退回到普通convex 函数的定义。
在直观的说明强凸之前,我们先看看普通的凸是怎样的。假设我们让f在x的地方做一阶泰勒近似(一阶泰勒展开忘了吗?f(x)=f(a)+f‘(a)(x-a)+o(||x-a||).):
这一个优化说了那么多的东西。还是来个一句话总结吧:L2范数不但可以防止过拟合,还可以让我们的优化求解变得稳定和快速。
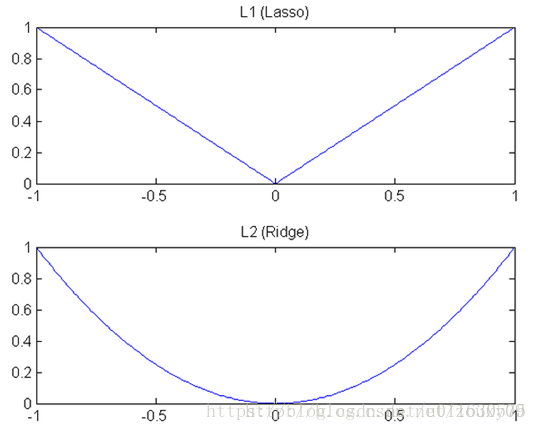
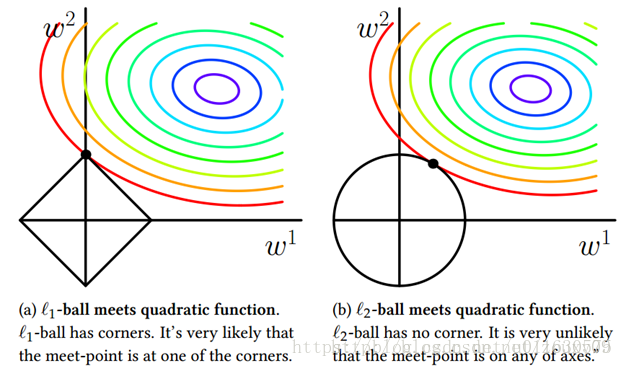
好了,这里兑现上面的承诺,来直观的聊聊L1和L2的差别,为什么一个让绝对值最小,一个让平方最小,会有那么大的差别呢?我看到的有两种几何上直观的解析:
L1在江湖上人称Lasso,L2人称Ridge。不过这两个名字还挺让人迷糊的,看上面的图片,Lasso的图看起来就像ridge,而ridge的图看起来就像lasso。
实际上,对于L1和L2规则化的代价函数来说,我们可以写成以下形式:
因此,一句话总结就是:L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0。Lasso在特征选择时候非常有用,而Ridge就只是一种规则化而已。
OK,就聊到这里。下一篇博文我们聊聊核范数和规则化项参数选择的问题。全篇的参考资料也请见下一篇博文,这里不重复列出。谢谢。
标签:adr psi 江湖 参数说明 决策 不重复 分时 str 对比分析
原文地址:https://www.cnblogs.com/tan2810/p/11154694.html