标签:elastic 查看 test ppi sha 解决 丢失 yellow 关注
1、文档
1)ElasticSearch是面向文档的,文档是所有可搜索数据的最小单位。例如:
a)日志文件中的日志项;
b)一张唱片的详细信息;
c)一篇文章中的具体内容;
2)在ElasticSearch中,文档会被序列化成Json格式:
a)Json对象是由字段组成的;
b)每个字段都有对应的字段类型(如:字符串、数值、日期类型等);
3)每个文档都有一个唯一的ID(Unique ID)
a)可以自己指定此ID;
b)也可以通过ElasticSearch自动生成;
4)我们可以将文档理解成关系型数据库中的一条数据记录,一条记录包含了一系列的字段。
5)Json文档的格式不需要预先定义
a)字段的类型可以指定或者由ElasticSearch自动推算;
b)Json支持数组、支持嵌套,如下图所示:

6)每一个文档中都包含有一份元数据,元数据的作用主要是用来标注文档的相关信息,如:
a)_index:文档所属的索引名;
b)_type:文档所属的类型名(从7.0开始,每一个索引只能创建一个Type:_doc,在此之前一个索引是可以设置多个Type的);
c)_id:文档的Unqie Id;
d)_source:文档的原始Json数据;
e)_version:文档的版本信息;
f)_score:文档的相关性算分;
2、索引(Index)
1)索引指的就是一类文档的集合,相当于文档的容器。
a)索引体现了逻辑空间的概念,每个索引都有自己的Mapping定义,用来定义所包含的文档的字段名和字段类型;
b)索引中的数据(文档)分散在Shard(分片)上,Shard体现了物理空间的概念;
2)索引的Mapping与Setting:
a)Mapping定义文档字段的类型;

b)Setting定义不同的数据分布;
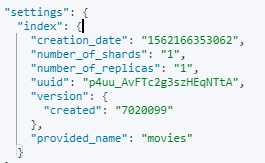
3)索引的含义:
a)一般说“索引文档到ElasticSearch的索引中”,前面的索引指的是一个动词的含义,也就是保存一个文档到ElasticSearch中。后面的索引是指在ElasticSearch集群中,可以创建很多个不同的索引;
b)索引分为:B树索引和倒排索引,而倒排索引在ElasticSearch中是非常重要的;
3、ElasticSearch与RDBMS的代入理解与类比如下:
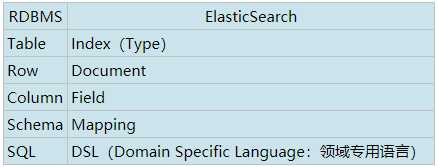
两者相对比,若对数据进行全文检索,以及进行算分时,ElasticSearch更加合适;当涉及的数据事务比较高时,那RDBMS更加合适。在实际生产中,一般是两者进行结合使用。
4、集群
ElasticSearch集群实际上是一个分布式系统,而分布式系统需要具备两个特性:
1)高可用性
a)服务可用性:允许有节点停止服务;
b)数据可用性:部分节点丢失,不会丢失数据;
2)可扩展性
随着请求量的不断提升,数据量的不断增长,系统可以将数据分布到其他节点,实现水平扩展;
ElasticSearch的集群通过不同的名字来进行区分,默认名字“elasticsearch”;
可以通过配置文件修改或者命令行修改:-E cluster.name=test
一个集群中可以有一个或者多个节点;
5、节点
1)节点是什么?
a)节点是一个ElasticSearch的实例,其本质就是一个Java进程;
b)一台机器上可以运行多个ElasticSearch实例,但是建议在生产环境中一台机器上只运行一个ElasticSearch实例;
2)每个节点都有名字,可以通过配置文件进行配置,也可以通过命令行进行指定,如:-E node.name=node1
3)每个节点在启动之后,会被分配一个UID,保存在data目录下;
4)Master-Eligible【有资格、胜任者】 Node与Master Node的说明:
a)每个节点启动之后,默认就是一个Master Eligible节点,当然可以在配置文件中将其禁止,node.master:false
b)Master-Eligible Node可以参加选主流程,成为Master Node;
c)当第一个节点启动时,它会将其选举为Master Node;
d)每个节点都保存了集群状态,但只有Master Node才能修改集群的状态,包括如下:
所有的节点信息;
所有的索引和其相关的Mapping与Setting信息;
分片的路由信息;
5)Data Node与Coordinating【协调、整合】 Node的说明:
a)Data Node:可以保存数据的节点,负责保存分片数据,在数据扩展上起到至关重要的作用;
b)Coordinating Node:它通过接受Rest Client的请求,会将请求分发到合适的节点,最终将结果汇集到一起,再返回给Client;
每个节点都默认起到Coordinating Node的职责;
6)Hot Node(热节点)与Warm Node(冷节点)的说明:
Hot Node:有更好配置的节点,其有更好的资源配置,如磁盘吞吐、CPU速度;
Warm Node:资源配置较低的节点;
7)Machine Learning Node:负责机器学习的节点,常用来做异常检测;
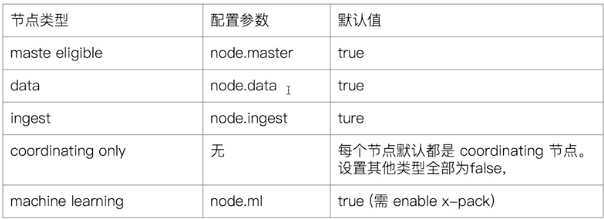
8)配置节点类型
每个节点在启动时,会读取elasticsearch.yml配置文件,来确定当前节点扮演什么角色。在生产环境中,应该将节点设置为单一的角色节点,这样可以有更好的性能,更清晰的职责,可以针对节点的不同给予不能的机器配置。
6、分片
1)Primary Shard(主分片)
可以解决数据水平扩展的问题,通过主分片,可以将数据分布到集群内的所有节点之上。
a)一个主分片是一个运行的Lucene的实例;
b)主分片数是在索引创建时指定,后续不允许修改,除非Reindex;
2)Replica Shard(副本)
可以解决数据高可用的问题,它是主分片的拷贝。
a)副本分片数可以动态调整;
b)增加副本数,在一定程度上可以提高服务的可用性;
3)分片的设定
对于生产环境中分片的设定,需要提前做好容量规划,因为主分片数是在索引创建时预先设定的,后续无法修改。
a)分片数设置过小
导致后续无法增加节点进行水平扩展。
导致分片的数据量太大,数据在重新分配时耗时;
b)分片数设置过大
影响搜索结果的相关性打分,影响统计结果的准确性;
单个节点上过多的分片,会导致资源浪费,同时也会影响性能;
7、ElasticSearch健康状况的查看
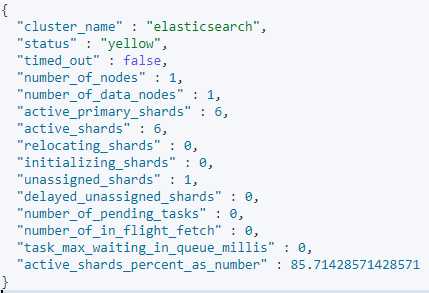
1)Green:主分片与副本都正常分配;
2)Yellow:主分片全部正常分配,有副本分片未能正常分配;
3)Red:有主分片未能分配;
8、总结
通过上面介绍,我们可以知道,索引与文档更偏向于开发人员的视角,属于逻辑上的一种概念;节点与分片更偏向于运维人员的视角,属于物理上的一种概念。
大家可关注我的公众号

知识学习来源:《Elasticsearch核心技术与实战》
ElasticStack学习(三):ElasticSearch基本概念
标签:elastic 查看 test ppi sha 解决 丢失 yellow 关注
原文地址:https://www.cnblogs.com/supersnowyao/p/11131790.html