标签:onstop 单元素 ike int() 表示 接收器 开始 特殊 历史

package com.lxl.streaming import org.apache.spark.SparkConf import org.apache.spark.streaming.{Seconds, StreamingContext} object WorldCount { def main(args: Array[String]) { // 定义更新状态方法,参数 values 为当前批次单词频度,state 为以往批次单词频度 val updateFunc = (values: Seq[Int], state: Option[Int]) => { val currentCount = values.foldLeft(0)(_ + _) val previousCount = state.getOrElse(0) Some(currentCount + previousCount) } val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount") val ssc = new StreamingContext(conf, Seconds(3)) ssc.checkpoint(".") // Create a DStream that will connect to hostname:port, like hadoop102:9999 val lines = ssc.socketTextStream("hadoop102", 9999) // Split each line into words val words = lines.flatMap(_.split(" ")) //import org.apache.spark.streaming.StreamingContext._ // not necessary since Spark 1.3 // Count each word in each batch val pairs = words.map(word => (word, 1)) // 使用 updateStateByKey 来更新状态,统计从运行开始以来单词总的次数 val stateDstream = pairs.updateStateByKey[Int](updateFunc) stateDstream.print() //val wordCounts = pairs.reduceByKey(_ + _) // Print the first ten elements of each RDD generated in this DStream to the console //wordCounts.print() ssc.start() // Start the computation ssc.awaitTermination() // Wait for the computation to terminate //ssc.stop() } }
[lxl@hadoop102 kafka]$ nc -lk 9999
------------------------------------------- Time: 1504685175000 ms ------------------------------------------- ------------------------------------------- Time: 1504685181000 ms ------------------------------------------- (shi,1) (shui,1) (ni,1) ------------------------------------------- Time: 1504685187000 ms ------------------------------------------- (shi,1) (ma,1) (hao,1) (shui,1) (ni,2)
[lxl@hadoop102 spark]$ sudo yum install nc.x86_64
[lxl@hadoop102 spark]$ nc -lk 9999
package com.atlxl.helloworld import java.io.{BufferedReader, InputStreamReader} import java.net.Socket import org.apache.spark.storage.StorageLevel import org.apache.spark.streaming.receiver.Receiver /* 自定义输入流 */ class CustomerRecevicer(host:String, port:Int) extends Receiver[String](StorageLevel.MEMORY_ONLY){ //接收器启动的时候调用 override def onStart(): Unit = { new Thread("receiver"){ override def run(): Unit = { //接受数据并提交给框架 receive() } }.start() } def receive(): Unit ={ var socket: Socket = null var input: String = null try { socket = new Socket(host,port) //生成数据流 val reader = new BufferedReader(new InputStreamReader(socket.getInputStream)) //接收数据 /* 方式一: */ while (!isStopped() && (input = reader.readLine()) != null){ store(input) } /* 方式二: */ // input = reader.readLine() // store(input) // while (!isStopped() && input != null){ // store(input) // input = reader.readLine() // } // restart("restart") }catch { case e:java.net.ConnectException => restart("restart") case t:Throwable => restart("restart") } } //接收器关闭的时候调用 override def onStop(): Unit = {} }
package com.atlxl.helloworld import org.apache.spark.SparkConf import org.apache.spark.streaming.{Seconds, StreamingContext} object WordCount { def main(args: Array[String]): Unit = { //conf val conf = new SparkConf().setAppName("wc").setMaster("local[*]") // val ssc = new StreamingContext(conf,Seconds(5)) //保存状态信息 ssc.checkpoint("./check") //获取数据 // val lineDStream = ssc.socketTextStream("hadoop102",9999) //自定义获取 val lineDStream = ssc.receiverStream(new CustomerRecevicer("hadoop102", 9999)) //DStream[String] val wordsDStream = lineDStream.flatMap(_.split(" ")) //DStream[(String,1)] val k2vDStream = wordsDStream.map((_,1)) //DStream[(String,sum)] //无状态转换 // val result = k2vDStream.reduceByKey(_+_) val updateFuc =(v:Seq[Int],state:Option[Int])=> { val preStatus = state.getOrElse(0) Some(preStatus + v.sum) } //有状态转换 val result = k2vDStream.updateStateByKey(updateFuc) result.print() //运行 ssc.start() ssc.awaitTermination() } }
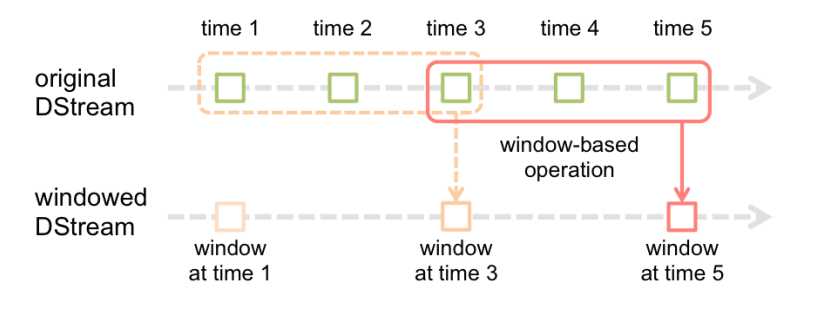
# reduce last 30 seconds of data, every 10 second
windowedWordCounts = pairs.reduceByKeyAndWindow(lambda x, y: x + y, lambda x, y: x -y, 30, 20)
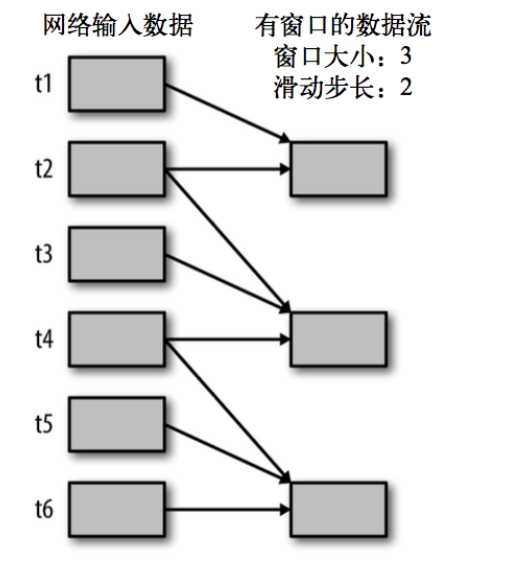
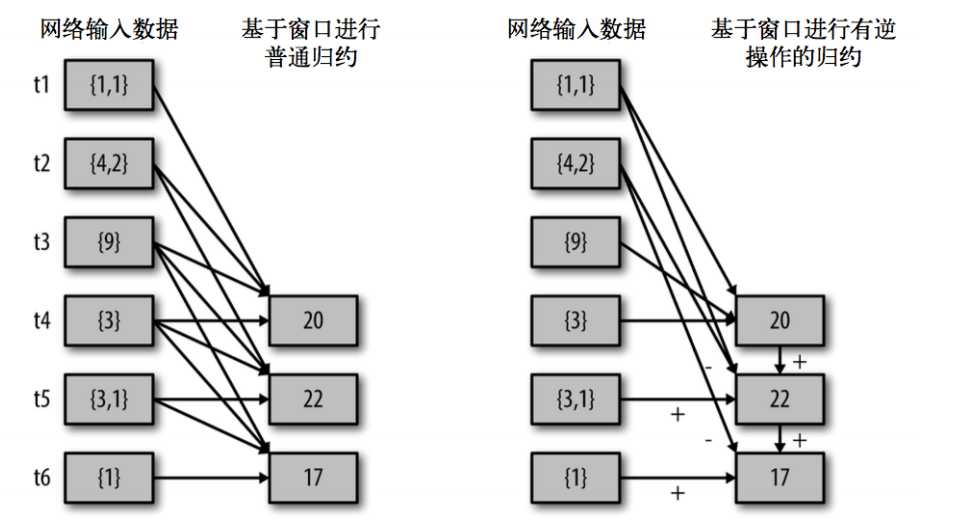
val ipDStream = accessLogsDStream.map(logEntry => (logEntry.getIpAddress(), 1)) val ipCountDStream = ipDStream.reduceByKeyAndWindow( {(x, y) => x + y}, {(x, y) => x - y}, Seconds(30), Seconds(10)) //加上新进入窗口的批次中的元素 //移除离开窗口的老批次中的元素 //窗口时长// 滑动步长
val ipDStream = accessLogsDStream.map{entry => entry.getIpAddress()}
val ipAddressRequestCount = ipDStream.countByValueAndWindow(Seconds(30), Seconds(10))
val requestCount = accessLogsDStream.countByWindow(Seconds(30), Seconds(10))
package com.atguigu.streaming import org.apache.spark.SparkConf import org.apache.spark.streaming.{Seconds, StreamingContext} object WorldCount { def main(args: Array[String]) { // 定义更新状态方法,参数 values 为当前批次单词频度,state 为以往批次单词频度 val updateFunc = (values: Seq[Int], state: Option[Int]) => { val currentCount = values.foldLeft(0)(_ + _) val previousCount = state.getOrElse(0) Some(currentCount + previousCount) } val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount") val ssc = new StreamingContext(conf, Seconds(3)) ssc.checkpoint(".") // Create a DStream that will connect to hostname:port, like localhost:9999 val lines = ssc.socketTextStream("hadoop102", 9999) // Split each line into words val words = lines.flatMap(_.split(" ")) //import org.apache.spark.streaming.StreamingContext._ // not necessary since Spark 1.3 // Count each word in each batch val pairs = words.map(word => (word, 1)) val wordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b),Seconds(12), Seconds(6)) // Print the first ten elements of each RDD generated in this DStream to the console wordCounts.print() ssc.start() // Start the computation ssc.awaitTermination() // Wait for the computation to terminate //ssc.stop() } }
val spamInfoRDD = ssc.sparkContext.newAPIHadoopRDD(...) // RDD containing spam information val cleanedDStream = wordCounts.transform { rdd => rdd.join(spamInfoRDD).filter(...) // join data stream with spam information to do data cleaning ... }
val stream1: DStream[String, String] = ... val stream2: DStream[String, String] = ... val joinedStream = stream1.join(stream2)
val windowedStream1 = stream1.window(Seconds(20)) val windowedStream2 = stream2.window(Minutes(1)) val joinedStream = windowedStream1.join(windowedStream2)
val dataset: RDD[String, String] = ... val windowedStream = stream.window(Seconds(20))... val joinedStream = windowedStream.transform { rdd => rdd.join(dataset) }
标签:onstop 单元素 ike int() 表示 接收器 开始 特殊 历史
原文地址:https://www.cnblogs.com/LXL616/p/11159243.html