标签:fine ima nal batch als dict origin 获得 segment
BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为decoder是不能获要预测的信息的。模型的主要创新点都在pre-train方法上,即用了Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。
由于模型的构成元素Transformer已经解析过,就不多说了,BERT模型的结构如下图最左:
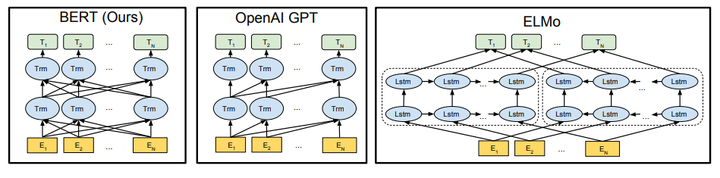
对比OpenAI GPT(Generative pre-trained transformer),BERT是双向的Transformer block连接;就像单向rnn和双向rnn的区别,直觉上来讲效果会好一些。
对比ELMo,虽然都是“双向”,但目标函数其实是不同的。ELMo是分别以 和
作为目标函数,独立训练处两个representation然后拼接,而BERT则是以
作为目标函数训练LM。
这里的Embedding由三种Embedding求和而成:
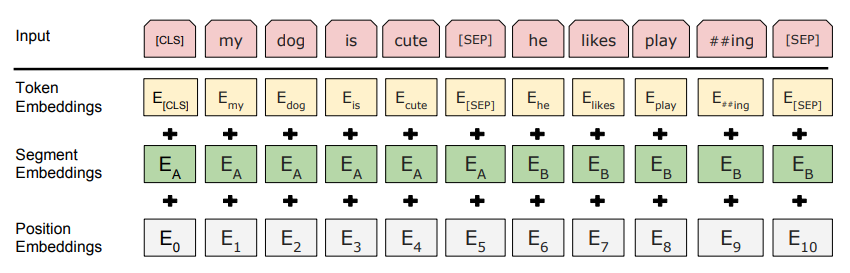
其中:
1. BERT的特征提取,是在捕捉词的(前后)位置关系。bidirectional决定了能获得前后的关系,position embedding决定了能学到更长的顺序关系。
2.训练,分为pre-train和fine-tune。pre-train中用到了MLM, Masked LM.
3. trick: MLM. 在训练过程中作者随机mask 15%的token,而不是把像cbow一样把每个词都预测一遍。最终的损失函数只计算被mask掉那个token。
4. 缺点: (1)[MASK]标记在实际预测中不会出现,训练时用过多[MASK]影响模型表现
(2)每个batch只有15%的token被预测,所以BERT收敛得比left-to-right模型要慢(它们会预测每个token)
https://zhuanlan.zhihu.com/p/46652512
https://arxiv.org/pdf/1810.04805.pdf
标签:fine ima nal batch als dict origin 获得 segment
原文地址:https://www.cnblogs.com/eniac1946/p/11167711.html