标签:方便 好的 高效 方法 新项目 疑问 下列表 变化 init
开心一刻
儿子有道题不会做,喊我过去教他。我推了推一旁的老公:我头疼,你去吧。老公不动,我:零花钱涨一千。话音刚落,老公就屁颠屁颠跑去儿子房间。进去不到几分钟,一声怒吼伴随着儿子的哭声传来的瞬间,老公从儿子房间出来,边走边说:“朽木不可雕也。”儿子从房间探出半个身子,一脸委屈:“爸爸也不会做,他说给我一块钱,让我明天早点去学校抄同学的。还让我不要告诉你,我不肯,他就吼我。”

前段时间,被紧急调到一个新项目,支撑新项目的开发。跌跌撞撞之下,项目也正常上线了,期间收获颇多,无论是业务上的,还是业务之外的。业务上的就不多说了,不具通用性,意义不大,有一点业务之外的东东给我的感触比较深,特记录下来,与大家分享下 : 查询优化
完整示例工程:data-init,包括数据库表的 ddl 和 dml,以及数据批量的生成
涉及的表不多,一共三张:额度表、记录表 、 存款表
额度表 t_custmor_credit

CREATE TABLE t_customer_credit ( id INT(11) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT ‘自增主键‘, login_name VARCHAR(50) NOT NULL COMMENT ‘名称‘, credit_type TINYINT(1) NOT NULL COMMENT ‘额度类型,1:自由资金,2:冻结资金,3:优惠‘, amount DECIMAL(22,6) NOT NULL DEFAULT ‘0.00000‘ COMMENT ‘额度值‘, create_by VARCHAR(50) NOT NULL COMMENT ‘创建者‘, create_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT ‘创建时间‘, update_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT ‘创建时间‘, update_by VARCHAR(50) NOT NULL COMMENT ‘修改者‘, PRIMARY KEY (id) );
记录每个顾客的当前额度,额度一共分三种:自由资金、冻结资金和优惠,也就是说每个顾客会有 3 条记录来表示他的各个额度。表中数据如下
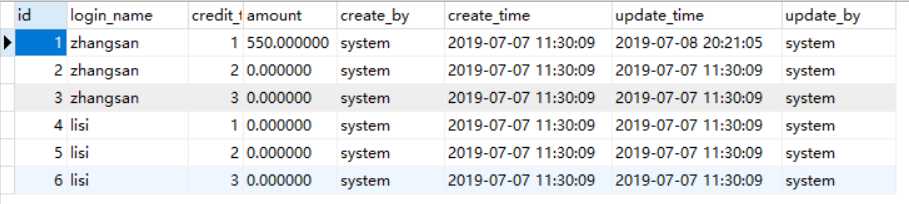
额度记录 t_custmor_credit_record
CREATE TABLE t_customer_credit_record ( id INT(11) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT ‘自增主键‘, login_name VARCHAR(50) NOT NULL COMMENT ‘名称‘, credit_type TINYINT(1) NOT NULL COMMENT ‘额度类型,参考t_custmor_credit的credit_type‘, bill_no VARCHAR(50) NOT NULL COMMENT ‘订单号‘, amount_before DECIMAL(22,6) NOT NULL DEFAULT ‘0.00000‘ COMMENT ‘前额度值‘, amount_change DECIMAL(22,6) NOT NULL DEFAULT ‘0.00000‘ COMMENT ‘额度变化值‘, amount_after DECIMAL(22,6) NOT NULL DEFAULT ‘0.00000‘ COMMENT ‘后额度值‘, create_by VARCHAR(50) NOT NULL COMMENT ‘创建者‘, create_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT ‘创建时间‘, remark VARCHAR(500) NOT NULL DEFAULT ‘‘ COMMENT ‘备注‘, PRIMARY KEY (id) );
记录顾客额度的每一次变化,只要有额度变化(不管是哪个额度进行了变化),都会新增3条记录,每个类型的额度都会新增一条记录。另外,该表只会有数据的插入,不会有数据的删、改。表中数据如下

存款表 t_custmor_deposit
CREATE TABLE t_customer_deposit ( id INT(11) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT ‘自增主键‘, login_name VARCHAR(50) NOT NULL COMMENT ‘名称‘, bill_no VARCHAR(50) NOT NULL COMMENT ‘订单号‘, amount DECIMAL(22,6) NOT NULL DEFAULT ‘0.00000‘ COMMENT ‘存款金额‘, deposit_state TINYINT(1) NOT NULL COMMENT ‘存款状态: 1成功,2失败,3未知‘, channal TINYINT(2) NOT NULL COMMENT ‘存款渠道: 1:银联,2支付宝,3微信‘, create_by VARCHAR(50) NOT NULL COMMENT ‘创建者‘, create_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT ‘创建时间‘, remark VARCHAR(500) NOT NULL DEFAULT ‘‘ COMMENT ‘备注‘, PRIMARY KEY (id) );
记录顾客的每一次存款,该表只会有数据的插入,不会有数据的删、改。表中数据如下

分页展示如下列表(具体的过滤条件就不列了,我们就当是初始状态,还未输入过滤条件)

实现比较简单,t_custmor_credit_record 左关联 t_custmor_deposit 就好,但是我们的额度记录表与需求列表有些许的出入,需要做一下简单的行转列。
我们先来看看最初的SQL查询,这可能是很多人最容易想到的
SELECT MIN(tcd.channal) channal, MAX(tccr.id) mId,tccr.login_name,tccr.bill_no,tccr.create_time, IF(credit_type=1,amount_before,0) AS freeBefore, IF(credit_type=1,amount_change,0) AS freeChange, IF(credit_type=1,amount_after,0) AS freeAfter, IF(credit_type=2,amount_before,0) AS freezeBefore, IF(credit_type=2,amount_change,0) AS freezeChange, IF(credit_type=2,amount_after,0) AS freezeAfter, IF(credit_type=3,amount_before,0) AS promotionBefore, IF(credit_type=3,amount_change,0) AS promotionChange, IF(credit_type=3,amount_after,0) AS promotionAfter FROM t_customer_credit_record tccr LEFT JOIN t_customer_deposit tcd ON tccr.bill_no = tcd.bill_no GROUP BY tccr.bill_no,tccr.login_name,tccr.create_time ORDER BY mId desc LIMIT 0, 10;
数据量少的时候,也许能在我们接受的时间内查出我们需要的结果,一旦数据量多了,这个SQL就跑不动了;我们先看下 60w 数据的情况下,我们只进行 t_custmor_credit_record 单表查询
SELECT MAX(id) mId,login_name,bill_no,create_time, IF(credit_type=1,amount_before,0) AS freeBefore, IF(credit_type=1,amount_change,0) AS freeChange, IF(credit_type=1,amount_after,0) AS freeAfter, IF(credit_type=2,amount_before,0) AS freezeBefore, IF(credit_type=2,amount_change,0) AS freezeChange, IF(credit_type=2,amount_after,0) AS freezeAfter, IF(credit_type=3,amount_before,0) AS promotionBefore, IF(credit_type=3,amount_change,0) AS promotionChange, IF(credit_type=3,amount_after,0) AS promotionAfter FROM t_customer_credit_record GROUP BY bill_no,login_name,create_time ORDER BY mId desc LIMIT 0, 10;
效果如下
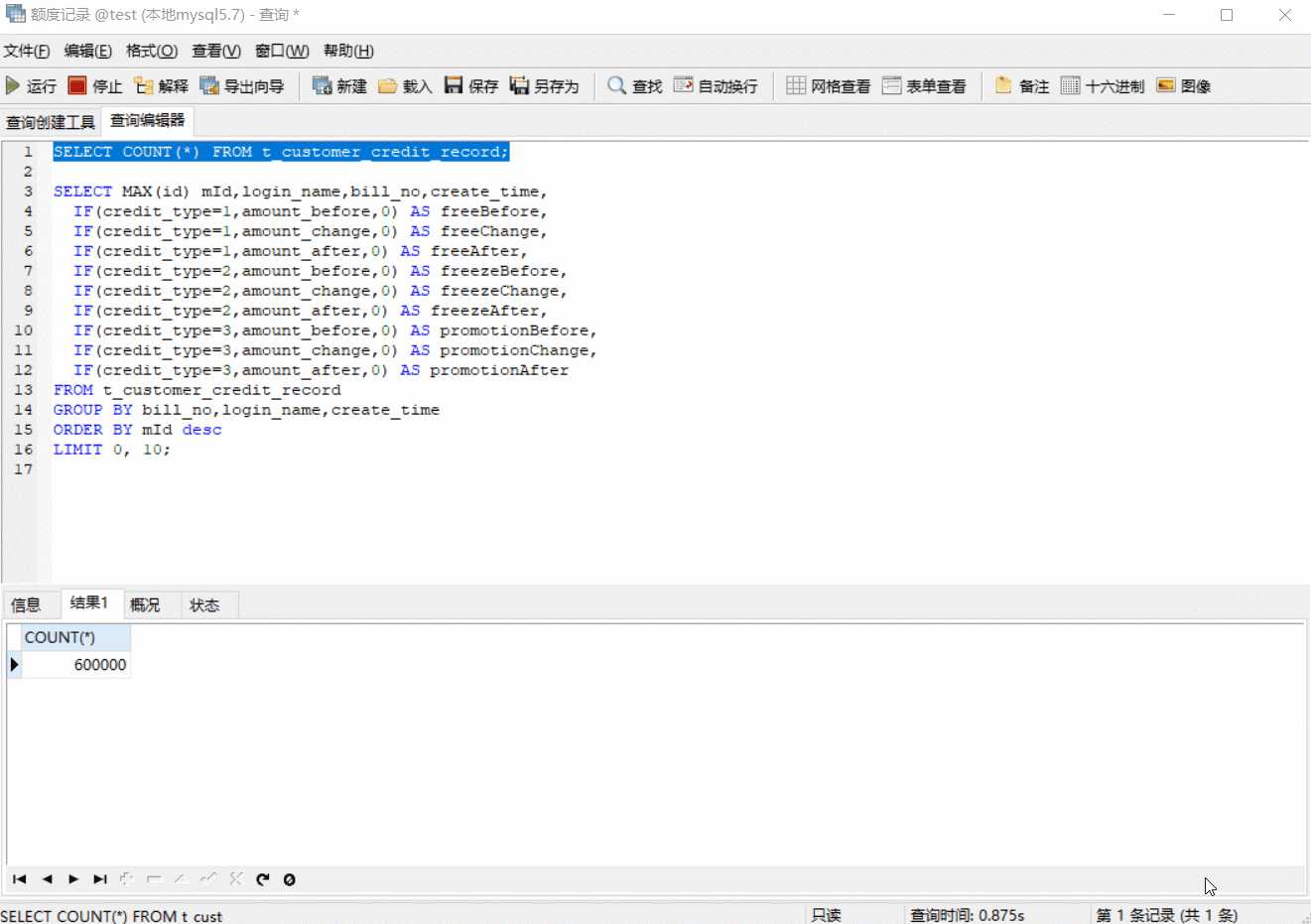
花了近 8 秒,这还只是单表,如果执行上面的联表SQL,那时间又得增加不少(我试验的结果是直接卡住了,看不到查询结果);
加索引
查询慢的时候,我们最容易想到的优化方式往往就是加索引;上述SQL执行的时候,t_custmor_credit_record 和 t_custmor_deposit都没有建索引(主键索引除外),那么我们就加索引呗。我的项目中加的是唯一索引,做了唯一约束,那我这里也加唯一索引
ALTER TABLE t_customer_credit_record ADD UNIQUE uk_unique (bill_no,login_name,create_time,credit_type); ALTER TABLE t_customer_deposit ADD UNIQUE uk_billno (bill_no);
此时我们看下SQL执行效果
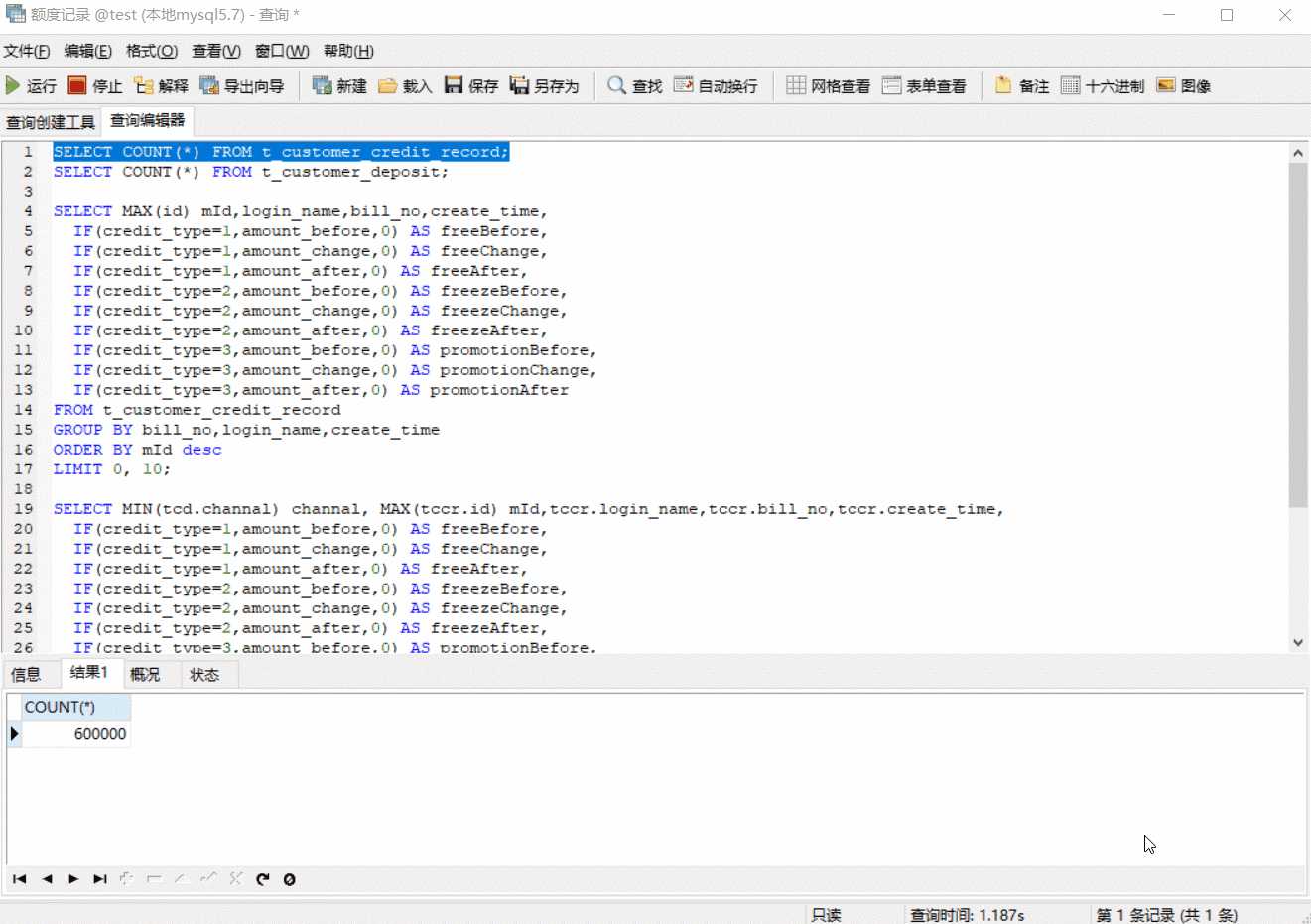
我们发现,t_custmor_credit_record 单表查询的效率几乎没变,将近 8 秒,但 t_custmor_credit_record 与 t_custmor_deposit 联表的查询却在 11 秒内有结果了。加了索引为什么还这么慢了? 难道没走索引?
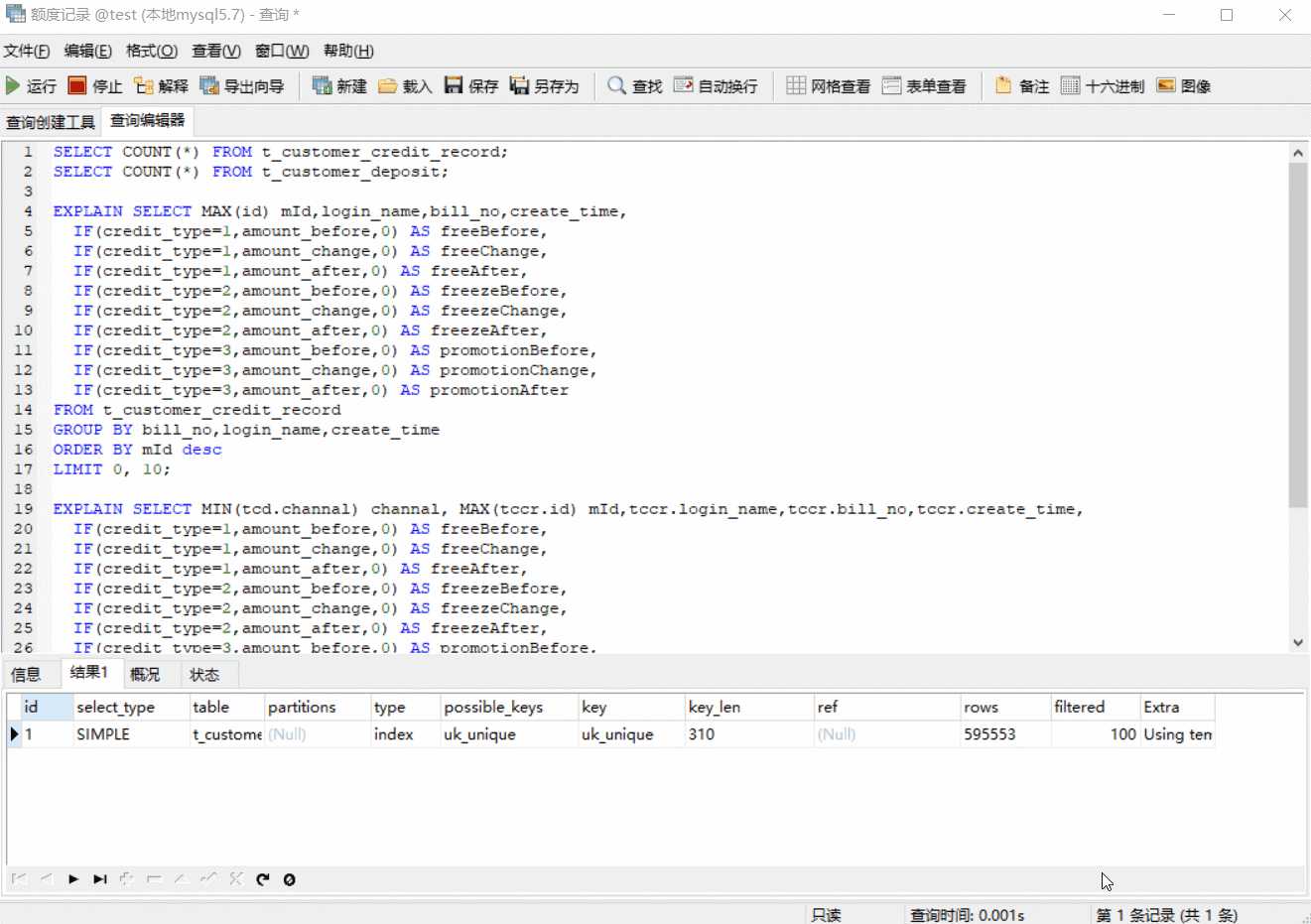
我们是不是发现了什么? IF函数对联表查询是否走索引有影响,也对单表的查询速度有影响。上图中的 t_custmor_credit_record 单表查询,有IF函数,查询时间近 8 秒,没有IF函数,查询时间 2 秒左右;t_custmor_credit_record 与 t_custmor_deposit 联表查,有IF函数,t_custmor_credit_record 走的是全表查,查询时间近 11 秒,没有IF函数,t_custmor_credit_record 走的是索引,查询时间 3 秒不到。那么我们有没有什么办法拿掉这个IF函数呢?
使用 CASE...WHEN....THEN 代替 IF
SELECT MAX(id) mId,login_name,bill_no,create_time, CASE credit_type WHEN 1 THEN amount_before ELSE 0 END AS freeBefore, CASE credit_type WHEN 1 THEN amount_change ELSE 0 END AS freeChange, CASE credit_type WHEN 1 THEN amount_after ELSE 0 END AS freeAfter, CASE credit_type WHEN 2 THEN amount_before ELSE 0 END AS freeChange, CASE credit_type WHEN 2 THEN amount_change ELSE 0 END AS freeChange, CASE credit_type WHEN 2 THEN amount_after ELSE 0 END AS freeChange, CASE credit_type WHEN 3 THEN amount_before ELSE 0 END AS promotionBefore, CASE credit_type WHEN 3 THEN amount_change ELSE 0 END AS promotionChange, CASE credit_type WHEN 3 THEN amount_after ELSE 0 END AS promotionAfter FROM t_customer_credit_record GROUP BY bill_no,login_name,create_time ORDER BY mId desc LIMIT 0, 10; SELECT MIN(tcd.channal) channal, MAX(tccr.id) mId,tccr.login_name,tccr.bill_no,tccr.create_time, CASE credit_type WHEN 1 THEN amount_before ELSE 0 END AS freeBefore, CASE credit_type WHEN 1 THEN amount_change ELSE 0 END AS freeChange, CASE credit_type WHEN 1 THEN amount_after ELSE 0 END AS freeAfter, CASE credit_type WHEN 2 THEN amount_before ELSE 0 END AS freeChange, CASE credit_type WHEN 2 THEN amount_change ELSE 0 END AS freeChange, CASE credit_type WHEN 2 THEN amount_after ELSE 0 END AS freeChange, CASE credit_type WHEN 3 THEN amount_before ELSE 0 END AS promotionBefore, CASE credit_type WHEN 3 THEN amount_change ELSE 0 END AS promotionChange, CASE credit_type WHEN 3 THEN amount_after ELSE 0 END AS promotionAfter FROM t_customer_credit_record tccr LEFT JOIN t_customer_deposit tcd ON tccr.bill_no = tcd.bill_no GROUP BY tccr.bill_no,tccr.login_name,tccr.create_time ORDER BY mId desc LIMIT 0, 10;
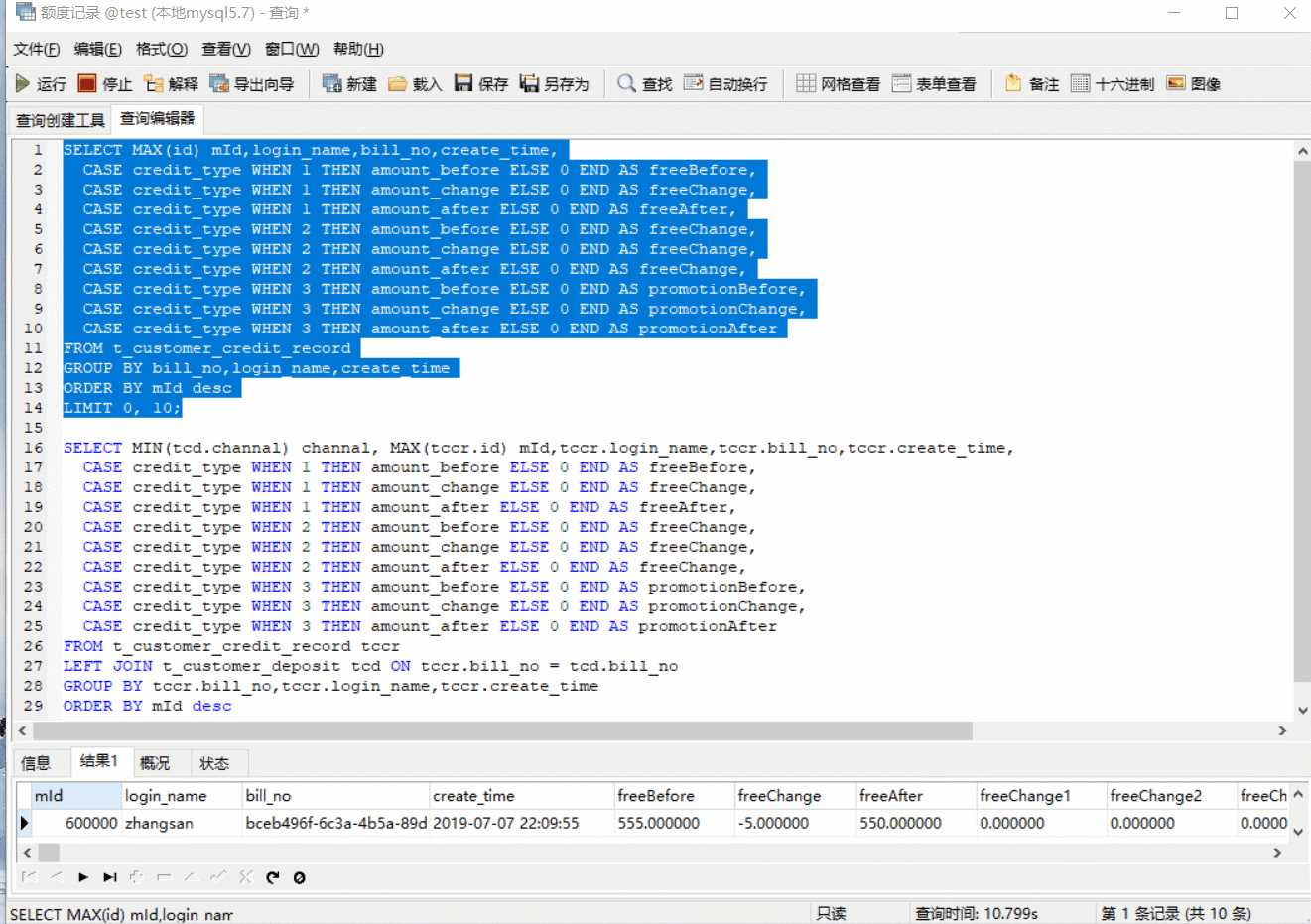
我们可以看到,执行时间与 IF 所差无几,执行计划也是与 IF 的一致,这也就反映出不是 IF的问题,应该是 GROUP BY 的问题。我们用 GROUP BY 结合 IF(或 CASE...WHEN....THEN),就是为了将 3 条额度记录合并成一条、行转列之后输出我们想要的结果,那有没有不用 GROUP BY、又能实现我们需求的方式了?
自联代替 GROUP BY
我们再仔细琢磨下这个需求,咋一看,确实需要行转列,那么就需要用到 GROUP BY,那么效率也就低了,这似乎是无解了? 真的非要行转列吗,假设我们将额度记录拆分成 3 张表:一张表只存自由资金的额度变化、一张表只存冻结资金的额度变化、一张表只存优惠的额度变化,这样是不是只需要联表查而不要用 GROUP BY 来进行行转列了? 有小伙伴有可能会问:t_custmor_credit_record 表已经定了,数据都跑了不少了,再将其进行拆分,既要改表(同时还要迁移数据),还要改代码,工程量会很大! 我们换个角度来看 t_custmor_credit_record ,目前它是 3 中额度记录的一个总和表,我们能不能从它的身上做文章,变化出我们想要的那 3 张表,然后进行联表查询呢? 肯定可以的,类似如下
-- 自由资金额度记录表 SELECT * FROM t_customer_credit_record WHERE credit_type = 1; -- 冻结资金额度记录表 SELECT * FROM t_customer_credit_record WHERE credit_type = 2; -- 优惠额度记录表 SELECT * FROM t_customer_credit_record WHERE credit_type = 3;
接下来的 SQL 怎么写,我想大家都知道了吧,自联就行了,写法有很多种,常见的写法有如下 4 种
-- 不用group by,做法1, 个人比较推荐, 但此种方式不支持存款表的过滤条件 SELECT d.channal,a.amount_before AS freeBefore,a.amount_change AS freeChange, a.amount_after freeAfter, b.amount_before AS freezeBefore,b.amount_change AS freezeChange, b.amount_after freezeAfter, c.amount_before AS promotionBefore,c.amount_change AS promotionChange, c.amount_after promotionAfter FROM ( SELECT * FROM t_customer_credit_record WHERE credit_type = 1 ORDER BY id DESC LIMIT 0, 10 ) a LEFT JOIN t_customer_credit_record b ON a.bill_no = b.bill_no AND b.credit_type = 2 LEFT JOIN t_customer_credit_record c ON a.bill_no = c.bill_no AND c.credit_type = 3 LEFT JOIN t_customer_deposit d ON a.bill_no = d.bill_no; -- 不用group by,做法2, 此种方式支持存款表的过滤条件 SELECT a.channal,a.amount_before AS freeBefore,a.amount_change AS freeChange, a.amount_after freeAfter, b.amount_before AS freezeBefore,b.amount_change AS freezeChange, b.amount_after freezeAfter, c.amount_before AS promotionBefore,c.amount_change AS promotionChange, c.amount_after promotionAfter FROM ( SELECT r.*,d.channal FROM t_customer_credit_record r LEFT JOIN t_customer_deposit d ON r.bill_no = d.bill_no WHERE r.credit_type = 1 ORDER BY r.id DESC LIMIT 0, 10 ) a LEFT JOIN t_customer_credit_record b ON a.bill_no = b.bill_no AND b.credit_type = 2 LEFT JOIN t_customer_credit_record c ON a.bill_no = c.bill_no AND c.credit_type = 3; -- 不用group by,做法3, 这是最容易想到的方法 SELECT d.channal,a.amount_before AS freeBefore,a.amount_change AS freeChange, a.amount_after freeAfter, b.amount_before AS freezeBefore,b.amount_change AS freezeChange, b.amount_after freezeAfter, c.amount_before AS promotionBefore,c.amount_change AS promotionChange, c.amount_after promotionAfter FROM t_customer_credit_record a LEFT JOIN t_customer_credit_record b ON a.bill_no = b.bill_no LEFT JOIN t_customer_credit_record c ON a.bill_no = c.bill_no LEFT JOIN t_customer_deposit d ON a.bill_no = d.bill_no WHERE a.credit_type = 1 AND b.credit_type = 2 AND c.credit_type = 3 ORDER BY a.id DESC LIMIT 0, 10; -- 不用group by,做法4 SELECT d.channal,a.amount_before AS freeBefore,a.amount_change AS freeChange, a.amount_after freeAfter, b.amount_before AS freezeBefore,b.amount_change AS freezeChange, b.amount_after freezeAfter, c.amount_before AS promotionBefore,c.amount_change AS promotionChange, c.amount_after promotionAfter FROM t_customer_credit_record a LEFT JOIN t_customer_credit_record b ON a.bill_no = b.bill_no AND b.credit_type = 2 LEFT JOIN t_customer_credit_record c ON a.bill_no = c.bill_no AND c.credit_type = 3 LEFT JOIN t_customer_deposit d ON a.bill_no = d.bill_no WHERE a.credit_type = 1 ORDER BY a.id DESC LIMIT 0, 10;
执行结果如下
就目前的数据量而言,4 种写法的效率一样,但是数据量再往上走,它们之前还是有性能差别的,大家可以仔细看看这 4 个 SQL 的执行计划,它们之间还是有区别的。最终我的项目中采用的是第一种写法
表重新设计
我们回过头去看看 t_customer_credit 和 t_custmor_credit_record,是否真的有必要用 3 条记录来存放顾客的 3 种额度,一条记录将用户的 3 种额度都记录下来不是更好吗? 如下所示
-- 自认为更好的表设计 DROP TABLE IF EXISTS t_customer_credit_plus; CREATE TABLE t_customer_credit_plus ( id INT(11) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT ‘自增主键‘, login_name VARCHAR(50) NOT NULL COMMENT ‘登录名‘, free_amount DECIMAL(22,6) NOT NULL DEFAULT ‘0.00000‘ COMMENT ‘自由资金额度‘, freeze_amount DECIMAL(22,6) NOT NULL DEFAULT ‘0.00000‘ COMMENT ‘冻结资金额度‘, promotion_amount DECIMAL(22,6) NOT NULL DEFAULT ‘0.00000‘ COMMENT ‘优惠资金额度‘, create_by VARCHAR(50) NOT NULL COMMENT ‘创建者‘, create_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT ‘创建时间‘, update_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT ‘创建时间‘, update_by VARCHAR(50) NOT NULL COMMENT ‘修改者‘, PRIMARY KEY (id), UNIQUE KEY `uk_login_name` (`login_name`) ); DROP TABLE IF EXISTS t_customer_credit_record_plus; CREATE TABLE t_customer_credit_record_plus ( id INT(11) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT ‘自增主键‘, login_name VARCHAR(50) NOT NULL COMMENT ‘登录名‘, bill_no VARCHAR(50) NOT NULL COMMENT ‘订单号‘, free_amount_before DECIMAL(22,6) NOT NULL DEFAULT ‘0.00000‘ COMMENT ‘自由资金前额度值‘, free_amount_change DECIMAL(22,6) NOT NULL DEFAULT ‘0.00000‘ COMMENT ‘自由资金前额度变化值‘, free_amount_after DECIMAL(22,6) NOT NULL DEFAULT ‘0.00000‘ COMMENT ‘自由资金前后额度值‘, freeze_amount_before DECIMAL(22,6) NOT NULL DEFAULT ‘0.00000‘ COMMENT ‘冻结资金前额度值‘, freeze_amount_change DECIMAL(22,6) NOT NULL DEFAULT ‘0.00000‘ COMMENT ‘冻结资金额度变化值‘, freeze_amount_after DECIMAL(22,6) NOT NULL DEFAULT ‘0.00000‘ COMMENT ‘冻结资金后额度值‘, promotion_amount_before DECIMAL(22,6) NOT NULL DEFAULT ‘0.00000‘ COMMENT ‘优惠前额度值‘, promotion_amount_change DECIMAL(22,6) NOT NULL DEFAULT ‘0.00000‘ COMMENT ‘优惠额度变化值‘, promotion_amount_after DECIMAL(22,6) NOT NULL DEFAULT ‘0.00000‘ COMMENT ‘优惠后额度值‘, create_by VARCHAR(50) NOT NULL COMMENT ‘创建者‘, create_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT ‘创建时间‘, remark VARCHAR(500) NOT NULL DEFAULT ‘‘ COMMENT ‘备注‘, PRIMARY KEY (id), UNIQUE KEY `uk_unique` (`bill_no`,`login_name`,`create_time`) );
我想很多人都会有相同的感觉吧,但是从拓展性出发,分 3 条记录的做法更好,为什么呢? 如果后续新增 1 种或多种另外的额度类型,上述的 1 条记录的表设计就需要新增字段来适配了, 但是 3 条记录的做法,只需要拓展credit_type的值就好了,表无需改动。各有利弊,如何选择,需要团队协商之后做出最好的选择。
最终项目中采用的还是 3 条记录存放 3 个额度的方式,没有采用我说的;原因是:大家都认为效率影响不大,也容易理解,关键是拓展性很好,后续很方便就能加入新的额度类型。
业务上的协调
最后我们再回到需求上来,这个 存款渠道 真的有必要显示在额度记录吗?
1、对公司来说,存款记录越多,那肯定是越好,但我们从实际出发,存款记录在额度记录中占的比例大吗,这个相信大家也都能想象得到,比例非常低,可能 100 条记录中会有 1 条;
2、本来就有单独的存款页面展示顾客的存款,去专门的存款记录页面看岂不是更直观?
最后和产品讨论,还真把这一列给拿掉了,那么我们也就不需要关联存款表来查了,SQL 更简单,效率也更高了!
1、SQL 行转列,往往是 GROUP BY 配合聚合函数(SUM、MAX、MIN等)来实现,当然也包括 IF 和 CASE...WHEN....THEN;
2、索引是提高查询效率的最有效的、也是最常用的方式,我们对查询的优化都要往索引上靠,EXPLAIN 可以查看SQL的执行计划,我们可以从中获取SQL优化的提示;
3、一定要结合业务来写出高效的SQL
可能很多小伙伴会有这样的不满:上述的 3 个额度的例子有点特殊,不具备通用性,上述高效的SQL也只是在你(楼主)的项目中有效。你说的对,但是我们要知道,技术本身就是用来服务业务的,脱离了业务,技术有什么实际意义? 但是我们回过头去细看,我举的例子真的就特殊到独一无二? 我想还算比较通用吧,还是能套用很多场景的。
4、要敢于质疑需求
虽然大多数时候产品都考虑比较周到,但也不能完全保证他没有不犯迷糊的时候吧。有疑惑就向产品问清楚,我们实现的也更快、更准确。一定不要对疑问藏着掖着,以我亲身经历来讲,很多时候开发认为的都是对的,如果藏着掖着,那你就准备返工改成你之前认为的那样吧!
标签:方便 好的 高效 方法 新项目 疑问 下列表 变化 init
原文地址:https://www.cnblogs.com/youzhibing/p/11105897.html
