标签:联合 内存 构造 指令 com 表达 分析器 空间 标识符
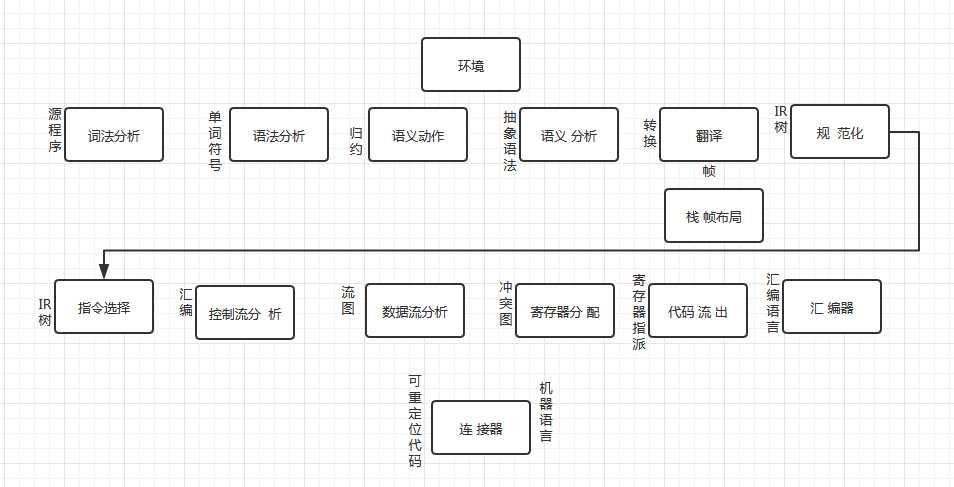
| 阶段 | 描述 |
|---|---|
| 词法分析 | 将原文件分解成一个个独立的单词符号 |
| 语法分析 | 分析程序的短语结构 |
| 语义动作 | 建立每个短语对应的抽象语法树 |
| 语义分析 | 确定每个短语的含义,建立变量和其声明的关联。检查每个表达式的类型,翻译每个短语 |
| 栈帧布局 | 按机器要求的方式将变量、函数参数等分配于活跃记录 |
| 翻译 | 生成中间表示树(IR树)这是一种与任意特定程序设计语言和目标机体系结构无关的表示 |
| 规范化 | 提取表达式中的副作用,整理条件分支,方便下一阶段的处理 |
| 指令选择 | 将IR树节点组合成,与目标机指令动作相对应的块 |
| 控制流分析 | 分析指令顺序,并建立控制流图,此图表示程序执行时可能流经的所有控制流 |
| 数据流分析 | 收集程序变量和数据流信息,例如活跃分析,计算每一个变量仍需使用其值的地点(即他的活跃点) |
| 寄存器分配 | 为程序的每一个变量和临时数据选择一个寄存器,不在同一时间活跃的两个变量可以共享一个寄存器 |
| 代码流出 | 用机器寄存器代替每一条机器指令中出现的临时变量名 |
现代编译器使用两种最有用的抽象是上下文无关文法和正则表达式。上下文无关文法用于语法分析,正则表达式用于词法分析。为了更好的利用这两种抽象较好的做法是借助一些专门的工具,例如YACC,他将文法转换成语法分析器和LEX他将一个说明性质的规范转换成一个词法分析器。
树可以用文法来描述,就向程序设计语言一样。这里给出一种简单的程序设计语言,该程序设计语言有语句和表达式,但是没有循环或if语句,这种语言称为直线式程语言

a:=5+3;b:=(print(a,a-1).10*a);print(b);打印出8、7、80
一种是源码形式,是程序员所编写的字符,但是这种表示不易处理。较为方便的表示是树数据结构,每一个语句(Stm)和每一个表达式(Exp)都有一个树节点,如下图给出了树表示,其中每个节点产生式的标识加以标记,并且每个子节点的数量与相应的文法产生式右边的符号个数相同。
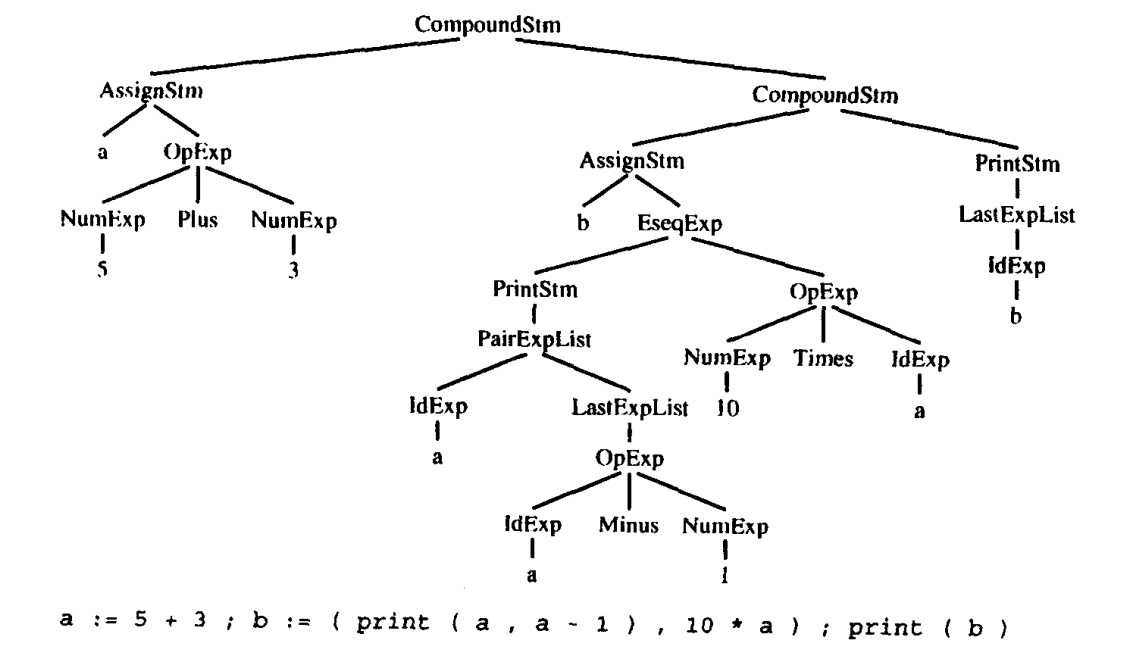
我们可以将这个文法直接翻译成数据结构定义,每个文法符号对应这些结构中的一个typedef


A_stm A_CompoundStm(A_stm stm1,A_stm stm2){
A_stm s=checked_malloc(sizeof(*s));
s->kind=A_CompoundStm;
s->u.compound.stm1=stm1;s->u.compound.stm2=stm2;
return s;
}二元操作符的情景要简单些(Binop),尽管也可以为Binop创建一个结构(成员分别表示Plus、Minus、Times、Div),但这样是多余的,因为这些成员并不存放数据,我们为他定义一个枚举类型A_binop
类型定义名(位于前缀之后的)应用小写字母开头,构造函数名,用大写字母开头,联合的成员用小写字母开头
也不调用free
编写没有副作用(即更新变量及数据结构的赋值语句)的解释器是理解指语义和属性文法的好方法,后两者都是描述程序设计语言做什么方法。
标签:联合 内存 构造 指令 com 表达 分析器 空间 标识符
原文地址:https://www.cnblogs.com/binarysystemloophole/p/11169038.html