标签:不用 imu class like 最可 first info ike cti
1.为什么不用Regression?
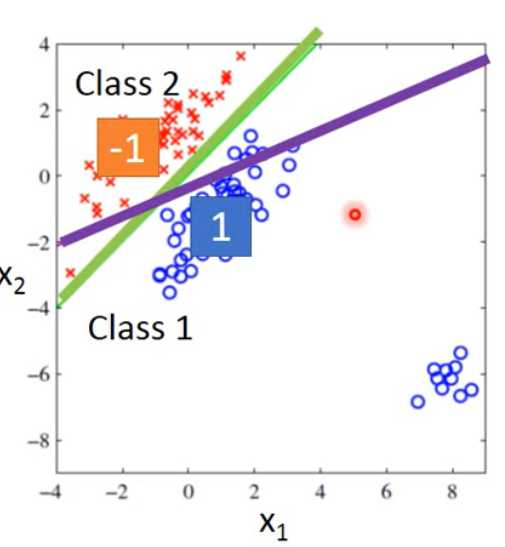
用Regression显然会得到紫色线,而不是绿线
2.定义Loss Function
即分类不正确的样本个数

3.求每个元素在某个类别的概率
p(class1|x) = p(x|class1)p(class1) / [p(x|class1)p(class1) + p(x|class2)p(class2)]
p(class1)和p(class2)可以容易的算出
重点在于求p(x|class1)
假设class1是个高斯分布,我们如果有高斯分布的参数miu,sigma,就能求出p(x|class1)
现在问题是找到最可能生成出样本的高斯分布。
用Maximum Likelihood估计出miu,sigma。
在二位四个参数的时候,miu1,miu2,sigma1,sigma2,实际效果不好。
尝试让miu1=miu2,按样本数加权平均获得sigma,转换成Linear。
4.总结
Three Steps
first: Functions Set(Model) 如何定义分类
second: Goodness of a function 评估一个Model,
third: Find the best function
5.Naive Bayes Classifer
假设各个特征独立
p(x|c1)=p(x1|c1)*p(x2|c1)*...*p(xk|c1)
这样就没有高维分布,转化为一维分布
标签:不用 imu class like 最可 first info ike cti
原文地址:https://www.cnblogs.com/hsuppr/p/11175509.html