标签:round media amp images https 返回 网页 bsp return
目标网址:http://www.7799520.com/jiaoyou.html
scrapy startproject 项目名(我这里是wzlySpider)
进入创建好的wzlySpider 目录文件下
scrapy genspider wzly www.7700520.com
注意:genspider命令会使用Scrapy默认的爬虫模板创建爬虫文件,当然这个文件也可以自己编写,但是推荐使用命令创建。
创建好爬虫后,使用编辑器打开项目中的爬虫文件进行编写:
wzly.py 爬虫文件
# -*- coding: utf-8 -*-
import scrapy
import json
class WzlySpider(scrapy.Spider):
name = ‘wzly‘
allowed_domains = [‘7799520.com‘]
# 这里使用列表推导式
start_urls = [f‘http://www.7799520.com/api/user/pc/list/search?marry=1&page={page}‘ for page in range(1, 100)]
# 解析响应
def parse(self, response):
html = response.text
# 转换json格式
json_data = json.loads(html)
# 获取信息 返回是列表
for i in json_data["data"]["list"]:
# i 是个字典
img_url = i["avatar"]
item = {
"img_url": img_url
}
yield item
name是爬虫的名字,是在genspider的时候指定的。allowed_domains是爬虫能抓取的域名,爬虫只能在这个域名下抓取网页,可以不写。start_urls网址发出请求后得到的响应。当然也可以指定其他函数来接收响应
编写 pipelines.py 管道文件
import scrapy
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
class wzlyImagePipeline(ImagesPipeline):
def get_media_requests(self, item, info):
yield scrapy.Request(item["img_url"])
def item_completed(self, results, item, info):
image_path = [x[‘path‘] for ok, x in results if ok]
if not image_path:
raise DropItem("该Item没有图片")
return item
设置 settings.py 配置文件
1、激活管道文件
ITEM_PIPELINES = {
‘wzlySpider.pipelines.wzlyImagePipeline‘: 300,
}
注意:300 表示执行顺序 ,一般为0-1000,数字越小执行顺序越大
2、配置保存图片信息
IMAGES_STORE = r‘D:\\wzly‘ # 图片存储路径 IMAGES_EXPIRES = 90 # 过期天数 IMAGES_MIN_HEIGHT = 100 # 图片的最小高度 IMAGES_MIN_WIDTH = 100 # 图片的最小宽度
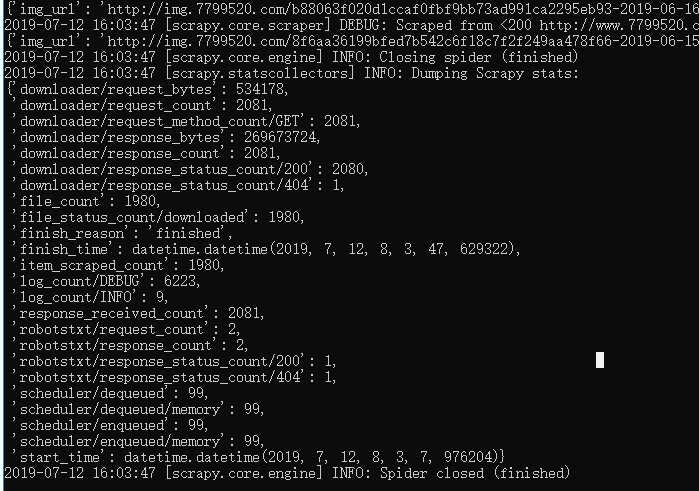
在 /wzlySpider 目录下运行scrapy crawl wzly 即可运行爬虫项目。运行截图如下:
更多详细信息,请参考:Scrapy官方文档
标签:round media amp images https 返回 网页 bsp return
原文地址:https://www.cnblogs.com/renshaoqi/p/11177569.html