标签:检查 高效 开发人员 上启 reduce 独立 用户 创业公司 性方面
1.Flink 概述
1.1 流处理技术的演变
在开源世界里,Apache Storm 项目是流处理的先锋。Storm 最早由 Nathan Marz
和创业公司 BackType 的一个团队开发,后来才被 Apache 基金会接纳。Storm 提供
了低延迟的流处理,但是它为实时性付出了一些代价:很难实现高吞吐,并且其正
确性没能达到通常所需的水平,换句话说,它并不能保证 exactly-once,即便是它能
够保证的正确性级别,其开销也相当大。
在低延迟和高吞吐的流处理系统中维持良好的容错性是非常困难的,但是为了
得到有保障的准确状态,人们想到了一种替代方法:将连续时间中的流数据分割成
一系列微小的批量作业。如果分割得足够小(即所谓的微批处理作业),计算就几
乎可以实现真正的流处理。因为存在延迟,所以不可能做到完全实时,但是每个简
单的应用程序都可以实现仅有几秒甚至几亚秒的延迟。这就是在 Spark 批处理引擎
上运行的 Spark Streaming 所使用的方法。
更重要的是,使用微批处理方法,可以实现 exactly-once 语义,从而保障状态
的一致性。如果一个微批处理失败了,它可以重新运行,这比连续的流处理方法更
容易。Storm Trident 是对 Storm 的延伸,它的底层流处理引擎就是基于微批处理方
法来进行计算的,从而实现了 exactly-once 语义,但是在延迟性方面付出了很大的
代价。
对于 Storm Trident 以及 Spark Streaming 等微批处理策略,只能根据批量作业时
间的倍数进行分割,无法根据实际情况分割事件数据,并且,对于一些对延迟比较
敏感的作业,往往需要开发者在写业务代码时花费大量精力来提升性能。这些灵活
性和表现力方面的缺陷,使得这些微批处理策略开发速度变慢,运维成本变高。
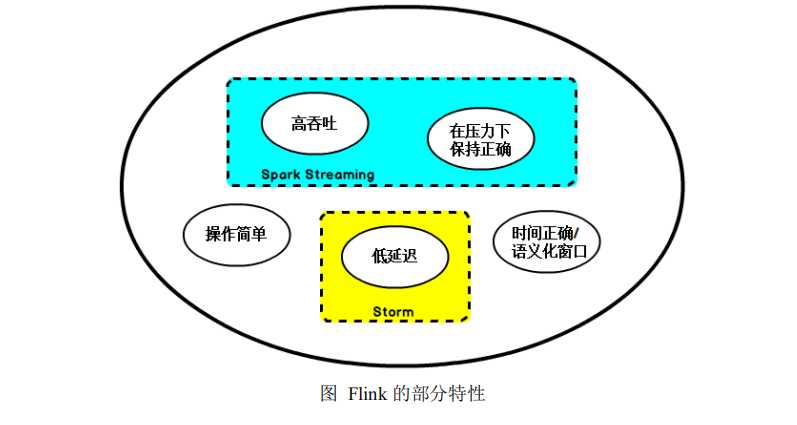
于是,Flink 出现了,这一技术框架可以避免上述弊端,并且拥有所需的诸多功
能,还能按照连续事件高效地处理数据,Flink 的部分特性如下图所示:
1.2 初识 Flink
Flink 起源于 Stratosphere 项目,Stratosphere 是在 2010~2014 年由 3 所地处柏林
的大学和欧洲的一些其他的大学共同进行的研究项目,2014 年 4 月 Stratosphere 的
代 码被 复制 并捐赠 给了 Apache 软件基 金会, 参加 这个 孵化项 目的 初始 成员 是
Stratosphere 系统的核心开发人员,2014 年 12 月,Flink 一跃成为 Apache 软件基金
会的顶级项目。
在德语中,Flink 一词表示快速和灵巧,项目采用一只松鼠的彩色图案作为 logo,
这不仅是因为松鼠具有快速和灵巧的特点,还因为柏林的松鼠有一种迷人的红棕色,
而 Flink 的松鼠 logo 拥有可爱的尾巴,尾巴的颜色与 Apache 软件基金会的 logo 颜
色相呼应,也就是说,这是一只 Apache 风格的松鼠。

Flink 主页在其顶部展示了该项目的理念:“Apache Flink 是为分布式、高性能、
随时可用以及准确的流处理应用程序打造的开源流处理框架”。
Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有
状态计算。Flink 被设计在所有常见的集群环境中运行,以内存执行速度和任意规模
来执行计算。
1.3 Flink 核心计算框架
Flink 的核心计算架构是下图中的 Flink Runtime 执行引擎,它是一个分布式系统,能够
接受数据流程序并在一台或多台机器上以容错方式执行。
Flink Runtime 执行引擎可以作为 YARN(Yet Another Resource Negotiator)的应用程序
在集群上运行,也可以在 Mesos 集群上运行,还可以在单机上运行(这对于调试 Flink 应用
程序来说非常有用)。
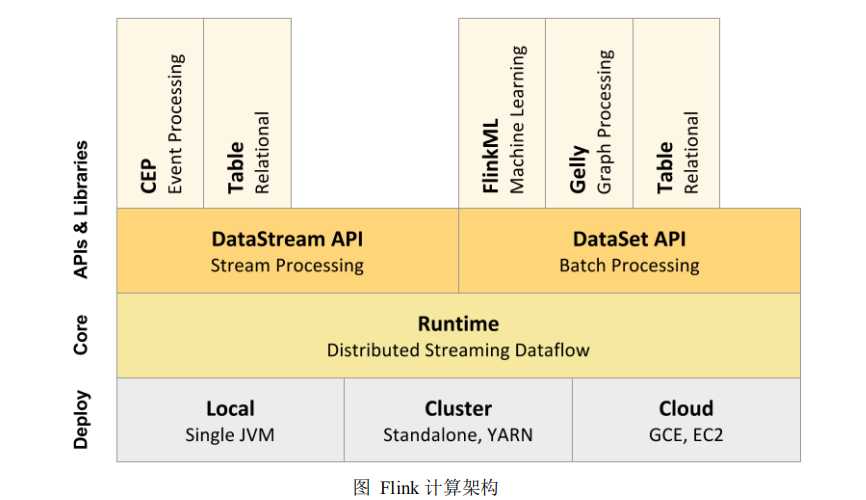
上图为 Flink 技术栈的核心组成部分,值得一提的是,Flink 分别提供了面向流
式处理的接口(DataStream API)和面向批处理的接口(DataSet API)。因此,Flink
既可以完成流处理,也可以完成批处理。 Flink 支持的拓展库涉及机器学习
(FlinkML)、复杂事件处理(CEP)、以及图计算(Gelly),还有分别针对流处
理和批处理的 Table API。
能被 Flink Runtime 执行引擎接受的程序很强大,但是这样的程序有着冗长的代
码,编写起来也很费力,基于这个原因,Flink 提供了封装在 Runtime 执行引擎之上
的 API, 以 帮 助 用 户 方 便 地 生 成 流 式 计 算 程 序 。 Flink 提 供 了 用 于 流 处 理 的
DataStream API 和用于批处理的 DataSet API。值得注意的是,尽管 Flink Runtime
执行引擎是基于流处理的,但是 DataSet API 先于 DataStream API 被开发出来,这是
因为工业界对无限流处理的需求在 Flink 诞生之初并不大。
DataStream API 可以流畅地分析无限数据流,并且可以用 Java 或者 Scala 来实
现。开发人员需要基于一个叫 DataStream 的数据结构来开发,这个数据结构用于表
示永不停止的分布式数据流。
Flink 的分布式特点体现在它能够在成百上千台机器上运行,它将大型的计算
任务分成许多小的部分,每个机器执行一部分。Flink 能够自动地确保发生机器故障
或者其他错误时计算能够持续进行,或者在修复 bug 或进行版本升级后有计划地再
执行一次。这种能力使得开发人员不需要担心运行失败。Flink 本质上使用容错性数
据流,这使得开发人员可以分析持续生成且永远不结束的数据(即流处理)。
第二章 Flink 基本架构
2.5 JobManager 与 TaskManager
Flink 运行时包含了两种类型的处理器:
JobManager 处理器:也称之为 Master,用于协调分布式执行,它们用来调度 task,
协调检查点,协调失败时恢复等。Flink 运行时至少存在一个 master 处理器,如果配
置高可用模式则会存在多个 master 处理器,它们其中有一个是 leader,而其他的都
是 standby。
TaskManager 处理器:也称之为 Worker,用于执行一个 dataflow 的 task(或者
特殊的 subtask)、数据缓冲和 data stream 的交换,Flink 运行时至少会存在一个 worker
处理器。
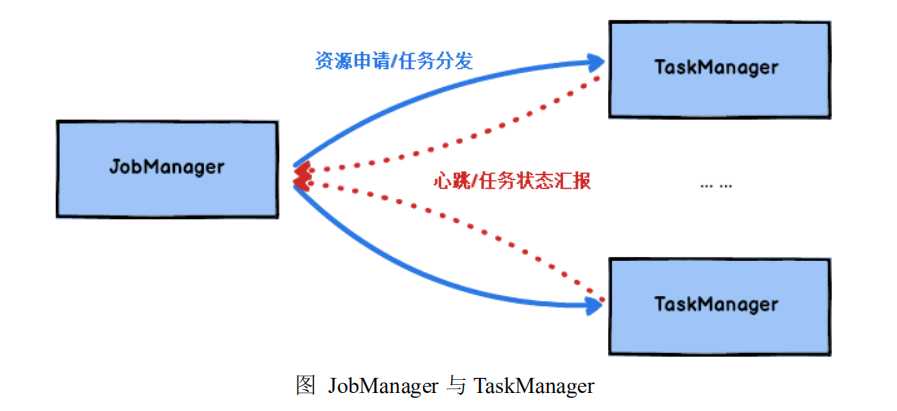
Master 和 Worker 处理器可以直接在物理机上启动,或者通过像 YARN 这样的
资源调度框架。
Worker 连接到 Master,告知自身的可用性进而获得任务分配。
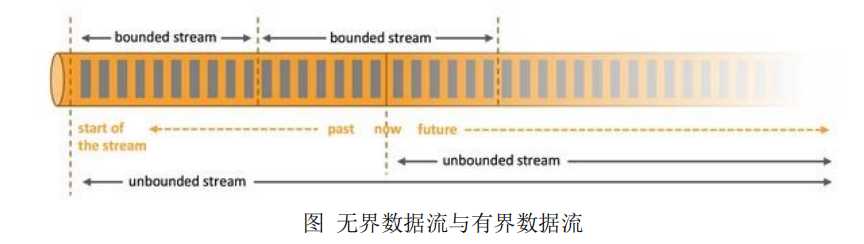
2.1 无界数据流与有界数据流
Flink 用于处理有界和无界数据:
无界数据流:无界数据流有一个开始但是没有结束,它们不会在生成时终止并
提供数据,必须连续处理无界流,也就是说必须在获取后立即处理 event。对于无界
数据流我们无法等待所有数据都到达,因为输入是无界的,并且在任何时间点都不
会完成。处理无界数据通常要求以特定顺序(例如事件发生的顺序)获取 event,以
便能够推断结果完整性,无界流的处理称为流处理。
有界数据流:有界数据流有明确定义的开始和结束,可以在执行任何计算之前
通过获取所有数据来处理有界流,处理有界流不需要有序获取,因为可以始终对有
界数据集进行排序,有界流的处理也称为批处理。
在无界数据流和有界数据流中我们提到了批处理和流处理,这是大数据处理系
统中常见的两种数据处理方式。
批处理的特点是有界、持久、大量,批处理非常适合需要访问全套记录才能完
成的计算工作,一般用于离线统计。流处理的特点是无界、实时,流处理方式无需
针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作,一般用于
实时统计。
在 Spark 生态体系中,对于批处理和流处理采用了不同的技术框架,批处理由
SparkSQL 实现,流处理由 Spark Streaming 实现,这也是大部分框架采用的策略,
使用独立的处理器实现批处理和流处理,而 Flink 可以同时实现批处理和流处理。
Flink 是如何同时实现批处理与流处理的呢?答案是,Flink 将批处理(即处理
有限的静态数据)视作一种特殊的流处理。
Apache Flink 是一个面向分布式数据流处理和批量数据处理的开源计算平台,
它能够基于同一个 Flink 运行时(Flink Runtime),提供支持流处理和批处理两种类
型应用的功能。现有的开源计算方案,会把流处理和批处理作为两种不同的应用类
型,因为它们要实现的目标 是完全不相同的: 流 处 理 一 般 需 要 支 持 低 延 迟 、
Exactly-once 保证,而批处理需要支持高吞吐、高效处理,所以在实现的时候通常
是分别给出两套实现方法,或者通过一个独立的开源框架来实现其中每一种处理方
案。例如,实现批处理的开源方案有 MapReduce、Tez、Crunch、Spark,实现流处
理的开源方案有 Samza、Storm。
Flink 在实现流处理和批处理时,与传统的一些方案完全不同,它从另一个视角
看待流处理和批处理,将二者统一起来:Flink 是完全支持流处理,也就是说作为流
处理看待时输入数据流是无界的;批处理被作为一种特殊的流处理,只是它的输入
数据流被定义为有界的。基于同一个 Flink 运行时(Flink Runtime),分别提供了流处
理和批处理 API,而这两种 API 也是实现上层面向流处理、批处理类型应用框架的
基础。
2.2 数据流编程模型
Flink 提供了不同级别的抽象,以开发流或批处理作业,如下图所示:
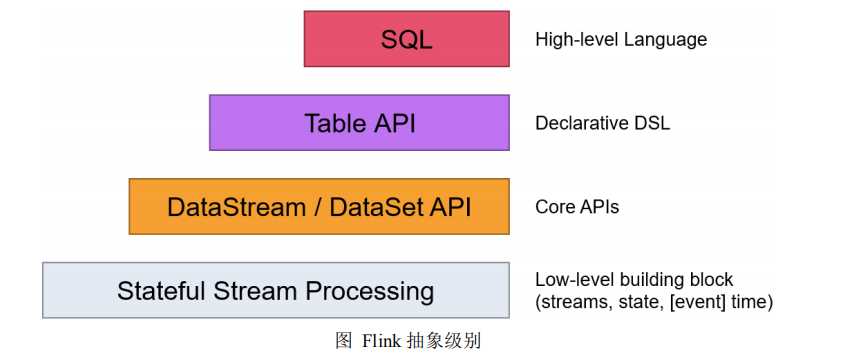
最底层级的抽象仅仅提供了有状态流,它将通过过程函数(Process Function)
被嵌入到 DataStream API 中。底层过程函数(Process Function) 与 DataStream API
相集成,使其可以对某些特定的操作进行底层的抽象,它允许用户可以自由地处理
来自一个或多个数据流的事件,并使用一致的容错的状态。除此之外,用户可以注
册事件时间并处理时间回调,从而使程序可以处理复杂的计算。
实际上,大多数应用并不需要上述的底层抽象,而是针对核心 API(Core APIs)
进行编程,比如 DataStream API(有界或无界流数据)以及 DataSet API(有界数
据集)。这些 API 为数据处理提供了通用的构建模块,比如由用户定义的多种形式
的转换(transformations),连接(joins),聚合(aggregations),窗口操作(windows)
等等。DataSet API 为有界数据集提供了额外的支持,例如循环与迭代。这些 API
处理的数据类型以类(classes)的形式由各
自的编程语言所表示。
Table API 以表为中心,其中表可能会动态变化(在表达流数据时)。Table API
遵循(扩展的)关系模型:表有二维数据结构(schema)(类似于关系数据库中的
表),同时 API 提供可比较的操作,例如 select、project、join、group-by、aggregate
等。Table API 程序声明式地定义了什么逻辑操作应该执行,而不是准确地确定这些
操作代码的看上去如何 。 尽管 Table API 可以通过多种类型的用户自定义函数
(UDF)进行扩展,其仍不如核心 API 更具表达能力,但是使用起来却更加简洁(代
码量更少)。除此之外,Table API 程序在执行之前会经过内置优化器进行优化。
你可以在表与 DataStream/DataSet 之间无缝切换,以允许程序将 Table API
与 DataStream 以及 DataSet 混合使用。
Flink 提供的最高层级的抽象是 SQL 。这一层抽象在语法与表达能力上与
Table API 类似,但是是以 SQL 查询表达式的形式表现程序。SQL 抽象与 Table API
交互密切,同时 SQL 查询可以直接在 Table API 定义的表上执行。
Flink 概述 基本架构
标签:检查 高效 开发人员 上启 reduce 独立 用户 创业公司 性方面
原文地址:https://www.cnblogs.com/LXL616/p/11178409.html