【论文作者】
Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra,
Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, Rohan Anil,
Zakaria Haque, Lichan Hong, Vihan Jain, Xiaobing Liu, Hemal Shah
—— Google Inc.
【论文链接】Paper (4-pages // Double column)
(FY内容待check)
【摘要】
线性模型被广泛地应用于回归和分类问题,具有简单、快速和可解释性等优点,但是线性模型的表达能力有限,经常需要人工选择特征和交叉特征才能取得一个良好的效果,但是实际工程中的特征数量会很多,并且还会有大量的稀疏特征,人工筛选特征和交叉特征会很困难,尤其是交叉高阶特征时,人工很难实现。DNN模型可以很容易的学习到高阶特征之间的作用,并且具有很好的泛化能力。同时,DNN增加embedding层可以很容易的解决稀疏特征的问题。文章将传统的LR和DNN组合构成一个wide&deep模型,既保留了LR的拟合能力,又具有DNN的泛化能力,并且不需要单独训练模型,可以方便模型的迭代。
【关键词】
广泛和深度学习,推荐系统
【1 介绍】
1、Wide&Deep解决什么问题
在推荐系统(包括推荐、计算广告)中,当用户来到平台时,需要向用户展示适合用户的物品(商品、广告等),通常的做法是先从海量的物品库(通常是上亿数量)中,筛选出一些跟用户兴趣最相关的物品(通常是千级规模),这个过程叫做召回,召回可以是机器学习模型或者规则;然后再对这上千的物品进行排序,从而展示给用户。因此推荐系统也经常被叫做搜索排序系统。整个系统流程如图:
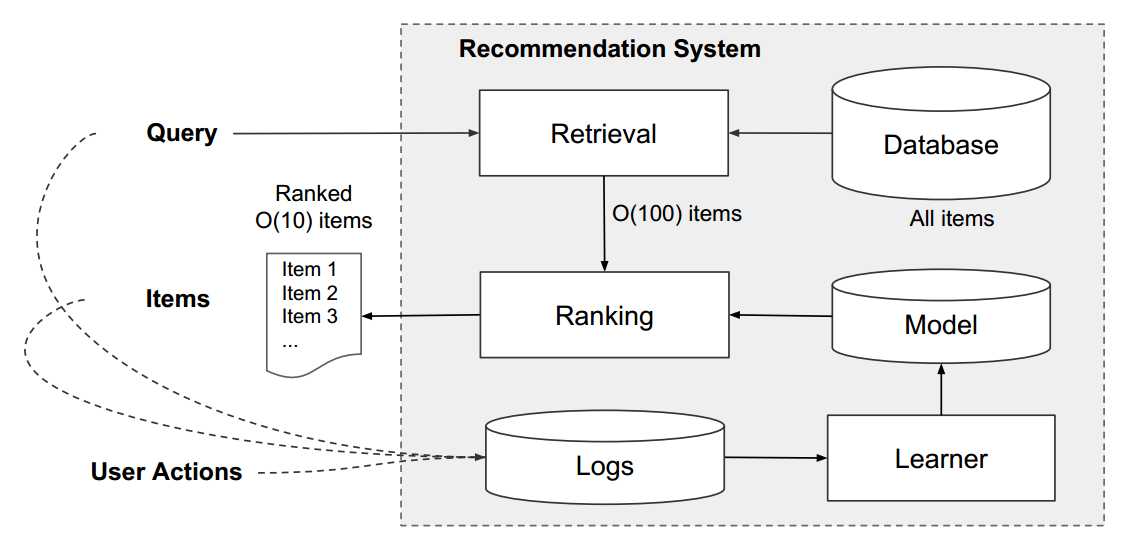
排序的规则有很多,主要是依据业务的目标而言,例如点击、购买等。wide&deep可以应用到此类目标的排序问题中,最经典的就是CTR预估。
2、现有模型的问题
提到CTR预估,最经典的应该是LR模型了,LR模型简单、快速并且模型具有可解释,有着很好的拟合能力,但是LR模型是线性模型,表达能力有限,泛化能力较弱,需要做好特征工程,尤其需要交叉特征,才能取得一个良好的效果,然后工业中,特征的数量会很多,可能达到成千上万,甚至数十万,这时特征工程就很难做,并且特征工程是一项很枯燥乏味的工作,搞得算法工程师晕头转向,还不一定能取得更好的效果。 DNN模型不需要做太精细的特征工程,就可以取得很好的效果,已经在很多领域开始应用了,DNN可以自动交叉特征,学习到特征之间的相互作用,尤其是可以学到高阶特征交互,具有很好的泛化能力。另外,DNN通过增加embedding层,可以有效的解决稀疏数据特征的问题,防止特征爆炸。推荐系统中的泛化能力是很重要的,可以提高推荐物品的多样性,但是DNN在拟合数据上相比较LR会较弱。 为了提高推荐系统的拟合性和泛化性,可以将LR和DNN结合起来,同时增强拟合能力和泛化能力,wide&deep就是将LR和DNN结合起来,wide部分就是LR,deep部分就是DNN,将两者的结果组合进行输出。
【3 Wide&Deep学习(模型)】
wide&deep模型主要分成两部分,wide部分就是传统的LR模型,deep部分就是DNN,整个模型的结构如下图:
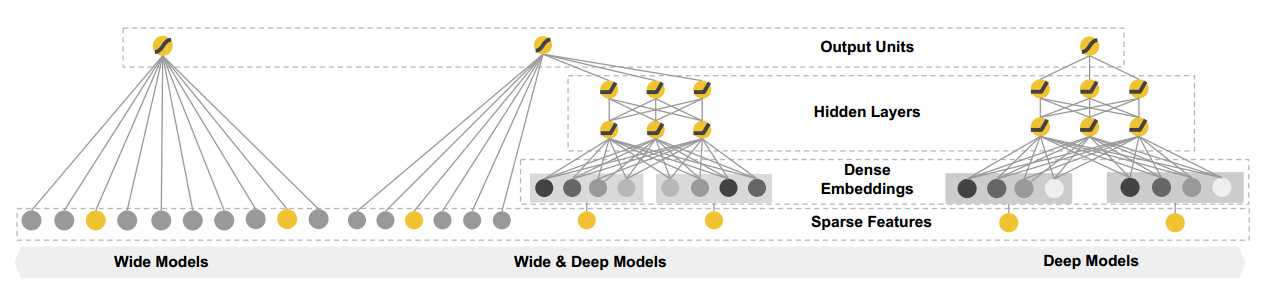
上图中最左边是传统的LR模型,最右边是DNN模型,中间的是将LR和DNN结合起来的wide&deep模型。
【3.1 Wide 部分】
wide部分就是LR模型,传统的LR模型:
用 X=[x1,x2,x3,...,xd] 表示一个有d个特征的样本,W=[w1,w2,w3,...,wd] 表示模型的参数,b表示bia,y表示预测值,有![]()
在实际中往往需要交叉特征,对于这部分定义如下: 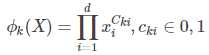
用 ?k 表示第 k 个交叉特征,Cki 表示是第 k 个交叉特征的一部分。
最终的wide部分为:
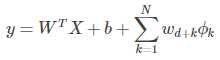
【3.2 Deep 部分】
deep部分就是一个普通的神经网络结构,只不过在这个网络中增加embedding层用来将稀疏、高维的特征转换为低维、密集的实数向量,可以有效地解决维度爆炸。先将原始特征经过embedding层转化后,再送入DNN的隐藏层,隐藏层之间的关系定义为:
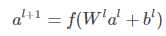
上面 l 表示隐藏层数,f 表示激活函数,可以是sigmoid、Relu、than等,目前最常用的是Relu函数。
【3.3 Wide & Deep 模型的融合训练】
wide&deep模型中,wide部分和deep部分是同时训练的,不需要单独训练任何一部分。GBDT+LR模型中GBDT需要先训练,然后再训练LR,两部分具有依赖关系,这种架构不利于模型的迭代。
Join training和ensemble training的区别:(1)ensemble中每个模型需要单独训练,并且各个模型之间是相互独立的,模型之间互相不感知,当预测样本时,每个模型的结果用于投票,最后选择得票最多的结果。而join train这种方式模型之间不是独立的,是相互影响的,可以同时优化模型的参数。(2)ensemble的方式中往往要求存在很多模型,这样就需要更多的数据集和数据特征,才能取得比较好的效果,模型的增多导致难以训练,不利于迭代。而在wide&deep中,只需要两个模型,训练简单,可以很快的迭代模型。
【4 系统实现】
目前Tensorflow中已经提供了wide&deep模型的API,参见 https://www.tensorflow.org/tutorials/wide_and_deep,并且官方提供了一个Demo,工程上可以很快的搭建起wide&deep模型。
【Reference】
1、https://blog.csdn.net/guozhenqiang19921021/article/details/80871641