标签:ranking false red demo1 filesyste display port 复制 pass
1 python环境的配置
1.1 安装python文件包,放到可以找到的位置
1.2 右键计算机->属性->高级环境设置->系统变量->Path->编辑->复制python路径位置
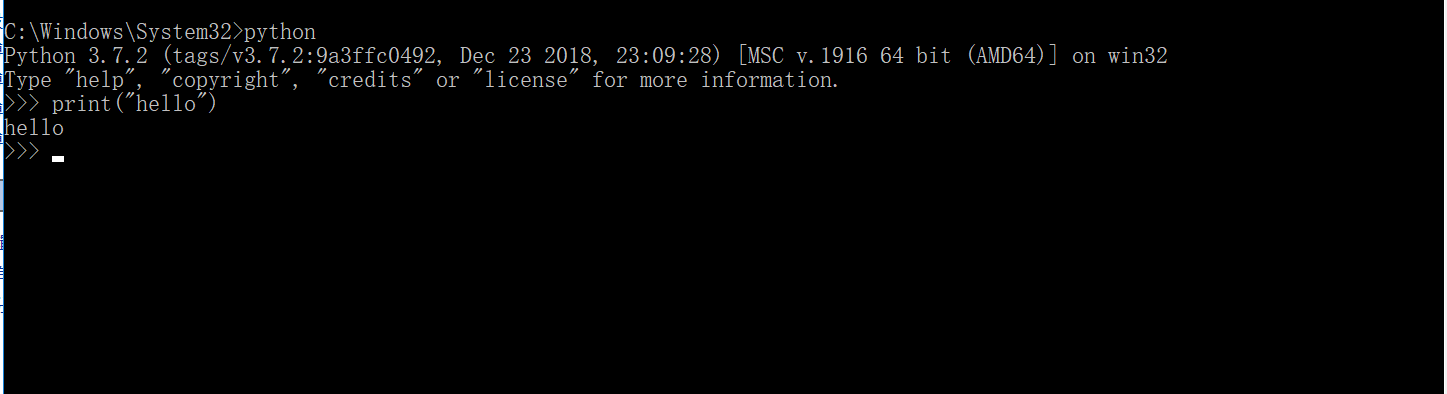
1.3 管理员身份打开cmd,输入python,测试环境是否安装成功
2 安装pycharm
2.1 安装pycharm文件包,放到可以找到的位置
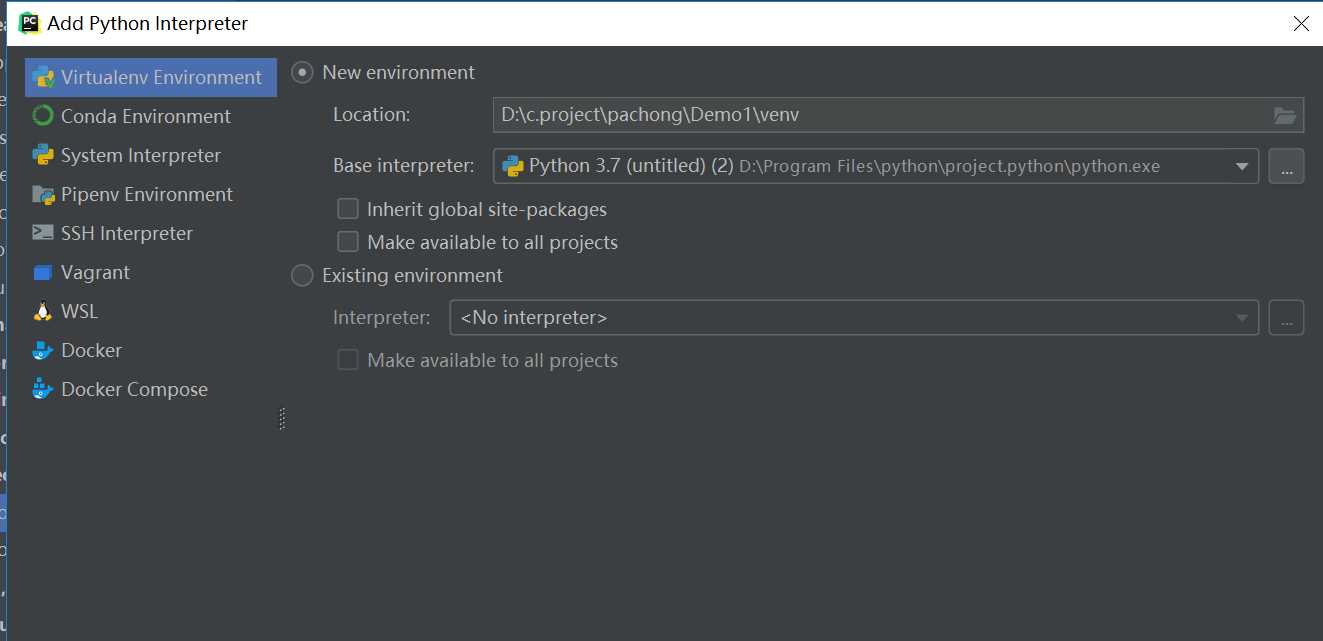
2.2 新建文件夹,需要设置环境
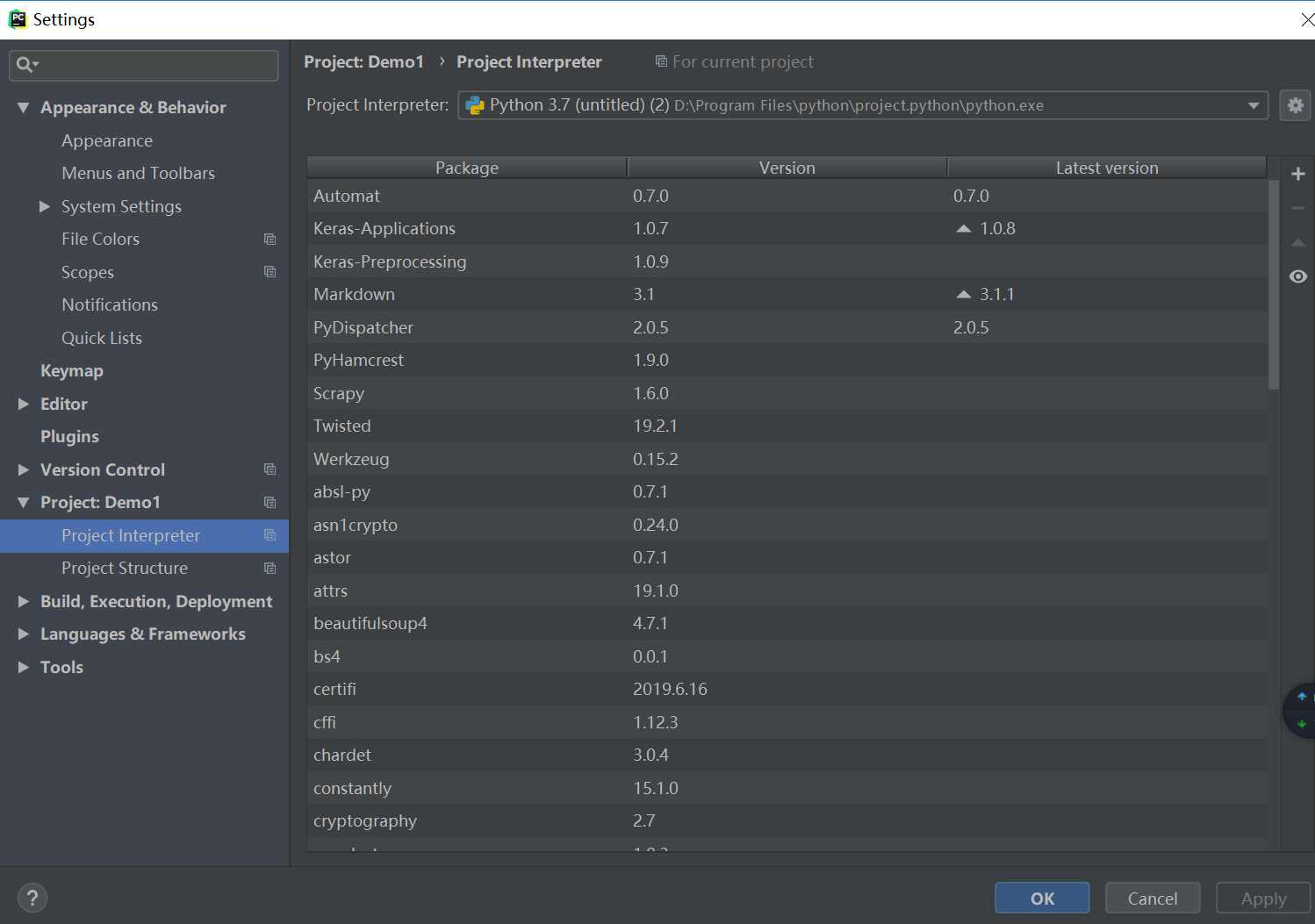
2.3 File->Setting->project ...->add->找到python.exe
2.4 爬虫需要的安装包
2.4.1 打开cmd(管理员身份)
2.4.2 python -m pip install requests
2.4.3 python -m pip install lxml
2.4.4 python -m pip install bs4
2.5爬取数据
2.5.1 打开cmd 输入scrapy startproject Demo(可以先进入存放文件的目录)
2.5.2 打开pycharm打开文件Demo,新建python文件
2.5.3 新建python文件begin.py输入以下命令,运行begin可以实现爬取数据
2.5.4 打开settings.py设置输出文件格式和文件位置以及User_agent
FEED_URI = u‘file:///C:/scrapy/test.csv‘//输出目录
FEED_FORMAT=‘CSV‘
FEED_EXPORT_ENCODING="gb18030"
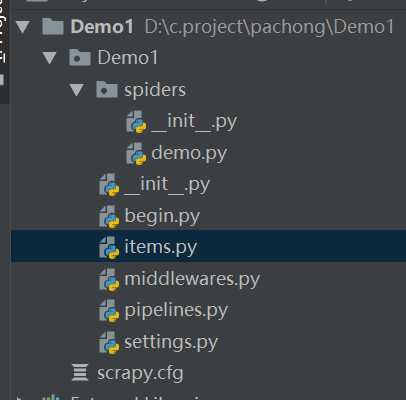
3 以下为总框架图片
4以下为代码
4.1为Demo1.py

1 import scrapy 2 from Demo1.items import Demo1Item 3 from scrapy.http import Request 4 from scrapy.selector import Selector 5 class UestcInfoSpider(scrapy.spiders.Spider): 6 7 #爬虫名 8 name = ‘uestc‘ 9 #设置访问域 10 allowed_domains = [‘ecar168.cn‘] 11 #网页链接、 12 #start_urls = [‘http://data.ecar168.cn/car/959/‘] 13 start_urls = [‘http://www.ecar168.cn/xiaoliang/liebiao/60_0.htm‘] 14 15 def parse1(self,response): 16 item = Demo1Item() 17 selector = Selector(response) 18 news1 = selector.xpath(‘(//tr[@class="yuefen_tr"])‘) 19 for each in news1: 20 item[‘ranking‘] = each.xpath(‘normalize-space(td[1]/text())‘).extract()[0] 21 item[‘manufacturer‘] = each.xpath(‘normalize-space(td[2]/text())‘).extract()[0] 22 item[‘vehicle_type‘] = each.xpath(‘normalize-space(td[3]/text())‘).extract()[0] + each.xpath(‘normalize-space(td[3]/a/text())‘).extract()[0] 23 item[‘monthly_sales_volume‘] = each.xpath(‘normalize-space(td[4]/text())‘).extract()[0] 24 item[‘accumulated_this_year‘] = each.xpath(‘normalize-space(td[5]/text())‘).extract()[0] 25 item[‘last_month‘] = each.xpath(‘normalize-space(td[6]/text())‘).extract()[0] 26 item[‘chain_ratio‘] = each.xpath(‘normalize-space(td[7]/text())‘).extract()[0] 27 item[‘corresponding_period_of_last_year‘] = each.xpath(‘normalize-space(td[8]/text())‘).extract()[0] 28 item[‘year_on_year‘] = each.xpath(‘normalize-space(td[9]/text())‘).extract()[0] 29 item[‘url_title‘] = selector.xpath(‘//div[@id="left"]/div[1]/div[2]/h1/text()‘).extract()[0] 30 # date1= selector.xpath(‘//div[@id="left"]/div[1]/div[2]/h1/text()‘).extract()[0] 31 #item[‘month‘] = (selector.xpath(‘//div[@id="left"]/div[1]/div[3]/text()‘).extract()[0])[3:10] 32 # item[‘web‘] = selector.xpath(‘//div[@id="left"]/div[1]/div[1]/a[3]‘).extract()[0] 33 #item[‘url_href‘] = selector.xpath(‘//div[@id="left"]/div[1]/div[1]/a[1]//@href‘).extract()[0] + selector.xpath(‘//div[@id="left"]/div[1]/div[1]/a[3]//@href‘).extract()[0] 34 series = (selector.xpath(‘//div[@id="left"]/div[1]/div[2]/h1/text()‘).extract()[0]) 35 begin=series.find("月") 36 end=series.find("车") 37 seriestest = series[begin + 1:end] 38 item[‘series‘] = seriestest 39 40 41 item[‘url_car_detail‘] = each.xpath(‘normalize-space(td[3]/a/@href)‘).extract()[0] 42 monthdan = selector.xpath(‘//div[@id="left"]/div[1]/div[2]/h1/text()‘).extract()[0][0:7] 43 44 if monthdan.find("月")==-1: 45 month=monthdan+"月" 46 47 else: month=monthdan 48 item[‘month‘]=month 49 50 yield item 51 52 def parse2(self,response): 53 item = Demo1Item() 54 selector = Selector(response) 55 news = selector.xpath(‘(//ul[@class="biaoti_ul"])‘) 56 for each in news: 57 url2 = ‘http://www.ecar168.cn‘ + each.xpath(‘normalize-space(li[1]/a/@href)‘).extract()[0] 58 print(url2) 59 yield Request(url2,callback=self.parse1) 60 61 62 def parse(self,response): 63 #创建item 64 item = Demo1Item() 65 #分析response 66 selector = Selector(response) 67 news = selector.xpath(‘(//div[@id="jiludaohang"])‘) 68 #i=0 69 #while i <=180: 70 #url=["http://www.ecar168.cn/xiaoliang/liebiao/60_%s.htm"%i] 71 #print(url) 72 #url=‘http://www.ecar168.cn/xiaoliang/liebiao/60_0.htm‘ 73 for each in news: 74 for i in range(3,9) : 75 url=‘http://www.ecar168.cn‘+each.xpath(‘ul/li[%s]/a/@href‘%i).extract()[0] 76 print(url) 77 yield Request(url, callback=self.parse2)
4.2 为bigin.py
1 from scrapy import cmdline 2 3 cmdline.execute("scrapy crawl uestc".split())
4.3 为settings.py
# -*- coding: utf-8 -*- # Scrapy settings for Demo1 project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # https://doc.scrapy.org/en/latest/topics/settings.html # https://doc.scrapy.org/en/latest/topics/downloader-middleware.html # https://doc.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = ‘Demo1‘ SPIDER_MODULES = [‘Demo1.spiders‘] NEWSPIDER_MODULE = ‘Demo1.spiders‘ # Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = ‘Demo1 (+http://www.yourdomain.com)‘ USER_AGENT =‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36‘ # Obey robots.txt rules ROBOTSTXT_OBEY = True # Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0) # See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs #DOWNLOAD_DELAY = 3 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default) #COOKIES_ENABLED = False # Disable Telnet Console (enabled by default) #TELNETCONSOLE_ENABLED = False # Override the default request headers: #DEFAULT_REQUEST_HEADERS = { # ‘Accept‘: ‘text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8‘, # ‘Accept-Language‘: ‘en‘, #} # Enable or disable spider middlewares # See https://doc.scrapy.org/en/latest/topics/spider-middleware.html #SPIDER_MIDDLEWARES = { # ‘Demo1.middlewares.Demo1SpiderMiddleware‘: 543, #} # Enable or disable downloader middlewares # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html #DOWNLOADER_MIDDLEWARES = { # ‘Demo1.middlewares.Demo1DownloaderMiddleware‘: 543, #} # Enable or disable extensions # See https://doc.scrapy.org/en/latest/topics/extensions.html #EXTENSIONS = { # ‘scrapy.extensions.telnet.TelnetConsole‘: None, #} # Configure item pipelines # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html #ITEM_PIPELINES = { # ‘Demo1.pipelines.Demo1Pipeline‘: 300, #} # Enable and configure the AutoThrottle extension (disabled by default) # See https://doc.scrapy.org/en/latest/topics/autothrottle.html #AUTOTHROTTLE_ENABLED = True # The initial download delay #AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies #AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: #AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default) # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings #HTTPCACHE_ENABLED = True #HTTPCACHE_EXPIRATION_SECS = 0 #HTTPCACHE_DIR = ‘httpcache‘ #HTTPCACHE_IGNORE_HTTP_CODES = [] #HTTPCACHE_STORAGE = ‘scrapy.extensions.httpcache.FilesystemCacheStorage‘ FEED_URI = u‘file:///C:/scrapy/Demotest.csv‘ FEED_FORMAT=‘CSV‘ FEED_EXPORT_ENCODING="gb18030"
4.4 为item.py
1 # -*- coding: utf-8 -*- 2 3 # Define here the models for your scraped items 4 # 5 # See documentation in: 6 # https://doc.scrapy.org/en/latest/topics/items.html 7 8 import scrapy 9 10 11 class Demo1Item(scrapy.Item): 12 # define the fields for your item here like: 13 # name = scrapy.Field() 14 manufacturer = scrapy.Field() 15 ranking = scrapy.Field() 16 vehicle_type = scrapy.Field() 17 monthly_sales_volume = scrapy.Field() 18 accumulated_this_year = scrapy.Field() 19 last_month = scrapy.Field() 20 chain_ratio = scrapy.Field() 21 corresponding_period_of_last_year = scrapy.Field() 22 year_on_year = scrapy.Field() 23 url_title = scrapy.Field() 24 month = scrapy.Field() 25 # url_href = scrapy.Field() 26 series = scrapy.Field() 27 url_car_detail = scrapy.Field() 28 29 pass
标签:ranking false red demo1 filesyste display port 复制 pass
原文地址:https://www.cnblogs.com/lwsd/p/11180255.html
