标签:select hdf 程序 hdfs 数据 大数据 path 指定 def
概念
海量数据的数据统计平台,将hql翻译为mapreduce程序。
优点
简单;适用于对实时性要求不严的场合;适合处理大数据
缺点
无法表达迭代式计算;
不擅长数据挖掘;
效率比较低。
本质(相当于hadoop的一个客户端)
hive的数据存储在hdfs;
hive的数据处理在mapreduce;
架构
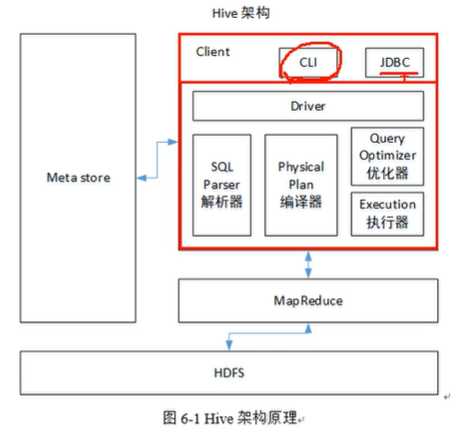
与数据库比较
存储、数据更新、数据处理、数据量
hive交互命令
bin/hive -help
bin/hive -e "select * from student";从命令行获取sql
bin/hive -f hive.hql;从文件获取sql【可以用来做定时任务】
bin/hive -f hive.hql > hiveResult.txt 将查询结果追加到这个文件后面
create table xxx() row format delimited fields delimited by ‘\t‘;
dfs -ls /;查看hdfs文件
! ls /path;查看本地文件
cat .hivehistory ;查看输入的历史命令
hive数据类型
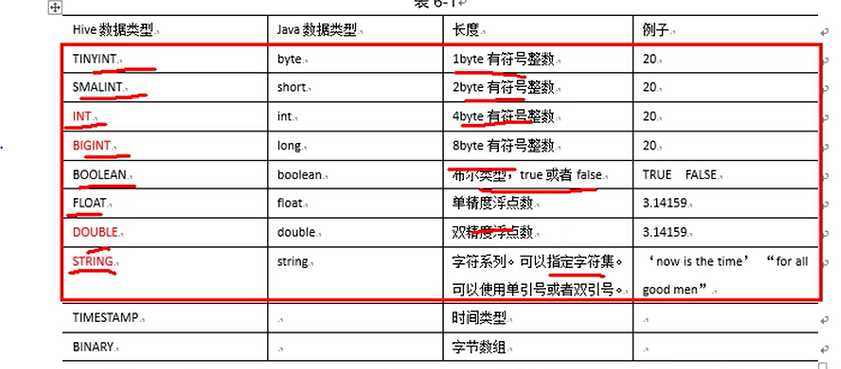
复杂数据类型
struct map array
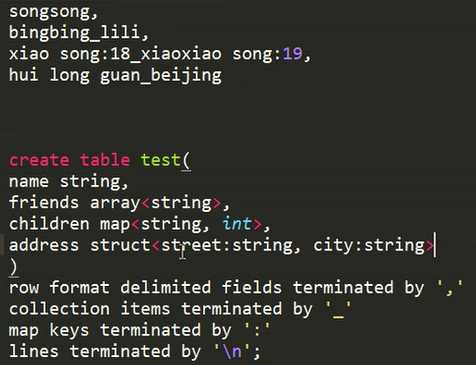
注意:同一个数据类型要用到多个分隔符时,需要先进行数据清洗,将分隔符变成相同的,因为下面只能指定1次。
![]()
类型转化
cast
DDL数据定义
数据倾斜
1.合理设置map数(input的文件总数 文件大小)
每个map处理接近128m的文件块,也不一定就好:如果1个127的文件,如果只有1个或者两个字段,却又几千万的记录,如果map处理的逻辑比较复杂,用一个map任务去做,也会比较耗时;
2.小文件进行合并 combiner
3.复杂文件增加map数
4.合理设置reduce数
最大值:1009 调整:mapered-default.xml
reduce个数不是越多越好
标签:select hdf 程序 hdfs 数据 大数据 path 指定 def
原文地址:https://www.cnblogs.com/NeverGiveUp0/p/11182067.html