标签:from 收录 arch com token odi bdc code 技术
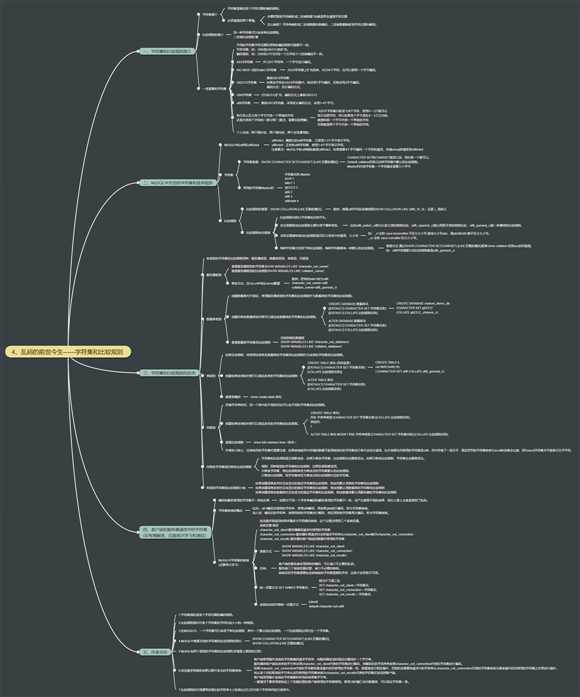
字符集简介
字符集是描述某个字符范围的编码规则。
必须清楚的两个事情。
你要把那些字符映射成二进制数据?也就是界定清楚字符范围
怎么映射?字符串映射成二进制数据叫做编码,二进制数据映射到字符过程叫解码。
比较规则的简介
同一种字符集可以有多种比较规则。
二进制比较规则 略
一些重要的字符集
不同的字符集字符范围和用到的编码规则可能都不一样。
字符范围,如:GBK是GB2312的扩充。
编码规则,如:GBK和UTF8对同一个汉字的十六进制编码不一样。
ASCII字符集
共128个字符串,一个字节进行编码。
ISO 8859-1(别名latin1)字符集
ASCII字符集上扩充而来,共256个字符,也可以使用一个字节编码。
GB2312字符集
兼容ASCII字符集
如果该字符在ASCII字符集中,则采用1字节编码,否则采用2字节编码。
编码方式:变长编码方式。
我们怎么区分某个字节代表一个单独的字符还是代表某个字符的一部分呢?(重点,需要反复理解)
`ASCII`字符集只收录128个字符,使用0~127就可以表示全部字符,所以如果某个字节是在0~127之内的,就意味着一个字节代表一个单独的字符,否则就是两个字节代表一个单独的字符。
GBK字符集:对GB2312扩充,编码方式上兼容GB2312
utf8字符集
兼容ASCII字符集,采用变长编码方式,采用1-4个字节。
个人总结:两个国外的,两个国内的,两个全球通用的。
MySQL中的utf8和utf8mb4
utf8mb3:阉割过的utf8字符集,只使用1-3个字节表示字符。
utf8mb4:正宗的utf8字符集,使用1-4个字节表示字符。
注意要点:MySQL中的utf8指的就是utf8mb3,如果需要4个字节编码一个字符的情况,存储emoji表情使用utf8mb4.
字符集查看:
SHOW (CHARACTER SET|CHARSET) [LIKE 匹配的模式];
CHARACTER SET和CHARSET是同义词,用任意一个都可以。
Default collation列表示这种字符集中默认的比较规则。
Maxlen列代表字符集一个字符最多需要几个字节。
常用的字符集Maxlen列
字符集名称 Maxlen
ascii 1
latin1 1
gb2312 2
gbk 2
utf8 3
utf8mb4 4
比较规则的查看
SHOW COLLATION [LIKE 匹配的模式];
查看utf8字符比较集规则SHOW COLLATION LIKE ‘utf8\_%‘;
注:这里 \_ 是转义
比较规则命名规律
比较规则名称以字符集的名称开头。
后边紧跟着该比较规则主要作用于哪种语言。
比如utf8_polish_ci表示以波兰语的规则比较,utf8_spanish_ci是以西班牙语的规则比较,utf8_general_ci是一种通用的比较规则。
名称后缀意味着该比较规则是否区分语言中的重音、大小写
如:_ci 全称 case insensitive 不区分大小写 如:查询大小写abc,值abc和ABC等不区分大小写。
_cs 全称 case sensitive 区分大小写
其他不理解 略
每种字符集对应若干种比较规则,每种字符集都有一种默认的比较规则。
查看方式 通过SHOW (CHARACTER SET|CHARSET) [LIKE 匹配的模式]或者show collation 找到yes的列查看。
如:utf8字符集默认的比较规则就是utf8_general_ci
各级别的字符集和比较规则四种:服务器级别、数据库级别、表级别、列级别
服务器级别
查看服务器级别的字符集SHOW VARIABLES LIKE ‘character_set_server‘;
查看服务器级别的比较规则SHOW VARIABLES LIKE ‘collation_server‘;
修改方式,在my.cnf中的[server]配置
案例:把我的latin1改为utf8
character_set_server=utf8
collation_server=utf8_general_ci
数据库级别
创建数据库时不指定,使用服务器级别的字符集和比较规则作为数据库的字符集和比较规则。
创建和修改数据库的时候可以指定改数据库的字符集和比较规则
CREATE DATABASE 数据库名
[[DEFAULT] CHARACTER SET 字符集名称]
[[DEFAULT] COLLATE 比较规则名称];
CREATE DATABASE charset_demo_db
CHARACTER SET gb2312
COLLATE gb2312_chinese_ci;
ALTER DATABASE 数据库名
[[DEFAULT] CHARACTER SET 字符集名称]
[[DEFAULT] COLLATE 比较规则名称];
查看数据库字符集和比较规则
切换到指定数据库
SHOW VARIABLES LIKE ‘character_set_database‘;
SHOW VARIABLES LIKE ‘collation_database‘;
表级别
如果没有指明,将使用该表所在数据库的字符集和比较规则作为该表的字符集和比较规则。
创建和修改表的时候可以指定改表的字符集和比较规则。
CREATE TABLE 表名 (列的信息)
[[DEFAULT] CHARACTER SET 字符集名称]
[COLLATE 比较规则名称]]
CREATE TABLE t(
col VARCHAR(10)
) CHARACTER SET utf8 COLLATE utf8_general_ci;
ALTER TABLE 表名
[[DEFAULT] CHARACTER SET 字符集名称]
[COLLATE 比较规则名称]
查看表编码
show create table 表名;
列级别
存储字符串的列,同一个表中的不同的列也可以有不同的字符集和比较规则。
创建和修改表的时候可以指定改列的字符集和比较规则。
CREATE TABLE 表名(
列名 字符串类型 [CHARACTER SET 字符集名称] [COLLATE 比较规则名称],
其他列...
);
ALTER TABLE 表名 MODIFY 列名 字符串类型 [CHARACTER SET 字符集名称] [COLLATE 比较规则名称];
查看比较规则
show full columns from <表名>;
作者的小贴士: 在转换列的字符集时需要注意,如果转换前列中存储的数据不能用转换后的字符集进行表示会发生错误。比方说原先列使用的字符集是utf8,列中存储了一些汉字,现在把列的字符集转换为ascii的话就会出错,因为ascii字符集并不能表示汉字字符。
仅修改字符集或仅修改比较的规则
字符集和比较规则是互相联系的,如果只修改字符集,比较规则也会跟着变化。如果只修改比较规则,字符集也会跟着变化。
规则:四种级别的字符集和比较规则,这两条规则都适用。
只修改字符集,则比较规则将变为修改后的字符集默认的比较规则。
只修改比较规则,则字符集将变为修改后的比较规则对应的字符集。
各级别字符集和比较规则小结
如果创建或修改列时没有显式的指定字符集和比较规则,则该列默认用表的字符集和比较规则
如果创建或修改表时没有显式的指定字符集和比较规则,则该表默认用数据库的字符集和比较规则
如果创建或修改数据库时没有显式的指定字符集和比较规则,则该数据库默认用服务器的字符集和比较规则
编码和解码使用的字符集不一致的后果
如果对于同一个字符串编码和解码使用的字符集不一样,会产生意想不到的结果,我们人看上去就是得到了乱码。
字符集转换的概念
比如:utf-8编码后得到的字符串,使用utf8解码,再按照gbk进行编码,称为字符集转换。
说人话:编码后的字符串,按照同样的字符集进行解码,然后用其他字符集再次编码,称为字符集转换。
MySQL中字符集的转换(还要再次学习)
发送请求到返回结果伴随多次字符集的转换,这个过程会用到三个系统变量
系统变量 描述
character_set_client 服务器解码请求时使用的字符集
character_set_connection 服务器处理请求时会把请求字符串从character_set_client转为character_set_connection
character_set_results 服务器向客户端返回数据时使用的字符集
查看方式:
SHOW VARIABLES LIKE ‘character_set_client‘;
SHOW VARIABLES LIKE ‘character_set_connection‘;
SHOW VARIABLES LIKE ‘character_set_results‘;
总结:
客户端和服务端采用同样的编码,可以减少不必要的乱码。
服务端三个系统变量设置,减少不必要的转码。
转换后的字符集需要包含转换前的字符集里面的字符,这样才会导致不可用。
统一设置的方式:SET NAMES 字符集名;
相当于下面三条
SET character_set_client = 字符集名;
SET character_set_connection = 字符集名;
SET character_set_results = 字符集名;
系统启动的时候统一设置方式
[client]
default-character-set=utf8
比较规则的应用
重点:当自己发现排序机结果和自己想的不一样的时候,思考是不是比较规则的问题。
不好记录,只能靠自己多实践。
1.字符集指的是某个字符范围的编码规则。
2.比较规则是针对某个字符集的字符比较大小的一种规则。
3.在MySQL中,一个字符集可以有若干种比较规则,其中一个默认的比较规则,一个比较规则必须对应一个字符集。
4.MySQL中查看支持的字符集和比较规则的语句
SHOW (CHARACTER SET|CHARSET) [LIKE 匹配的模式];
SHOW COLLATION [LIKE 匹配的模式];
5.MySQL有四个级别的字符集和比较规则(详情看上面我的记录)
6.发送请求到接收结果过程中发生的字符集转换:
客户端使用操作系统的字符集编码请求字符串,向服务器发送的是经过编码的一个字节串。
服务器将客户端发送来的字节串采用character_set_client代表的字符集进行解码,将解码后的字符串再按照character_set_connection代表的字符集进行编码。
如果character_set_connection代表的字符集和具体操作的列使用的字符集一致,则直接进行相应操作,否则的话需要将请求中的字符串从character_set_connection代表的字符集转换为具体操作的列使用的字符集之后再进行操作。
将从某个列获取到的字节串从该列使用的字符集转换为character_set_results代表的字符集后发送到客户端。
客户端使用操作系统的字符集解析收到的结果集字节串。
一般情况下要使用保持这三个变量的值和客户端使用的字符集相同。使用CMD窗口访问数据库,可以保证字符集一致。
7.比较规则的作用通常体现比较字符串大小的表达式以及对某个字符串列进行排序中。
脑图地址:方便有需要的同学高清看
http://naotu.baidu.com/file/17e8e4433f4ac9d2039daf35a9b0bdc1?token=d93cf0acab7b9b3c
标签:from 收录 arch com token odi bdc code 技术
原文地址:https://www.cnblogs.com/jtfr/p/11183087.html