标签:实现 master trait 处理 初始 esc 数据 操作 使用
上篇文章讲到DAGScheduler会把job划分为多个Stage,每个Stage中都会创建一批Task,然后把Task封装为TaskSet提交到TaskScheduler。
这里我们来一起看下TaskScheduler是如何把Task分配到应用程序的Executor上去执行。
重点是这里的task分配算法。
如下图是DagScheduler中把TaskSet提交到TaskScheduler:
这里我们以standalone模式为例,使用的是TaskSchedulerImpl,实现与TaskSchduler这个trait
 ?
?
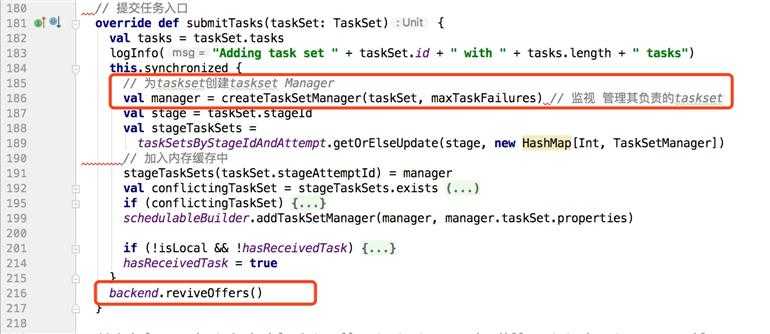
TaskSchedulerImple的submitTasks方法如下:
首先它会为每个taskSet创建一个TaskManager,TaskManager负责管理这个TaskSet(负责Task的重试,处理TaskSet的本地话调度机制等)。
 ?
?
上图中重要的方法是backend.reviveOffers(),这里的backend是初始化SparkContext的时候根据clusterManager的不同创建的backend(这里是 StandaloneSchedulerBackend extends CoarseGrainedSchedulerBackend),backend底层负责底层接受TaskSchedulerImpl的控制,负责Master的注册和Tasks发送到Executor等操作。
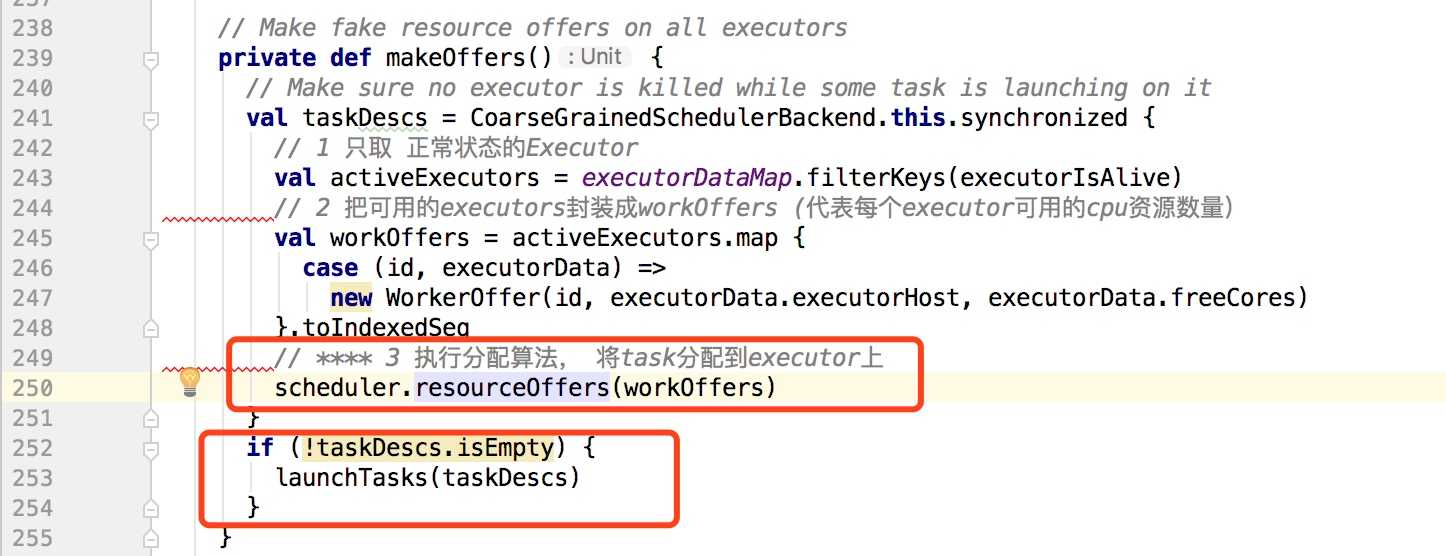
backend.reviveOffers()调用到CoarseGrainedSchedulerBackend的内部类DriverEndpoint的makeOffers, 如下:
 ?
?
makeOffers方法的主要作用是取出所有可用的executor并且计算其可用的资源数量,然后调用resourceOffers把task分配到executor,以下是resourceOffers中的部分代码:
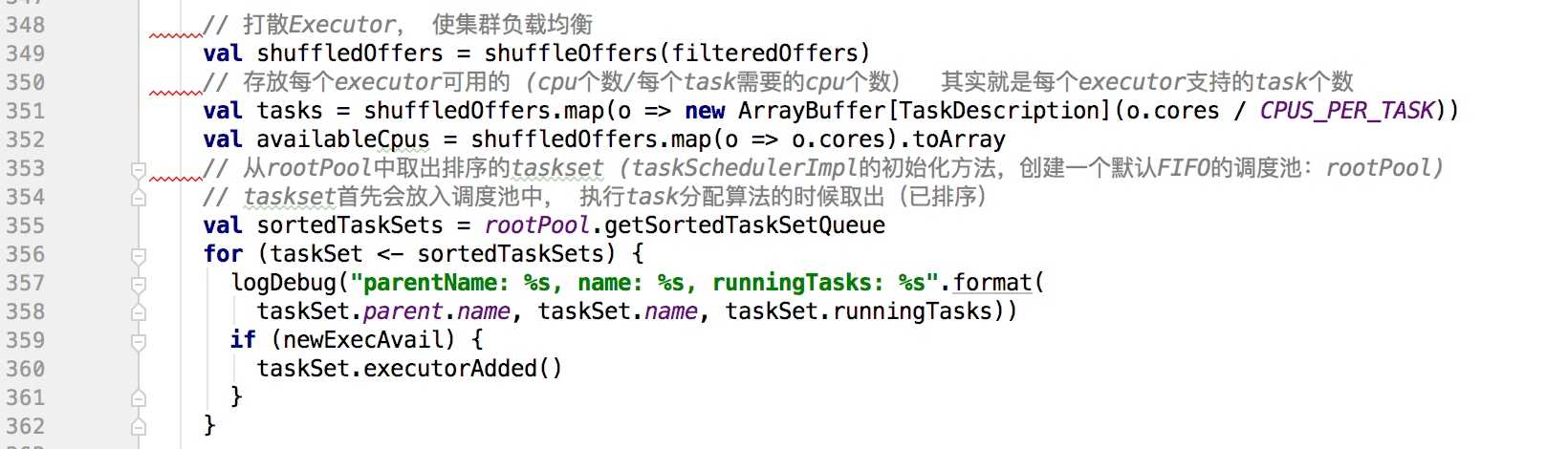 ?
?
按照我们的调度顺序获取每个TaskSet, 然后级别的递增顺序遍历本地化级别, 尝试使用最小的本地化级别启动task
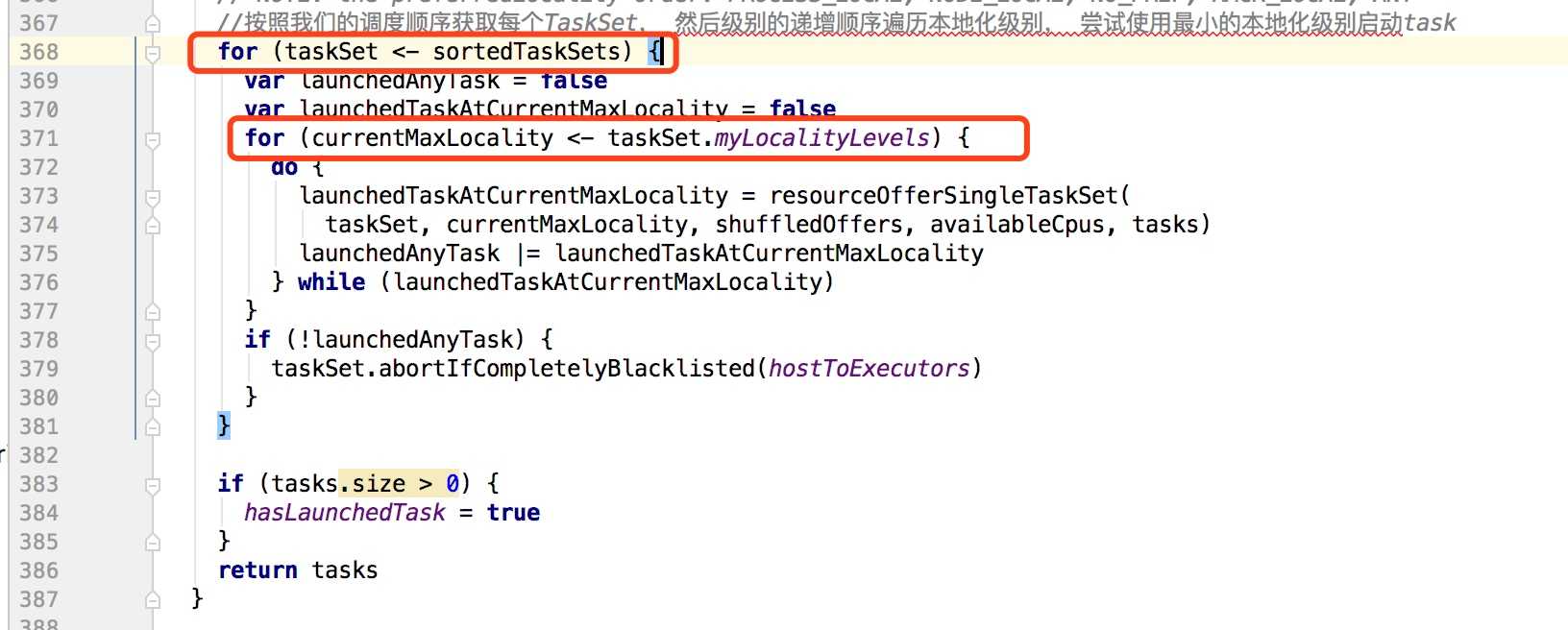 ?
?
本地化级别:
1 PROCESS_LOCAL:进程本地化,rdd对应的分区数据和task在一个executor中,速度最快
2 NODE_LOCAL: 节点本地化,rdd和task不在一个executor中,但是在一个worker上
3 NO_PREF: 无所谓本地化级别
4 RACK_LOCAL:机架本地化, rdd和task在一个机架上。
5 ANY: 任意的本地化级别。
启动任务的时候从最小的本地化级别开始尝试,也就是尽量选择最快的计算方式。
再看一下上图中,内层for循环中的resourceOfferSingleTaskSet方法:
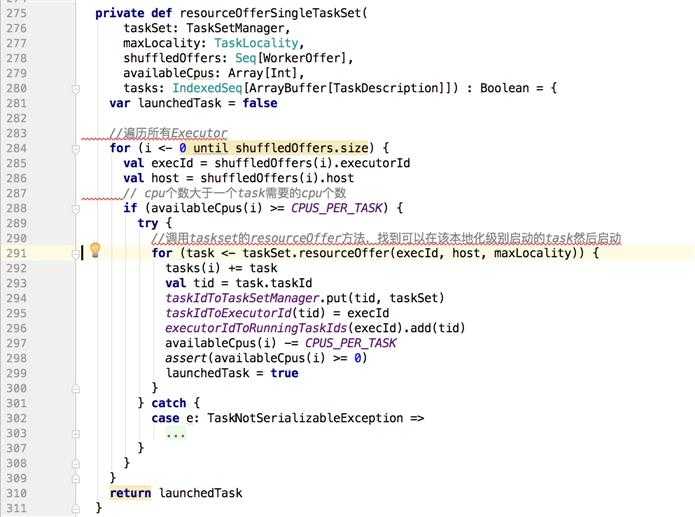 ?
?
以上就是TaskScheduler执行task分配算法的大致过程,感谢阅读。
标签:实现 master trait 处理 初始 esc 数据 操作 使用
原文地址:https://www.cnblogs.com/wangtcc/p/da-huaSpark-9yuan-ma-zhiTaskScheduler.html