标签:home 配置文件 example 文件 top org 去掉 table env
1:安装 Tomcat,解压缩即可。
2:解压 solr。
3:把 solr 下的dist目录solr-4.10.3.war部署到 Tomcat\webapps下(去掉版本号)。
4:启动 Tomcat解压缩 war 包
5:把solr下example/lib/ext 目录下的所有的 jar 包,添加到 solr 的工程中(\WEB-INF\lib目录下)。
6:创建一个 solrhome 。solr 下的/example/solr 目录就是一个 solrhome。复制此目录到D盘改名为solrhome
7:关联 solr 及 solrhome。需要修改 solr 工程的 web.xml 文件。
|
<env-entry> <env-entry-name>solr/home</env-entry-name> <env-entry-value>d:\solrhome</env-entry-value> <env-entry-type>java.lang.String</env-entry-type> </env-entry> |
8:启动 Tomcat
http://IP:8080/solr/
IK Analyzer 是一个开源的,基亍 java 语言开发的轻量级的中文分词工具包。从 2006年 12 月推出 1.0 版开始, IKAnalyzer 已经推出了 4 个大版本。最初,它是以开源项目Luence 为应用主体的,结合词典分词和文法分析算法的中文分词组件。从 3.0 版本开始,IK 发展为面向 Java 的公用分词组件,独立亍 Lucene 项目,同时提供了对 Lucene 的默认优化实现。在 2012 版本中,IK 实现了简单的分词歧义排除算法,标志着 IK 分词器从单纯的词典分词向模拟语义分词衍化。
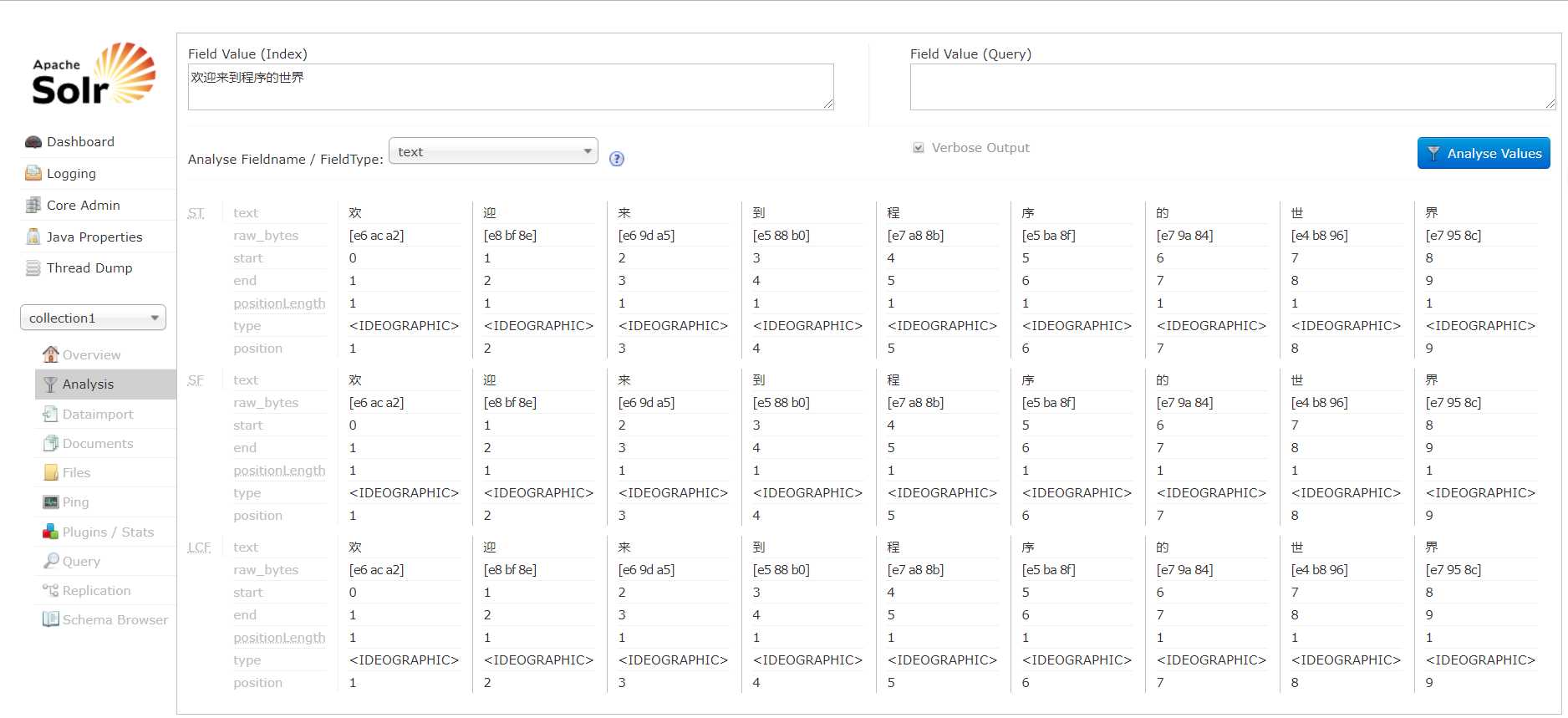
未使用分析器之前
步骤:
1、把IKAnalyzer2012FF_u1.jar 添加到 solr 工程的 lib 目录下
2、创建WEB-INF/classes文件夹 把扩展词典、停用词词典、配置文件放到 solr 工程的 WEB-INF/classes 目录下。
3、修改 Solrhome 的 schema.xml 文件,配置一个 FieldType,使用 IKAnalyzer
|
<fieldType name="text_ik" class="solr.TextField"> <analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType> |
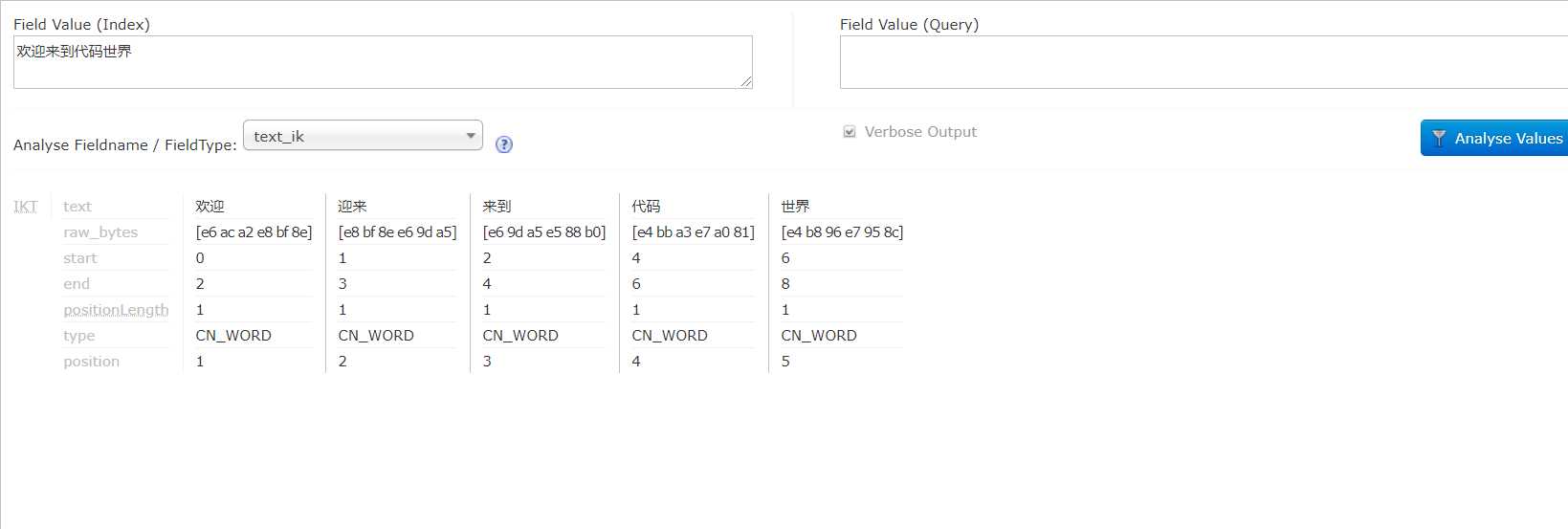
加入后
2019-07-1418:19:44
标签:home 配置文件 example 文件 top org 去掉 table env
原文地址:https://www.cnblogs.com/itboxue/p/11185116.html