标签:ott orm features use 信息 oca net conda mat
参考:
https://blog.csdn.net/u012735708/article/details/82769711
https://zybuluo.com/hanbingtao/note/581764
http://blog.sina.com.cn/s/blog_afc8730e0102xup1.html
https://blog.csdn.net/qq_30638831/article/details/80060045
执行代码:
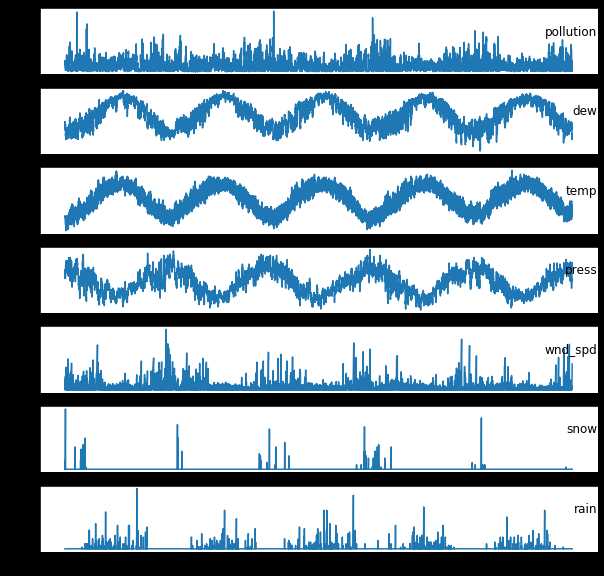
import pandas as pd from datetime import datetime from matplotlib import pyplot from sklearn.preprocessing import LabelEncoder,MinMaxScaler from sklearn.metrics import mean_squared_error from keras.models import Sequential from keras.layers import Dense from keras.layers import LSTM from numpy import concatenate from math import sqrt # load data def parse(x): return datetime.strptime(x, ‘%Y %m %d %H‘) def read_raw(): dataset = pd.read_csv(‘C:/Users/cf_pc/Documents/jupyter/data/PRSA_data_2010.1.1-2014.12.31.csv‘, parse_dates = [[‘year‘, ‘month‘, ‘day‘, ‘hour‘]], index_col=0, date_parser=parse) dataset.drop(‘No‘, axis=1, inplace=True) # manually specify column names dataset.columns = [‘pollution‘, ‘dew‘, ‘temp‘, ‘press‘, ‘wnd_dir‘, ‘wnd_spd‘, ‘snow‘, ‘rain‘] dataset.index.name = ‘date‘ # mark all NA values with 0 dataset[‘pollution‘].fillna(0, inplace=True) # drop the first 24 hours dataset = dataset[24:] # summarize first 5 rows print(dataset.head(5)) # save to file dataset.to_csv(‘C:/Users/cf_pc/Documents/jupyter/data/pollution.csv‘) def drow_pollution(): dataset = pd.read_csv(‘C:/Users/cf_pc/Documents/jupyter/data/pollution.csv‘, header=0, index_col=0) values = dataset.values # specify columns to plot groups = [0, 1, 2, 3, 5, 6, 7] i = 1 # plot each column pyplot.figure(figsize=(10,10)) for group in groups: pyplot.subplot(len(groups), 1, i) pyplot.plot(values[:, group]) pyplot.title(dataset.columns[group], y=0.5, loc=‘right‘) i += 1 pyplot.show() def series_to_supervised(data, n_in=1, n_out=1, dropnan=True): # convert series to supervised learning n_vars = 1 if type(data) is list else data.shape[1] df = pd.DataFrame(data) cols, names = list(), list() # input sequence (t-n, ... t-1) for i in range(n_in, 0, -1): cols.append(df.shift(i)) names += [(‘var%d(t-%d)‘ % (j+1, i)) for j in range(n_vars)] # forecast sequence (t, t+1, ... t+n) for i in range(0, n_out): cols.append(df.shift(-i)) if i == 0: names += [(‘var%d(t)‘ % (j+1)) for j in range(n_vars)] else: names += [(‘var%d(t+%d)‘ % (j+1, i)) for j in range(n_vars)] # put it all together agg = pd.concat(cols, axis=1) agg.columns = names # drop rows with NaN values if dropnan: agg.dropna(inplace=True) return agg def cs_to_sl(): # load dataset dataset = pd.read_csv(‘C:/Users/cf_pc/Documents/jupyter/data/pollution.csv‘, header=0, index_col=0) values = dataset.values # integer encode direction encoder = LabelEncoder() values[:,4] = encoder.fit_transform(values[:,4]) # ensure all data is float values = values.astype(‘float32‘) # normalize features scaler = MinMaxScaler(feature_range=(0, 1)) scaled = scaler.fit_transform(values) # frame as supervised learning reframed = series_to_supervised(scaled, 1, 1) # drop columns we don‘t want to predict reframed.drop(reframed.columns[[9,10,11,12,13,14,15]], axis=1, inplace=True) print(reframed.head()) return reframed,scaler def train_test(reframed): # split into train and test sets values = reframed.values n_train_hours = 365 * 24 train = values[:n_train_hours, :] test = values[n_train_hours:, :] # split into input and outputs train_X, train_y = train[:, :-1], train[:, -1] test_X, test_y = test[:, :-1], test[:, -1] # reshape input to be 3D [samples, timesteps, features] train_X = train_X.reshape((train_X.shape[0], 1, train_X.shape[1])) test_X = test_X.reshape((test_X.shape[0], 1, test_X.shape[1])) print(train_X.shape, train_y.shape, test_X.shape, test_y.shape) return train_X,train_y,test_X,test_y def fit_network(train_X,train_y,test_X,test_y,scaler): model = Sequential() model.add(LSTM(50, input_shape=(train_X.shape[1], train_X.shape[2]))) model.add(Dense(1)) model.compile(loss=‘mae‘, optimizer=‘adam‘) # fit network history = model.fit(train_X, train_y, epochs=50, batch_size=72, validation_data=(test_X, test_y), verbose=2, shuffle=False) # plot history pyplot.plot(history.history[‘loss‘], label=‘train‘) pyplot.plot(history.history[‘val_loss‘], label=‘test‘) pyplot.legend() pyplot.show() # make a prediction yhat = model.predict(test_X) test_X = test_X.reshape((test_X.shape[0], test_X.shape[2])) # invert scaling for forecast inv_yhat = concatenate((yhat, test_X[:, 1:]), axis=1) inv_yhat = scaler.inverse_transform(inv_yhat) inv_yhat = inv_yhat[:,0] # invert scaling for actual inv_y = scaler.inverse_transform(test_X) inv_y = inv_y[:,0] # calculate RMSE rmse = sqrt(mean_squared_error(inv_y, inv_yhat)) print(‘Test RMSE: %.3f‘ % rmse) if __name__ == ‘__main__‘: drow_pollution() reframed,scaler = cs_to_sl() train_X,train_y,test_X,test_y = train_test(reframed) fit_network(train_X,train_y,test_X,test_y,scaler)
返回信息:
var1(t-1) var2(t-1) var3(t-1) var4(t-1) var5(t-1) var6(t-1) 1 0.129779 0.352941 0.245902 0.527273 0.666667 0.002290 2 0.148893 0.367647 0.245902 0.527273 0.666667 0.003811 3 0.159960 0.426471 0.229508 0.545454 0.666667 0.005332 4 0.182093 0.485294 0.229508 0.563637 0.666667 0.008391 5 0.138833 0.485294 0.229508 0.563637 0.666667 0.009912 var7(t-1) var8(t-1) var1(t) 1 0.000000 0.0 0.148893 2 0.000000 0.0 0.159960 3 0.000000 0.0 0.182093 4 0.037037 0.0 0.138833 5 0.074074 0.0 0.109658 (8760, 1, 8) (8760,) (35039, 1, 8) (35039,) WARNING:tensorflow:From C:\3rd\Anaconda2\lib\site-packages\tensorflow\python\framework\op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version. Instructions for updating: Colocations handled automatically by placer. WARNING:tensorflow:From C:\3rd\Anaconda2\lib\site-packages\tensorflow\python\ops\math_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version. Instructions for updating: Use tf.cast instead. Train on 8760 samples, validate on 35039 samples Epoch 1/50 - 2s - loss: 0.0578 - val_loss: 0.0562 Epoch 2/50 - 1s - loss: 0.0413 - val_loss: 0.0563 Epoch 3/50 - 1s - loss: 0.0254 - val_loss: 0.0454 Epoch 4/50 - 1s - loss: 0.0179 - val_loss: 0.0388 Epoch 5/50 - 1s - loss: 0.0158 - val_loss: 0.0237 Epoch 6/50 - 1s - loss: 0.0149 - val_loss: 0.0175 Epoch 7/50 - 1s - loss: 0.0148 - val_loss: 0.0163 Epoch 8/50 - 1s - loss: 0.0147 - val_loss: 0.0160 Epoch 9/50 - 1s - loss: 0.0148 - val_loss: 0.0155 Epoch 10/50 - 1s - loss: 0.0147 - val_loss: 0.0151 Epoch 11/50 - 1s - loss: 0.0146 - val_loss: 0.0148 Epoch 12/50 - 1s - loss: 0.0147 - val_loss: 0.0145 Epoch 13/50 - 1s - loss: 0.0146 - val_loss: 0.0143 Epoch 14/50 - 1s - loss: 0.0146 - val_loss: 0.0143 Epoch 15/50 - 1s - loss: 0.0145 - val_loss: 0.0141 Epoch 16/50 - 1s - loss: 0.0145 - val_loss: 0.0144 Epoch 17/50 - 1s - loss: 0.0147 - val_loss: 0.0140 Epoch 18/50 - 1s - loss: 0.0145 - val_loss: 0.0140 Epoch 19/50 - 1s - loss: 0.0145 - val_loss: 0.0138 Epoch 20/50 - 1s - loss: 0.0145 - val_loss: 0.0138 Epoch 21/50 - 1s - loss: 0.0144 - val_loss: 0.0138 Epoch 22/50 - 1s - loss: 0.0145 - val_loss: 0.0138 Epoch 23/50 - 1s - loss: 0.0146 - val_loss: 0.0137 Epoch 24/50 - 1s - loss: 0.0144 - val_loss: 0.0137 Epoch 25/50 - 1s - loss: 0.0144 - val_loss: 0.0137 Epoch 26/50 - 1s - loss: 0.0144 - val_loss: 0.0136 Epoch 27/50 - 1s - loss: 0.0144 - val_loss: 0.0136 Epoch 28/50 - 1s - loss: 0.0144 - val_loss: 0.0136 Epoch 29/50 - 1s - loss: 0.0145 - val_loss: 0.0137 Epoch 30/50 - 1s - loss: 0.0145 - val_loss: 0.0136 Epoch 31/50 - 1s - loss: 0.0144 - val_loss: 0.0137 Epoch 32/50 - 1s - loss: 0.0144 - val_loss: 0.0136 Epoch 33/50 - 1s - loss: 0.0144 - val_loss: 0.0136 Epoch 34/50 - 1s - loss: 0.0145 - val_loss: 0.0136 Epoch 35/50 - 1s - loss: 0.0144 - val_loss: 0.0135 Epoch 36/50 - 1s - loss: 0.0144 - val_loss: 0.0135 Epoch 37/50 - 1s - loss: 0.0144 - val_loss: 0.0135 Epoch 38/50 - 1s - loss: 0.0144 - val_loss: 0.0135 Epoch 39/50 - 1s - loss: 0.0144 - val_loss: 0.0135 Epoch 40/50 - 1s - loss: 0.0144 - val_loss: 0.0135 Epoch 41/50 - 1s - loss: 0.0143 - val_loss: 0.0135 Epoch 42/50 - 1s - loss: 0.0144 - val_loss: 0.0135 Epoch 43/50 - 1s - loss: 0.0144 - val_loss: 0.0135 Epoch 44/50 - 1s - loss: 0.0144 - val_loss: 0.0135 Epoch 45/50 - 1s - loss: 0.0144 - val_loss: 0.0137 Epoch 46/50 - 1s - loss: 0.0144 - val_loss: 0.0136 Epoch 47/50 - 1s - loss: 0.0143 - val_loss: 0.0135 Epoch 48/50 - 1s - loss: 0.0144 - val_loss: 0.0136 Epoch 49/50 - 1s - loss: 0.0143 - val_loss: 0.0135 Epoch 50/50 - 1s - loss: 0.0144 - val_loss: 0.0134

Test RMSE: 4.401
参考:
https://www.cnblogs.com/tianrunzhi/p/7825671.html
https://www.cnblogs.com/king-lps/p/7846414.html
https://www.cnblogs.com/datablog/p/6127000.html
https://www.cnblogs.com/charlotte77/p/5622325.html
https://www.cnblogs.com/bawu/p/7701810.html
标签:ott orm features use 信息 oca net conda mat
原文地址:https://www.cnblogs.com/ratels/p/11186636.html