标签:baseline 读取 时间 inf 功能区 multi 串处理 com col
阅读顺序
visit2array.py
tfrecord.py
model.py
train.py
test.py
详细过程
****************************************************************************
visit2array.py:此文件功能为提取数据集中训练集、验证集、测试集中文本信息
加载训练集(验证集、测试集与此类似):
1. 预处理的train.txt文件中包括所有训练集图片的位置(路径+图片名),由于图片对应的文本信息与图片名相同,因此通过字符串处理函数得到每一个文本文件的文件名。
打开文本文件后文本信息如下:

每一个.txt文件对应一张图片,名称相同,txt文件为对应图片中所有出现的用户及其出现的时间。
\t前:用户名,\t后:&前为日期,&后为小时,同一天中不同时间用 | 隔开。
2. 文本文件中的信息将通过visit2array()函数处理
获取除用户名以外的所有信息(时间信息)。
遍历每条信息,以逗号为分界线将每条中每天的信息单独作处理,使用temp列表,每一行存储日期和时刻。
如一条信息为20190106&21|22,20190316&12|13|14|15|16|17|18|19|20|21|22,则分成20190106&21|22和20190316&12|13|14|15|16|17|18|19|20|21|22。
若一个item为20181221&09|10|11|12|13|14|15,则日期为item[0:8],时刻为item[9:].split("|")。
temp:
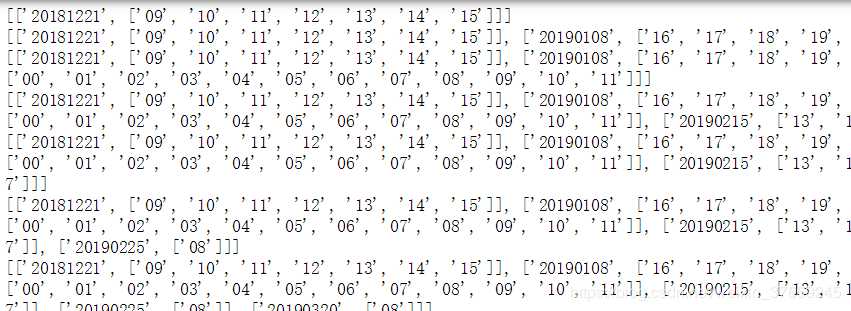
设置天、周、时刻次数的三维数组,数组的值为某时刻对应的访问次数,初始化该数组值为0。
即对temp进行遍历,将具体日期对应为第几周的第几天,再加上第三维时刻信息,每访问到对此值增1,遍历完成后得到的三维数组为在训练中用到的文本信息。
将此三维数组存储于.npy文件中。
*****************************************************************************************
tfrecord.py:此文件功能为将多模态的数据处理为统一可训练的数据,统一访问与使用
训练集的处理(验证集测试集与此类似):
1.首先通过get_data()函数获取数据信息。与上述获取文件信息的过程相同,预处理的文件中包括所有训练集图片的位置(路径+图片名),通过字符串处理函数获取图片及其文本文件名。
2.对于每一个文件,通过cv2.imread()函数将图片三通道信息转换为数值存储在image数组中,加载在visit2array.py文件中存储的文本信息存储在visit数组中,通过label存储该图片所处的城市功能区类别。
3.将上述三个信息存于列表data中,并在转换为合适格式后输出到.tfrecord文件中保存。
*****************************************************************************************
model.py:此文件功能为设计模型
1. baseline中用到的模型为cnn,在类MultiModal中定义。
2. 类中self.image,self.visit,self.label分别代表图片信息,文本信息,标签(所属功能区)。
3. 先将图像、文本信息通过cnn的卷积层、池化层、激活函数等训练,得到其扁平化后的值。
4. 将上述扁平化后的值通过tf.concat()函数连接,再加上label的值全连接输出。
*****************************************************************************************
train.py:此文件功能为训练模型
1. 首先读取.tfrecord中的信息,将图像、文本、标签信息单独存储在数组中。
2. 通过tr.train.shuffle_batch()函数将数据打乱顺序并选取较小的大小。
3. 通过session.run()函数将图像、文本、标签信息作为参数传递给model,开始训练。
标签:baseline 读取 时间 inf 功能区 multi 串处理 com col
原文地址:https://www.cnblogs.com/komorabi/p/11192319.html