标签:com 下载器 文件 inf process sync http服务 运行 when
我们接着关于爬虫平台的架构实现和框架的选型(一)继续来讲爬虫框架的架构实现和狂阶的选型。
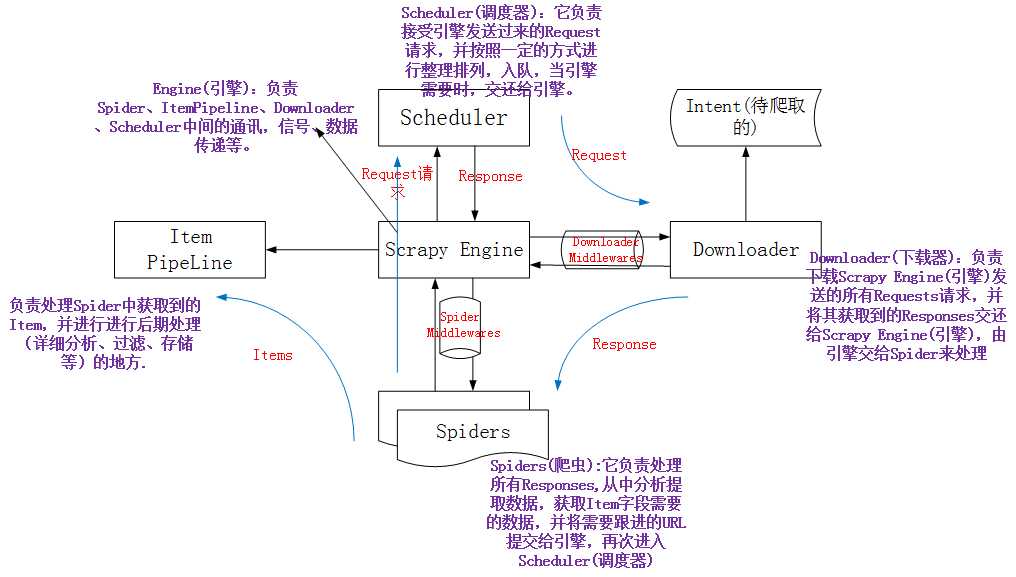
前面介绍了scrapy的基本操作,下面介绍下scrapy爬虫的内部实现架构如下图
1、Spiders(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)
2、Engine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
3、Scheduler(调度器):它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
4、Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理
5、ItemPipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
6、Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
7、Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)。
Scrapy 爬虫整过处理的过程如下:

每一个用scrapy创建的爬虫项目都会生成一个middlewares.py文件,在这个文件中定义了两个处理中间件SpiderMiddleware和DownloaderMiddleware,这两个中间件分别负责请求前的过滤和请求后的response过滤。
上面介绍了基于scrapy的异步爬虫,下面介绍一下实时爬虫,也就是爬虫数据实时返回。
我们可以用requests+BeautifulSoup来进行实现。
Requests负责网页的请求,BeautifulSoup负责对请求完的网页进行网页解析。
下面的代码是一个爬取应用宝中理财类APP的名称的爬虫代码实现

# -*- coding: utf-8 -*- import requests from bs4 import BeautifulSoup import time class SyncCrawlSjqq(object): def parser(self,url): req = requests.get(url) soup = BeautifulSoup(req.text,"lxml") name_list = soup.find(class_=‘app-list clearfix‘)(‘li‘) names=[] for name in name_list: app_name = name.find(‘a‘,class_="name ofh").text names.append(app_name) return names if __name__ == ‘__main__‘: syncCrawlSjqq = SyncCrawlSjqq() t1 = time.time() url = "https://sj.qq.com/myapp/category.htm?orgame=1&categoryId=114" print(syncCrawlSjqq.parser(url)) t2 = time.time() print(‘一般方法,总共耗时:%s‘ % (t2 - t1))
运行结果如下
D:\python\Python3\python.exe D:/project/python/zj_scrapy/zj_scrapy/SyncCrawlSjqq.py
[‘宜人贷借款‘, ‘大智慧‘, ‘中国建设银行‘, ‘同花顺手机炒股股票软件‘, ‘随手记理财记账‘, ‘平安金管家‘, ‘翼支付‘, ‘第一理财‘, ‘平安普惠‘, ‘51信用卡管家‘, ‘借贷宝‘, ‘卡牛信用管家‘, ‘省呗‘, ‘平安口袋银行‘, ‘拍拍贷借款‘, ‘简理财‘, ‘中国工商银行‘, ‘PPmoney出借‘, ‘360借条‘, ‘京东金融‘, ‘招商银行‘, ‘云闪付‘, ‘腾讯自选股(腾讯官方炒股软件)‘, ‘鑫格理财‘, ‘中国银行手机银行‘, ‘风车理财‘, ‘招商银行掌上生活‘, ‘360贷款导航‘, ‘农行掌上银行‘, ‘现金巴士‘, ‘趣花分期‘, ‘挖财记账‘, ‘闪银‘, ‘极速现金侠‘, ‘小花钱包‘, ‘闪电借款‘, ‘光速贷款‘, ‘借花花贷款‘, ‘捷信金融‘, ‘分期乐‘]
一般方法,总共耗时:0.3410000801086426
Process finished with exit code 0
我们可以采用flask web 框架对上面的方法做一个http 服务,然后上面的爬虫就变成了http爬虫服务了。调用http服务后,服务实时返回爬取的数据给http请求调用方。
并发方法可以使用多线程来加速一般方法,我们使用的并发模块为concurrent.futures模块,设置多线程的个数为20个(实际不一定能达到,视计算机而定)。实现的示例代码如下:
# -*- coding: utf-8 -*- from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED import requests from bs4 import BeautifulSoup import time class SyncCrawlSjqqMultiProcessing(object): def parser(self,url): req = requests.get(url) soup = BeautifulSoup(req.text,"lxml") name_list = soup.find(class_=‘app-list clearfix‘)(‘li‘) names=[] for name in name_list: app_name = name.find(‘a‘,class_="name ofh").text names.append(app_name) return names if __name__ == ‘__main__‘: url = "https://sj.qq.com/myapp/category.htm?orgame=1&categoryId=114" executor = ThreadPoolExecutor(max_workers=20) syncCrawlSjqqMultiProcessing = SyncCrawlSjqqMultiProcessing() t1 = time.time() future_tasks=[executor.submit(print(syncCrawlSjqqMultiProcessing.parser(url)))] wait(future_tasks, return_when=ALL_COMPLETED) t2 = time.time() print(‘一般方法,总共耗时:%s‘ % (t2 - t1))
运行结果如下:
D:\python\Python3\python.exe D:/project/python/zj_scrapy/zj_scrapy/SyncCrawlSjqqMultiProcessing.py
[‘宜人贷借款‘, ‘大智慧‘, ‘中国建设银行‘, ‘同花顺手机炒股股票软件‘, ‘随手记理财记账‘, ‘平安金管家‘, ‘翼支付‘, ‘第一理财‘, ‘平安普惠‘, ‘51信用卡管家‘, ‘借贷宝‘, ‘卡牛信用管家‘, ‘省呗‘, ‘平安口袋银行‘, ‘拍拍贷借款‘, ‘简理财‘, ‘中国工商银行‘, ‘PPmoney出借‘, ‘360借条‘, ‘京东金融‘, ‘招商银行‘, ‘云闪付‘, ‘腾讯自选股(腾讯官方炒股软件)‘, ‘鑫格理财‘, ‘中国银行手机银行‘, ‘风车理财‘, ‘招商银行掌上生活‘, ‘360贷款导航‘, ‘农行掌上银行‘, ‘现金巴士‘, ‘趣花分期‘, ‘挖财记账‘, ‘闪银‘, ‘极速现金侠‘, ‘小花钱包‘, ‘闪电借款‘, ‘光速贷款‘, ‘借花花贷款‘, ‘捷信金融‘, ‘分期乐‘]
一般方法,总共耗时:0.3950002193450928
Process finished with exit code 0
比如单线程运行,多线程在爬虫时明显会要快很多。
关于爬虫平台的架构实现和框架的选型(二)--scrapy的内部实现以及实时爬虫的实现
标签:com 下载器 文件 inf process sync http服务 运行 when
原文地址:https://www.cnblogs.com/laoqing/p/11195324.html