标签:链接 最大的 use 算法 记录 表数据 热门话题 inf 行数据
缓存击穿实际上是缓存雪崩的一个特例,大家使用过微博的应该都知道,微博有一个热门话题的功能,用户对于热门话题的搜索量往往在一些时刻会大大的高于其他话题,这种我们成为系统的“热点“,由于系统中对这些热点的数据缓存也存在失效时间,在热点的缓存到达失效时间时,此时可能依然会有大量的请求到达系统,没有了缓存层的保护,这些请求同样的会到达db从而可能引起故障。击穿与雪崩的区别即在于击穿是对于特定的热点数据来说,而雪崩是全部数据。
二级缓存:对于热点数据进行二级缓存,并对于不同级别的缓存设定不同的失效时间,则请求不会直接击穿缓存层到达数据库。
这里参考了阿里双11万亿流量的缓存击穿解决方案,解决此问题的关键在于热点访问。由于热点可能随着时间的变化而变化,针对固定的数据进行特殊缓存是不能起到治本作用的,结合LRU算法能够较好的帮我们解决这个问题。那么LRU是什么,下面粗略的介绍一下,有兴趣的可以点击上面的链接查看.
LRU(Least recently used,最近最少使用)
算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。最常见的实现是使用一个链表保存缓存数据,如下图所示
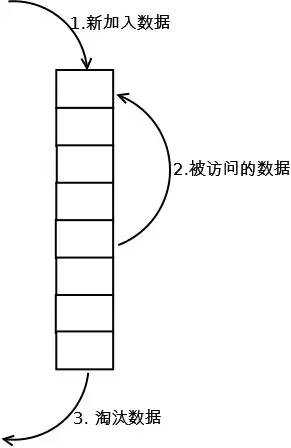
这个链表即是我们的缓存结构,缓存处理步骤为
1.首先将新数据放入链表的头部
2.在进行数据插入的过程中,如果检测到链表中有数据被再次访问也就是有请求再次访问这些数据,那么就其插入的链表的头部,因为它们相对其他数据来说可能是热点数据,具有保留时间更久的意义
3.最后当链表数据放满时将底部的数据淘汰,也就是不常访问的数据
LRU-K算法
其实上面的算法也是该算法的特例情况即LRU-1,上面的算法存在较多的不合理性,在实际的应用过程中采用该算法进行了改进,例如偶然的数据影响会造成命中率较低,比如某个数据即将到达底部即将被淘汰,但由于一次的请求又放入了头部,此后再无该数据的请求,那么该数据的继续存在其实是不合理的,针对这类情况LRU-K算法拥有更好的解决措施。结构图如下所示:
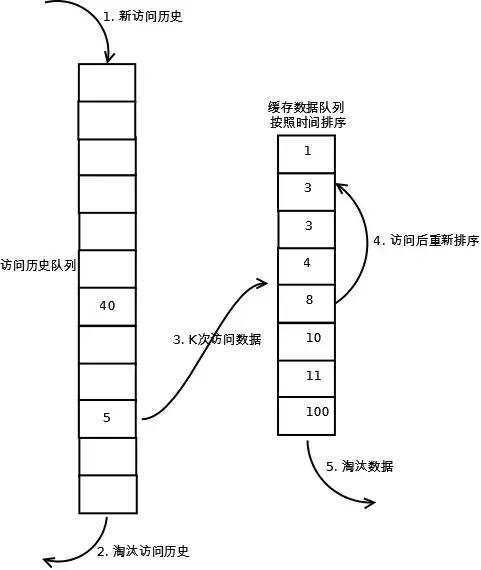
LRU-K需要多维护一个队列或者更多,用于记录所有缓存数据被访问的历史。只有当数据的访问次数达到K次的时候,才将数据放入缓存。当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据。关注Java技术栈微信公众号,在后台回复关键字:缓存,可以获取更多栈长整理的缓存系列技术干货。
第一步添加数据照样放入第一个队列的头部
如果数据在该队列里访问没有达到K次(该数值根据具体系统qps来定)则会继续到达链表底部直至淘汰;如果该数据在队列中时访问次数达到了K次,那么它会被加入到接下来的2级(具体需要几级结构也同样结合系统分析)链表中,按照时间顺序在2级链表中排列
接下来2级链表中的操作与上面算法相同,链表中的数据如果再次被访问则移到头部,链表满时,底部数据淘汰
相比LRU,LRU-K需要多维护一个队列,用于记录所有缓存数据被访问的历史,所以需要更多的内存空间来用来构建缓存,但优点也很明显,较好的降低了数据的污染率提高了缓存的命中率,对于系统来说可以用一定的硬件成本来换取系统性能也不失为一种办法。
标签:链接 最大的 use 算法 记录 表数据 热门话题 inf 行数据
原文地址:https://www.cnblogs.com/yuanfang0903/p/11198289.html