标签:batch cell data generate line 数据集 gap 结果 优化
注解:
fun_data()函数生成训练数据和标签,同时生成测试数据和测试标签
HIDDEN_SIZE = 128,使用128维的精度来定义LSTM的状态和输出精度,就是LSTM中的h,c
lstm_model()函数定义了一个可重入的模型,
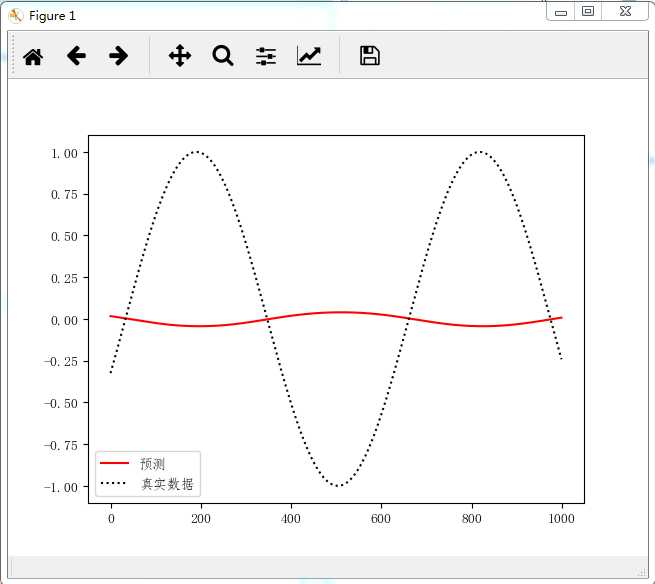
分别由评估函数和训练函数调用,在训练前使用空模型预测并输出未训练数据并可视化
通过with tf.variable_scope("lstm_model",reuse=tf.AUTO_REUSE) as scope:定义了在多次实例化模型的时候共享训练结果
run_eval()定义了评估函数:实现了训练及可视化结果
run_train()定义了训练函数:实现了训练过程。
如果还要提高拟合精度可以把TRAINING_STEPS设大些,不过比较耗时,我的电脑比较老,感觉训练一千次拟合精度就很高了,再训练已经没意义了,呵呵。
图一:还未训练之间的结果,拟合基本上不行
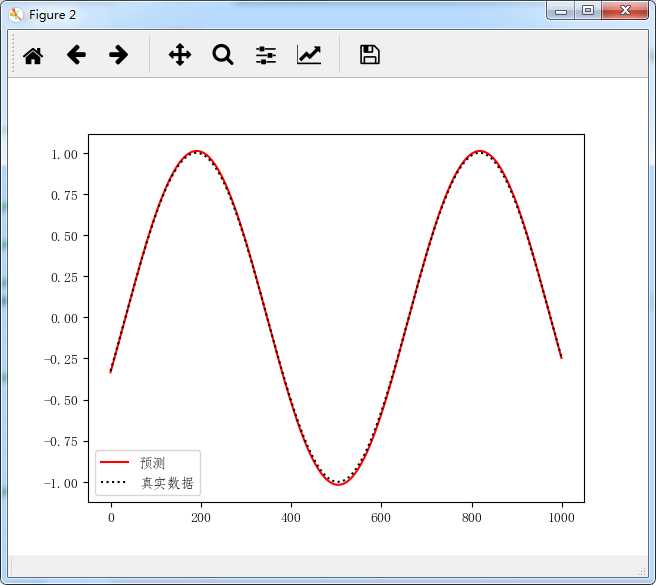
图二:训练500-2000次基本就能很好的预测sin上的任何点了。
1 # LSTM预测sin曲线 2 #tensorflow 1.13.1 3 #numpy 1.16.2 4 import numpy as np 5 import tensorflow as tf 6 import matplotlib.pyplot as plt 7 plt.rcParams[‘font.sans-serif‘]=[‘FangSong‘] # 用来正常显示中文标签 8 plt.rcParams[‘axes.unicode_minus‘]=False# 用来正常显示负号 9 ######################################################################################## 10 # RNN模型相关参数 11 HIDDEN_SIZE = 128 # LSTM中隐藏节点的个数,定义输出及状态的向量维度。 12 NUM_LAYERS = 3 # LSTM的层数。 13 TIME_STEPS = 10 # 循环神经网络的训练序列长度 14 TRAINING_STEPS = 2000 # 训练轮数。 15 BATCH_SIZE = 32 # batch大小。 16 #数据样本数量 17 TRAINING_EXAMPLES = 10000 # 训练数据个数。 18 TESTING_EXAMPLES = 1000 # 测试数据个数。 19 ######################################################################################## 20 def fun_data(): 21 # 用正弦函数生成训练和测试数据集合。 22 SAMPLE_GAP = 0.01# 采样间隔。 23 test_start = (TRAINING_EXAMPLES + TIME_STEPS) * SAMPLE_GAP 24 test_end = test_start + (TESTING_EXAMPLES + TIME_STEPS) * SAMPLE_GAP 25 MYTRAIN = np.sin(np.linspace(0, test_start, TRAINING_EXAMPLES + TIME_STEPS, dtype=np.float32)) 26 MYTEST = np.sin(np.linspace(test_start, test_end, TESTING_EXAMPLES + TIME_STEPS, dtype=np.float32)) 27 28 def generate_data(seq): 29 X,Y = [],[] 30 for i in range(len(seq) - TIME_STEPS): 31 X.append([seq[i: i + TIME_STEPS]]) # 用[0]至[9]个特征 32 Y.append([seq[i + TIME_STEPS]]) # 预测[10]这个值 33 return np.array(X, dtype=np.float32), np.array(Y, dtype=np.float32) 34 35 #生成训练数据和测试数据 36 #(10000, 1, 10) (10000, 1) 37 train_x, train_y = generate_data(MYTRAIN) 38 #(1000, 1, 10) (1000, 1) 39 test_x, test_y = generate_data(MYTEST) 40 41 return train_x, train_y, test_x, test_y 42 43 def lstm_model(X, y): 44 # 定义算法图:可重入,共享训练变量 45 # 每调用一次lstm_model函数会在同一个系统缺省图 46 # tf.variable_scope("lstm_model",reuse=tf.AUTO_REUSE)定义共享训练变量 47 with tf.variable_scope("lstm_model",reuse=tf.AUTO_REUSE) as scope: 48 #定义多层LSTM 49 cell = tf.nn.rnn_cell.MultiRNNCell( 50 [tf.nn.rnn_cell.LSTMCell(HIDDEN_SIZE) for _ in range(NUM_LAYERS)]) 51 #根据tf.nn.dynamic_rnn对数据的要求变换shape 52 #XX (?, 10, 1),X(?, 1, 10) 53 XX = tf.reshape(X,[-1, X.shape[-1], X.shape[-2]]) 54 # outputs (?, 10, 128) 55 outputs, _ = tf.nn.dynamic_rnn(cell, XX, dtype=tf.float32) 56 # 取TIME_STEPS最后一个单元上的输出作为预测值 57 # output (?, 128) 58 output = outputs[:, -1, :] 59 # 加一层全连接直接输出预测值 60 # predictions (?, 1) 61 mypredictions = tf.layers.dense(output,1) 62 # 平均平方差损失函数计算工时,用这个函数来求loss。 63 loss = tf.losses.mean_squared_error(labels=y, predictions=mypredictions) 64 # 使用AdamOptimizer进行优化 65 train_op = tf.train.AdamOptimizer(0.01).minimize(loss) 66 return mypredictions, loss, train_op 67 68 def run_eval(sess): 69 # 评估算法 70 ds = tf.data.Dataset.from_tensor_slices((self.test_X, self.test_y)) 71 ds = ds.batch(1)#一次取一个样本 72 X, y = ds.make_one_shot_iterator().get_next() 73 prediction, loss, train_op = lstm_model(X, y) 74 predictions = [] 75 labels = [] 76 for i in range(TESTING_EXAMPLES): 77 p, l = sess.run([prediction, y]) 78 predictions.append(p) 79 labels.append(l) 80 predictions = np.array(predictions).squeeze() 81 labels = np.array(labels).squeeze() 82 83 #对预测的sin函数曲线进行绘图。 84 plt.figure() 85 plt.plot(predictions, label=‘预测‘,linestyle=‘solid‘, color=‘red‘) 86 plt.plot(labels, label=‘真实数据‘,linestyle=‘dotted‘,color=‘black‘) 87 plt.legend() 88 plt.show() 89 90 return 91 92 def run_train(sess): 93 #定义训练过程 94 for ecoh in range(TRAINING_STEPS): 95 myloss, _ = sess.run([self.loss, self.train_op]) 96 if ecoh % 100 == 0: 97 print(‘训练次数:{:}损失函数值:{:}‘.format(ecoh,myloss)) 98 return 99 100 def run_main(): 101 102 #准备数据 103 self.train_X, self.train_y,self.test_X, self.test_y = fun_data() 104 ds = tf.data.Dataset.from_tensor_slices((self.train_X, self.train_y)) 105 ds = ds.repeat().shuffle(1000).batch(BATCH_SIZE)#一次取BATCH_SIZE个样本 106 X, y = ds.make_one_shot_iterator().get_next() 107 108 #定义模型 109 self.prediction, self.loss, self.train_op = lstm_model(X, y) 110 # 初始化方法定义 111 init = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer()) 112 113 with tf.Session() as sess: 114 sess.run(init) 115 # 测试在训练之前的模型效果。 116 run_eval(sess) 117 # 训练模型。 118 run_train(sess) 119 # 使用训练好的模型对测试数据进行预测。 120 run_eval(sess) 121 return 122 123 if __name__ == "__main__" : 124 run_main()
标签:batch cell data generate line 数据集 gap 结果 优化
原文地址:https://www.cnblogs.com/ace007/p/11198311.html