标签:内聚性 enc embedding 重复 回顾 ghost lse image 性能
GhostVLAD for set-based face recognition 中提到了文章解决的是template-based face recognition。
文章的3个贡献:
那么这种set(template) based face recognition的难处何在?在于集合里的人脸可能有不同的姿态,表情,光照,甚至质量的差异也很大。如果我给low-quality和high-quality一样的weight,那肯定会hurt performance。所以网络应该更关注于informative ones。
比较set之间的相似性一个直接的做法就是我将每个subject的所有人脸特征都存储起来,然后比较两个subject的每一对图像,这么做是非常耗存储和时间。因此聚合方法能够产生compact template representation。更重要的是,从image set获取的representation应当更加具有判别性。同一subject的template descriptors应当互相close,反之则far apart。尽管一些工作利用average pooling和max pooling可以聚合到一个比较compact的template representation,本文寻找一种更好的方案。本文灵感来源于图像检索中的编码方法:Fisher Vector encoding和T-embedding 增加从related和unrelated图像块提取到的描述子的可分性。于是作者也在利用了一种相似的encoding:NetVLAD来设计网络。作者拓展NetVLAD结构to include ghost clusters。将这些低质量人脸视为ghost clusters。尽管没有明确对template里的faces进行加权,这种特性自动会出现。即低质量人脸会contribute less。网络以端到端的方式训练,仅用identity-level labels。在IJB-A,IJB-B上面都有很大提升。
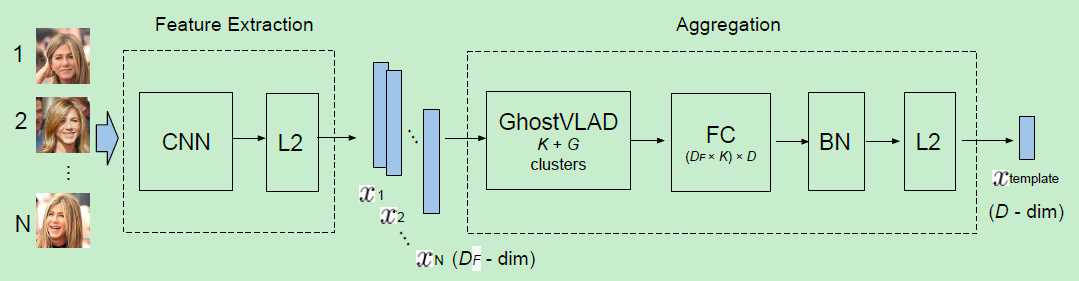
大致结构如上图:对一个template中的每个图片提取特征,然后利用GhostVLAD层来聚合这些descriptors到单一固定长度的vectors。最后的D维template描述子由FC层来削减维度,并附有BN和L2正则。
这个网络应该有如下性质:
上面三条性质的实现方案分别如下:
本文的核心部件:GhostVLAD:NetVLAD with ghost clusters
这是个可训练的aggregation layer。给定N个DF维的面部向量,计算一个单一的DF乘K维的输出。它基于NetVLAD层实现了一个编码过程,类似于VLAD encoding。所以是可微可训练的。这个NetVLAD已被证实比average和max pooling的效果要好。这里简要回顾一下论文NetVLAD(NetVLAD: CNN architecture for weakly supervised place recognition)。

作者拓展NetVLAD with "ghost" clusters为GhostVLAD。即作者在原有的K个类簇中额外的加了G个“ghost”类簇来形成soft assignments。
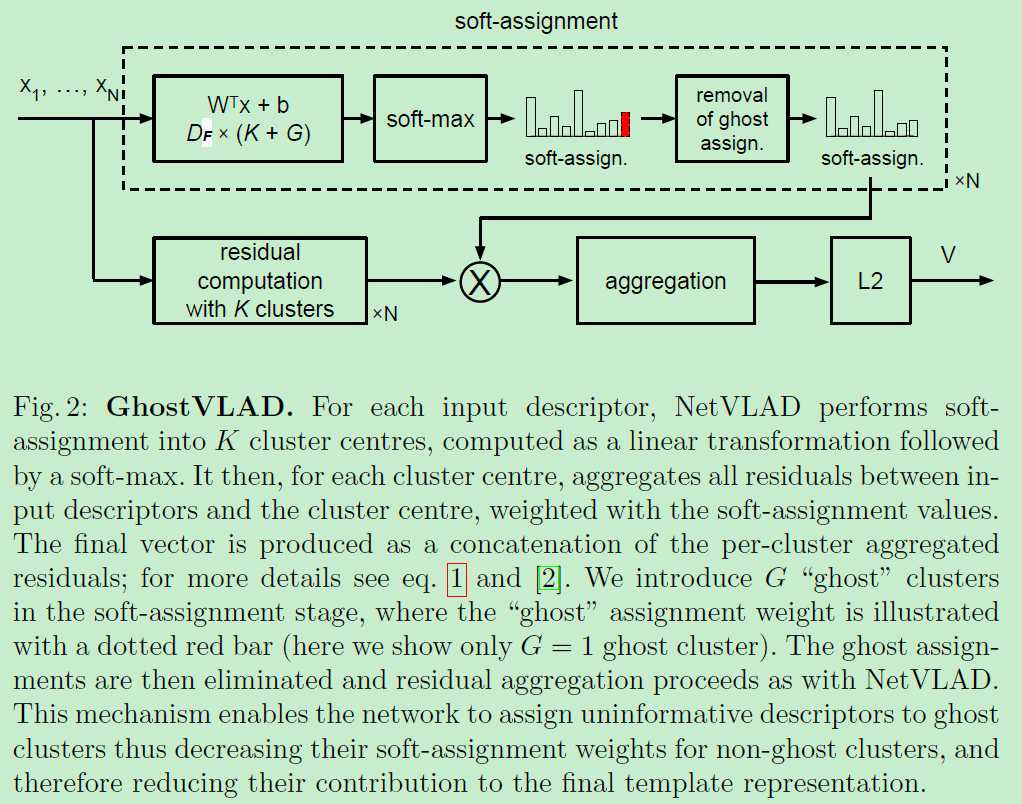
使用ghost clusters的一个直觉就是使得网络更容易调整template中的每个face example。这通过assigning examples to be ignored to the ghost clusters来实现的。例如对于一个highly blurry的人脸图像,将会被很大程度上assigned to a ghost cluster,使得它在non-ghost的clusters的权重就会趋近于0。那这样就使得它对于template representation的贡献是可忽略不计的。
一些训练细节:
为了perform set-based training,重复在线采样属于同一identity的固定数目的图像。
测试细节:
对于IJB-A和IJB-B做“1:1 face verification”和“1:N face identification”。
结果:明显对低质量图像降低了权重。

GhostVLAD for set-based face recognition
标签:内聚性 enc embedding 重复 回顾 ghost lse image 性能
原文地址:https://www.cnblogs.com/king-lps/p/11202384.html