标签:特定 tomcat 握手 memcache 个数 java se activemq tcp标志位 可能性
https://blog.csdn.net/bntX2jSQfEHy7/article/details/81187626
各大企业面试题:
https://blog.csdn.net/huangshulang1234/article/details/79102943
设计模式面试题:
https://blog.csdn.net/wu_ming0821/article/details/51838078
https://blog.csdn.net/zhousenshan/article/details/72808887
排序面试总结:
https://blog.csdn.net/sunxianghuang/article/details/51872360
百度:2017面试题
https://blog.csdn.net/pc123455/article/details/53319467
Redis的持久化:RDB与AOF
https://www.cnblogs.com/fixzd/p/9393990.html
Redis的高手总结:
https://blog.csdn.net/hjm4702192/article/details/80518856
最常见的面试题:
https://blog.csdn.net/Px01Ih8/article/details/81267503
应用场景:
Memcached:动态系统中减轻数据库负载,提升性能;做缓存,适合多读少写,大数据量的情况(如人人网大量查询用户信息、好友信息、文章信息等)。
Redis:适用于对读写效率要求都很高,数据处理业务复杂和对安全性要求较高的系统(如新浪微博的计数和微博发布部分系统,对数据安全性、读写要求都很高)。
一、阿里巴巴面试
第一个:阿里面试都问什么? :(55分钟)
01
1、开发中Java用了比较多的数据结构有哪些?
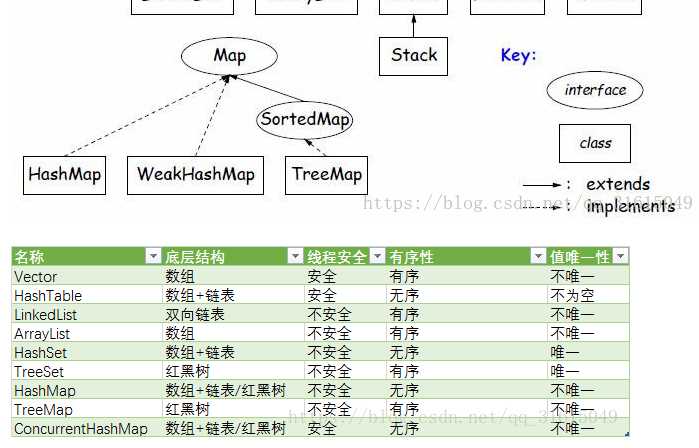
2、谈谈你对HashMap的理解,底层原理的基本实现,HashMap怎么解决碰撞问题的?

Java中hashmap的解决办法就是采用的链地址法。
哈希表是由数组+链表组成的,一个长度为16的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则存储到数组中呢。一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。比如上述哈希表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。
HashMap其实也是一个线性的数组实现的,所以可以理解为其存储数据的容器就是一个线性数组。这可能让我们很不解,一个线性的数组怎么实现按键值对来存取数据呢?这里HashMap有做一些处理。
首先HashMap里面实现一个静态内部类Entry,其重要的属性有 key , value, next,从属性key,value我们就能很明显的看出来Entry就是HashMap键值对实现的一个基础bean,我们上面说到HashMap的基础就是一个线性数组,这个数组就是Entry[],Map里面的内容都保存在Entry[]里面。
这些数据结构中是线程安全的吗?假如你回答HashMap是线程安全的,接着问你有没有线程安全的map,接下来问了conurren包。
|
1
|
HashMap是否是线程安全的,如何在线程安全的前提下使用HashMap,其实也就是HashMap,Hashtable,ConcurrentHashMap和synchronized Map的原理和区别。<br>当时有些紧张只是简单说了下HashMap不是线程安全的;Hashtable线程安全,但效率低,因为是Hashtable是使用synchronized的,<br>所有线程竞争同一把锁;<br>而ConcurrentHashMap不仅线程安全而且效率高,因为它包含一个segment数组,将数据分段存储,<br>给每一段数据配一把锁,也就是所谓的锁分段技术。当时忘记了synchronized Map和解释一下HashMap为什么线程不安全。<br>HashMap在并发时可能出现的问题主要是两方面,首先如果多个线程同时使用put方法添加元素,<br>而且假设正好存在两个put的key发生了碰撞(hash值一样),那么根据HashMap的实现,<br>这两个key会添加到数组的同一个位置,这样最终就会发生其中一个线程的put的数据被覆盖。<br>第二就是如果多个线程同时检测到元素个数超过数组大小*loadFactor,<br>这样就会发生多个线程同时对Node数组进行扩容,都在重新计算元素位置以及复制数据,<br>但是最终只有一个线程扩容后的数组会赋给table,也就是说其他线程的都会丢失,并且各自线程put的数据也丢失<br><br>详细解释:<br>http://www.importnew.com/21396.html |
3、对JVM熟不熟悉?简单说说类加载过程,里面执行的哪些操作?问了GC和内存管理,平时在tomcat里面有没有进行过相关的配置
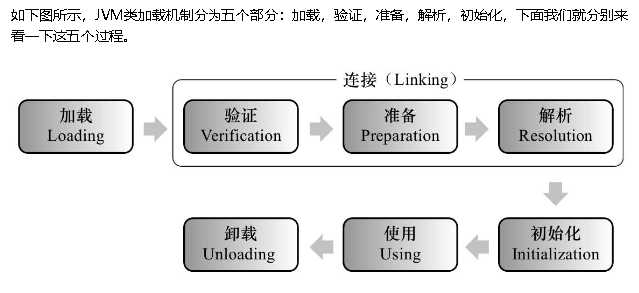
4、然后问了http协议,get和post的基本区别,接着tcp/ip协议,三次握手,窗口滑动机制。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
三次握手过程:第一次握手:host1发送一个TCP标志位SYN=1、ACK=0的数据包给host2,并随机会产生一个Sequence number=3233.当host2接收到这个数据后,host2由SYN=1可知客户端是想要建立连接;第二次握手:host2要对客户端的联机请求进行确认,向host1发送应答号ACK=1、SYN=1、确认号Acknowledge number=3234,此值是host1的序列号加1,还会产生一个随机的序列号Sequence number=36457,这样就告诉host1可以进行连接;第三次握手:host1收到数据后检查Acknowledge number是否是3233+1的值,以及ACK的值是否为1,若为1,host1会发送ACK=1、确认号码Acknowledge number=36457,告诉host2,你的请求连接被确认,连接可以建立。四次挥手过程:第一次挥手:当传输的数据到达尾部时,host1向host2发送FIN=1标志位;可理解成,host1向host2说,我这边的数据传送完成了,我准备断开了连接;第二次挥手:因TCP的连接是全双工的双向连接,关闭也是要从两边关闭;当host2收到host1发来的FIN=1的标志位后,host2不会立刻向host1发送FIND=1的请求关闭信息,而是先向host1发送一个ACK=1的应答信息,表示:你请求关闭的请求我已经收到,但我可能还有数据没有完成传送,你再等下,等我数据传输完成了我就告诉你;第三次挥手:host2数据传输完成,向host1发送FIN=1,host1收到请求关闭连接的请求后,host1就明白host2的数据已传输完成,现在可以断开连接了,第四次挥手:host1收到FIND=1后,host1还是怕由于网络不稳定的原因,怕host2不知道他要断开连接,于是向host2发送ACK=1确认信息进行确认,把自己设置成TIME_WAIT状态并启动定时器,如果host2没有收到ACK,host2端TCP的定时器到达后,会要求host1重新发送ACK,当host2收到ACK后,host2就断开连接;当host1等待2MLS(2倍报文最大生存时间)后,没有收到host2的重传请求后,他就知道host2已收到了ACK,所以host1此时才关闭自己的连接。这一点我觉得设计得非常巧妙! |
5、开发中用了那些数据库?回答mysql,储存引擎有哪些?然后问了我悲观锁和乐观锁问题使用场景、分布式集群实现的原理。
|
1
2
3
4
5
6
7
8
|
InnoDB存储引擎InnoDB是事务型数据库的首选引擎,支持事务安全表(ACID),支持行锁定和外键。MyISAM基于ISAM存储引擎,并对其进行扩展。它是在Web、数据仓储和其他应用环境下最常使用的存储引擎之一。MyISAM拥有较高的插入、查询速度,但不支持事物MEMORY存储引擎MEMORY存储引擎将表中的数据存储到内存中,未查询和引用其他表数据提供快速访问 |
悲观锁和乐观锁:
|
1
2
3
4
5
6
7
8
9
10
11
|
定义:悲观锁(Pessimistic Lock):每次获取数据的时候,都会担心数据被修改,所以每次获取数据的时候都会进行加锁,确保在自己使用的过程中数据不会被别人修改,使用完成后进行数据解锁。由于数据进行加锁,期间对该数据进行读写的其他线程都会进行等待。乐观锁(Optimistic Lock):每次获取数据的时候,都不会担心数据被修改,所以每次获取数据的时候都不会进行加锁,但是在更新数据的时候需要判断该数据是否被别人修改过。如果数据被其他线程修改,则不进行数据更新,如果数据没有被其他线程修改,则进行数据更新。由于数据没有进行加锁,期间该数据可以被其他线程进行读写操作。适用场景:悲观锁:比较适合写入操作比较频繁的场景,如果出现大量的读取操作,每次读取的时候都会进行加锁,这样会增加大量的锁的开销,降低了系统的吞吐量。乐观锁:比较适合读取操作比较频繁的场景,如果出现大量的写入操作,数据发生冲突的可能性就会增大,为了保证数据的一致性,应用层需要不断的重新获取数据,这样会增加大量的查询操作,降低了系统的吞吐量。 |
6、然后问了我springmvc和mybatis的工作原理,有没有看过底层源码?
二、京东金融面试
02
1、Dubbo超时重试;Dubbo超时时间设置
https://www.cnblogs.com/binyue/p/5380322.html
2、如何保障请求执行顺序
|
1
2
3
|
这个正是消息队列的用武之地.为了简单轻量级的可以考虑使用 Redis. 借助 Redis 的list结构, Producer 调用 Redis 的 lpush 往特定key里添加消息, Consumer 调用 brpop 去不断监听该key.如果需要实现复杂功能的, 那么可以考虑使用 RabbitMQ 或 ActiveMQ 等之类的专门的消息队列 |
3、分布式事物与分布式锁(扣款不要出现负数)
https://blog.csdn.net/peng_0129/article/details/80000564
4、分布式session设置
https://www.cnblogs.com/cxrz/p/8529587.html
5、执行某操作,前50次成功,第51次失败a全部回滚b前50次提交第51次抛异常,ab场景分别如何设置Spring(传播性)
6、Zookeeper有哪些应用用
https://www.cnblogs.com/liuwei6/p/6737908.html
7、JVM内存模型
8、数据库垂直和水平拆分
9、MyBatis如何分页;如何设置缓存;MySQL分页
https://www.cnblogs.com/tenWood/p/6676331.html
|
1
2
3
4
5
6
|
逻辑分页:mybatis内置的分页是逻辑分页;数据库里有100条数据,要每页显示10条,mybatis先把100条数据取出来,放到内存里,从内存里取10条;虽然取出的是10条,但是性能不好,几千条上万条没问题,数据量大性能就有问题了;小项目使用没问题;正式的项目数据量都很大就不使用了; 物理分页:开发的时候用的:拼sql,真正实现分页; |

mysql的分页;
一般情况下,客户端通过传递 pageNo(页码)、pageSize(每页条数)两个参数去分页查询数据库中的数据,在数据量较小(元组百/千级)时使用 MySQL自带的 limit 来解决这个问题
10、熟悉IO么?与NIO的区别,阻塞与非阻塞的区别
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
面向Stream和面向BufferJava NIO和IO之间最大的区别是IO是面向流(Stream)的,NIO是面向块(buffer)的,所以,这意味着什么?面向流意味着从流中一次可以读取一个或多个字节,拿到读取的这些做什么你说了算,这里没有任何缓存(这里指的是使用流没有任何缓存,接收或者发送的数据是缓存到操作系统中的,流就像一根水管从操作系统的缓存中读取数据)而且只能顺序从流中读取数据,如果需要跳过一些字节或者再读取已经读过的字节,你必须将从流中读取的数据先缓存起来。面向块的处理方式有些不同,数据是先被 读/写到buffer中的,根据需要你可以控制读取什么位置的数据。这在处理的过程中给用户多了一些灵活性,然而,你需要额外做的工作是检查你需要的数据是否已经全部到了buffer中,你还需要保证当有更多的数据进入buffer中时,buffer中未处理的数据不会被覆盖阻塞IO和非阻塞IO所有的Java IO流都是阻塞的,这意味着,当一条线程执行read()或者write()方法时,这条线程会一直阻塞知道读取到了一些数据或者要写出去的数据已经全部写出,在这期间这条线程不能做任何其他的事情java NIO的非阻塞模式(Java NIO有阻塞模式和非阻塞模式,阻塞模式的NIO除了使用Buffer存储数据外和IO基本没有区别)允许一条线程从channel中读取数据,通过返回值来判断buffer中是否有数据,如果没有数据,NIO不会阻塞,因为不阻塞这条线程就可以去做其他的事情,过一段时间再回来判断一下有没有数据NIO的写也是一样的,一条线程将buffer中的数据写入channel,它不会等待数据全部写完才会返回,而是调用完write()方法就会继续向下执行SelectorsJava NIO的selectors允许一条线程去监控多个channels的输入,你可以向一个selector上注册多个channel,然后调用selector的select()方法判断是否有新的连接进来或者已经在selector上注册时channel是否有数据进入。selector的机制让一个线程管理多个channel变得简单。 |
11、分布式session一致性
12、分布式接口的幂等性设计「不能重复扣款」
https://blog.csdn.net/wconvey/article/details/54601108
https://www.cnblogs.com/wxgblogs/p/6639272.html
三、美团面试
03
1、最近做的比较熟悉的项目是哪个?画一下项目技术架构图
2、JVM老年代和新生代的比例?
3、YGC和FGC发生的具体场景
4、jstack,jmap,jutil分别的意义?如何线上排查JVM的相关问题?
https://blog.csdn.net/qq_26653067/article/details/79728520
5、线程池的构造类的方法的5个参数的具体意义?
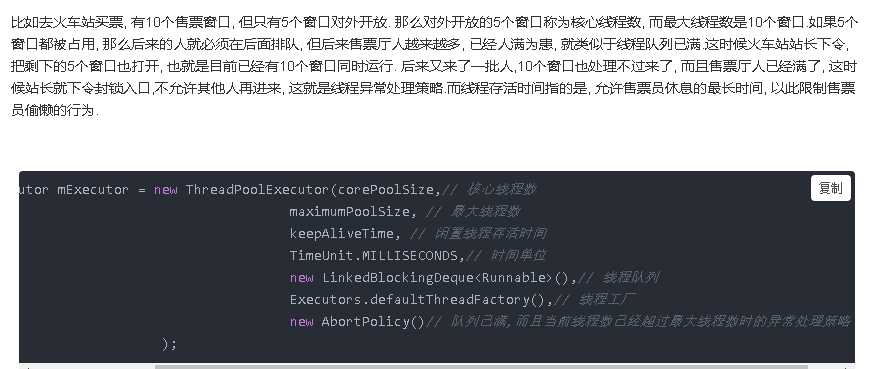
6、单机上一个线程池正在处理服务如果忽然断电该怎么办?(正在处理和阻塞队列里的请求怎么处理)?
7、使用无界阻塞队列会出现什么问题?
8、接口如何处理重复请求?
重复提交的问题
https://blog.csdn.net/js_sky/article/details/49303997
9、具体处理方案是什么?
10、如何保证共享变量修改时的原子性?
https://www.cnblogs.com/SirSmith/p/6014441.html
11、设计一个对外服务的接口实现类,在1,2,3这三个主机(对应不同IP)上实现负载均衡和顺序轮询机制(考虑并发)
标签:特定 tomcat 握手 memcache 个数 java se activemq tcp标志位 可能性
原文地址:https://www.cnblogs.com/vitozhu/p/11203350.html