标签:实践 created info href buffered 生产 多个 使用 图片
在我前面一篇文章Golang受欢迎的原因中已经提到,Golang是在语言层面(runtime)就支持了并发模型。那么作为编程人员,我们在实践Golang的并发编程时,又有什么需要注意的点呢?下面我会跟大家详细的介绍一些在实际生产编程中很容易踩坑的知识点。
在介绍Golang的并发实践前,有必要先介绍简单介绍一下CSP理论。CSP,全称是Communicating sequential processes,翻译为通信顺序进程,又翻译为交换消息的顺序程序,用来描述并发性系统的交互模式。CSP有以下三个特点:
1.每个程序是为了顺序执行而创建的
2.数据通过管道来通信,而不是通过共享内存
3.通过增加相同的程序来扩容
Golang的并发模型基于CSP理论,Golang并发的口号是:不用通过共享内存来通信,而是通过通信来共享内存。
Golang用来支持并发的元素集:
其中goroutines,channels和select 对应于实现CSP理论,即通过通信来共享内存。这几乎能解决Golang并发的90%问题,另外的10%场景需要通过同步原语来解决,即sync包相关的结构。

如上图所示,我们从一个简单的沙桶传递小游戏来认识Golang中的channel。其中蓝色的Gopher为发送方,紫色的Gopher为接受方,中间的灰色Gopher代表channel的缓冲区大小。
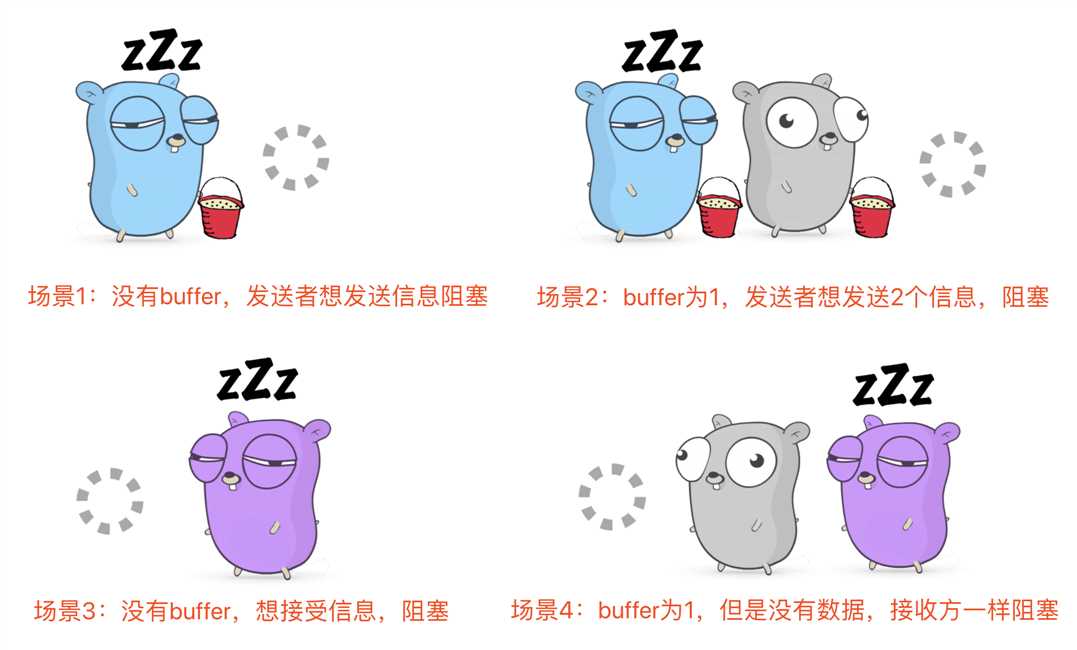
不带buffer的channel阻塞情况:
unbuffered := make(chan int) a := <- unbuffered // 阻塞 unbuffered := make(chan int) // 1) 阻塞 a := <- unbuffered // 2) 阻塞 unbuffered <- 1 // 3) 同步 go func() { <-unbuffered }() unbuffered <- 1
带buffer的channel阻塞情况:
buffered := make(chan int, 1) // 4) 阻塞 a := <- buffered // 5) 不阻塞 buffered <-1 // 6) buffer满,阻塞 buffered <-2
上述情况其实归纳起来很简单:不管有无缓冲区channel,写满或者读空都会阻塞。
不带buffer和带buffer的channel用途:
c := make(chan int) close(c) fmt.Println(<-c) //接收并输出chan类型的零值,这里int是0
需要特殊说明的是,channel不像socket或者文件,不需要通过close来释放资源。需要close的唯一情况是,通过close触发channel读事件,comma,ok := <- c 中ok为false,表示channel已经关闭。只能在发送端close channel,因为channel关闭接收端能感知到,但是发送端感知不到,只能主动关闭。往已经关闭的channel发送信息将会触发panic。
类似switch语句,只不过case都是channel的读或者写操作,也可能是default。case的顺序一点都不重要,不要依赖case的先后来定义优先级,第一个非阻塞(send and/or receive)的case将会被选中。
func TryReceive(c <-chan int) (data int, more, ok bool) { select { case data, more = <- c: return data, more, true } default: return 0, true, false }
当select中的case都处于阻塞状态时,就会选中default分支。
或者超时返回:
func TryReceiveWithTimeout(c <-chan int, duration time.Duration) (data int, more, ok bool) { select { case data, more = <-c: return data, more, true case <- time.After(duration): return 0, true, false } }
time.After(duration)会返回一个channel,当duration到期时会触发channel的读事件。
1.Channel可能会导致死锁(循环阻塞)
2.channel中传递的都是数据的拷贝,可能会影响性能
3.channel中传递指针会导致数据竞态问题(data race/ race conditions)
第三点中提到了数据竞态问题,也就是通常所说data race。在接着往下讲之前有必要先简单讲解下data race的危害。data race 指的是多线程并发读写一个变量,对应到Golang中就是多个goroutine同时读写一个变量,这种行为是未定义的,也就是说读变量出来的值很有可能不是写入的值,这个值是任意值都有可能。
例如下面这段代码:
package main import ( "fmt" "runtime" "time" ) var i int64 = 0 func main() { runtime.GOMAXPROCS(2) go func() { for { fmt.Println("i is", i) time.Sleep(time.Second) } }() for { i += 1 } }
在我mac本地环境会不断的输出0。全局变量i被两个goroutine同时读写,也就是我们所说的data race,导致了i的值是未定义的。如果读写的是一块动态伸缩的内存,很有可能会导致panic。例如多goroutine读写map。幸运的是,Golang针对data race有专门的内置工具,例如把上面的代码保存为main.go,执行 go run -race main.go 会把相关的data race输出:
================== WARNING: DATA RACE Read at 0x00000121e848 by goroutine 6: main.main.func1() /Users/saas/src/awesomeProject/datarace/main.go:15 +0x3e Previous write at 0x00000121e848 by main goroutine: main.main() /Users/saas/src/awesomeProject/datarace/main.go:21 +0x7b Goroutine 6 (running) created at: main.main() /Users/saas/src/awesomeProject/datarace/main.go:13 +0x4f ==================
上面提到了一些channel的缺点,文章一开始我也提到了channel能解决Golang并发编程的90%问题,那剩下的一些少数并发情况用什么更优的方案呢?
锁就像厕所的坑位一样,你占用的时间越长,等待的人排的队就会越长。读写锁只会减缓这种情况。另外使用多个锁很容易导致死锁。总而言之,锁不是我们只在寻找的方案。
原子操作是这10%场景有限考虑的解决方案。原子操作是在CPU层面保证了原子性。不用编程人员加锁。Golang对应的操作在sync.atomic 包。Store, Load, Add, Swap 和 CompareAndSwap方法。
CompareAndSwap 方法
type Spinlock struct { state *int32 } const free = int32(0) func (l *Spinlock) Lock() { for !atomic.CompareAndSwapInt32(l.state, free, 42) { //如果state等于0就赋值为42 runtime.Gosched() //让出CPU } } func (l *Spinlock) Unlock(){ atomic.StoreInt32(l.state, free) // 所有操作state变量的操作都应该是原子的 }
1.避免阻塞,避免数据竞态
2.用channel避免共享内存,用select管理channel
3.当channel不适用于你的场景时,尽量用sync包的原子操作,如果实在需要用到锁,尽量缩小锁的粒度(锁住尽量少的代码)。
根据前面介绍的内容,我们来看看下面的这个例子有没有什么问题:
func restore(repos []string) error { errChan := make(chan error, 1) sem := make(chan int, 4) // four jobs at once var wg sync.WaitGroup wg.Add(len(repos)) for _, repo := range repos { sem <- 1 go func() { defer func() { wg.Done() <- sem }() if err := fetch(repo); err != nil { errChan <- err } }() } wg.Wait() close(sem) close(errChan) return <- errChan }
Bug1. sem无需关闭
Bug2.go和匿名函数触发的bug,repo不断在更新,fetch拿到的repo是未定义的。有data race问题。
Bug3.sem<-1放在go func外面启动同时有4个goroutine在运行,并不能很好的控制同时有4个fetch任务。
Bug4. errChan的缓冲区大小为1,当多个fetch产生err时,将会导致程序死锁。
改良后的程序:
func restore(repos []string) error { errChan := make(chan error, 1) sem := make(chan int, 4) // four jobs at once var wg sync.WaitGroup wg.Add(len(repos)) for _, repo := range repos { go worker(repo, sem, &wg, errChan) } wg.Wait() close(errChan) return <- errChan } Func worker(repo string, sem chan int, wg *sync.WaitGroup, errChan chan err) { defer wg.Done() sem <- 1 if err := fetch(repo); err != nil { select { case errChan <- err: // we are the first worker to fail default: // some other failure has already happened, drop this one } } <- sem }
最后思考:为什么errChan一定要close?
因为最后的return<-errChan,如果fetch的err都为nil,那么errChan就是空,<-errChan是个永久阻塞的操作,close(sem)会触发读事件,返回chan累心的零值,这里是nil。
1.channel不是socket和file这种资源,不需要通过close来释放资源
2.避免将goroutine和匿名函数一起使用
3.在你启动一个goroutine之前,一定要清楚它会在什么时候,什么情况下会退出。
本文介绍了Golang并发编程的一些高效实践建议,旨在让大家在Golang并发实践中少踩坑。其中data race问题和goroutine退出的时机尤为重要。
https://www.youtube.com/watch?v=YEKjSzIwAdA
https://www.youtube.com/watch?v=yKQOunhhf4A
https://www.youtube.com/watch?v=QDDwwePbDtw
https://ms2008.github.io/2019/05/12/golang-data-race/
标签:实践 created info href buffered 生产 多个 使用 图片
原文地址:https://www.cnblogs.com/makelu/p/11205704.html