标签:encode mamicode 模块 onclick Matter eve append 文件中 stream
一.包
1.什么是包
包就是一系列模块文件的结合体,表示形式是一种文件夹,该文件夹内部通常有一个__init__.py文件.
2.为什么要用包
当一个模块功能太多的时候不方便进行管理,我们用包来进行管理
3.包的使用
首次发导入包发生的几件事:
1.先产生一个执行文件的名称空间
2.创建包下面的__init__文件的名称空间
3.执行包下面的__init__.py文件中的代码,将产生的名字放在包下面的__Init__,py文件名称空间中
4.在执行文件中拿到 一个指向包下面的__Init__文件名称空间的名字
导入的方法:
站在包的开发者角度,使用绝对路径来管理自己的模块,只需要永远以包的路径为基准一次导入,模块
站在包的使用者角度,必须将包所在的文件夹路径添加到sys.path中(********)
ps:1.做为开发者来说,可以使用相对导入,这样可以避免后期对模块名进行更改的问题(模块都是被导入文件)
2.在python2中如果要导入包,包下面必须有__init__.py文件,在python3中没有__init__.py文件也不会报错
二.logging(日志)模块
logging模块的做用:用来记录程序的运行日志
logging配置字典

import os import logging.config # 定义三种日志输出格式 开始 standard_format = ‘[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]‘ ‘[%(levelname)s][%(message)s]‘ #其中name为getlogger指定的名字 simple_format = ‘[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s‘ # 定义日志输出格式 结束 """ 下面的两个变量对应的值 需要你手动修改 """ logfile_dir = os.path.dirname(__file__) # log文件的目录 logfile_name = ‘a3.log‘ # log文件名 # 如果不存在定义的日志目录就创建一个 if not os.path.isdir(logfile_dir): os.mkdir(logfile_dir) # log文件的全路径 logfile_path = os.path.join(logfile_dir, logfile_name) # log配置字典 LOGGING_DIC = { ‘version‘: 1, ‘disable_existing_loggers‘: False, ‘formatters‘: { ‘standard‘: { ‘format‘: standard_format }, ‘simple‘: { ‘format‘: simple_format }, }, ‘filters‘: {}, # 过滤日志 ‘handlers‘: { #打印到终端的日志 ‘console‘: { ‘level‘: ‘DEBUG‘, ‘class‘: ‘logging.StreamHandler‘, # 打印到屏幕 ‘formatter‘: ‘simple‘ }, #打印到文件的日志,收集info及以上的日志 ‘default‘: { ‘level‘: ‘DEBUG‘, ‘class‘: ‘logging.handlers.RotatingFileHandler‘, # 保存到文件 ‘formatter‘: ‘standard‘, ‘filename‘: logfile_path, # 日志文件 ‘maxBytes‘: 1024*1024*5, # 日志大小 5M ‘backupCount‘: 5, ‘encoding‘: ‘utf-8‘, # 日志文件的编码,再也不用担心中文log乱码了 }, }, ‘loggers‘: { #logging.getLogger(__name__)拿到的logger配置 ‘‘: { ‘handlers‘: [‘default‘, ‘console‘], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕 ‘level‘: ‘DEBUG‘, ‘propagate‘: True, # 向上(更高level的logger)传递 }, # 当键不存在的情况下 默认都会使用该k:v配置 }, } if __name__ == ‘__main__‘: # 使用日志字典配置 logging.config.dictConfig(LOGGING_DIC) # 自动加载字典中的配置 logger1 = logging.getLogger(‘asajdjdskaj‘) logger1.debug(‘好好的 不要浮躁 努力就有收获‘)
日志等级:
1.debug 10
2.info 20
3.warning 30
4.error 40
5.critical 50
三.hashlib(加密)模块
# 1、什么叫hash:hash是一种算法(3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法),该算法接受传入的内容,经过运算得到一串hash值 # 2、hash值的特点是: #2.1 只要传入的内容一样,得到的hash值必然一样=====>要用明文传输密码文件完整性校验 #2.2 不能由hash值返解成内容=======》把密码做成hash值,不应该在网络传输明文密码 #2.3 只要使用的hash算法不变,无论校验的内容有多大,得到的hash值长度是固定的
hashlib用法:
import hashlib # 这个加密的过程是无法解密的 md = hashlib.md5() # 生成一个帮你造密文的对象 # md.update(‘hello‘.encode(‘utf-8‘)) # 往对象里传明文数据 update只能接受bytes类型的数据 md.update(b‘zhang,.12@‘) # 往对象里传明文数据 update只能接受bytes类型的数据 print(md.hexdigest()) # 获取明文数据对应的密文 # 72e5c0dd842fef886a0b641de69d6717
ps:内容可以多次传入,只要传入的内容相同,生成的密文一定相同
import hashlib md = hashlib.md5() md.update(b‘areyouok?‘) print(md.hexdigest()) #408ac8c66b1e988ee8e2862edea06cc7 import hashlib md = hashlib.md5() md.update(b‘are‘) md.update(b‘you‘) md.update(b‘ok?‘) print(md.hexdigest()) # 408ac8c66b1e988ee8e2862edea06cc7
加盐处理:网站本身在需要加密的数据之前手动添加一些内容,防止数据被盗被后解密
import hashlib def get_md5(data): md = hashlib.md5() md.update(‘加了好多盐啊‘.encode(‘utf-8‘)) md.update(data.encode(‘utf-8‘)) return md.hexdigest() password = input(‘password>>>:‘) res = get_md5(password) print(res) # password123 密文是e24f22b0ecde241fb2cc7c1a4f673fee # 未加盐密码是123 密文是202cb962ac59075b964b07152d234b70
四.openpyxl(操作excel)模块
xlwd 写excel模块(支持任何版本的excel文件)
xlrt 读excel模块(支持任何版本excel文件)
openpyxl 读写03版本之后的excel文件(xlsx)
如何用openpyxl来写excel文件:
from openpyxl import Workbook wb = Workbook() # 先生成一个工作簿 wb1 = wb.create_sheet(‘index‘,0) # 创建一个工作簿 后面可以通过数字控制位置 wb2 = wb.create_sheet(‘index1‘) # 创建一个工作簿在默认工作簿的右边 wb1.title = ‘login‘ # 后期可以通过工作簿对象点title修改工作簿名称 wb1[‘A3‘] = 333 # 对A3除插入数字333 wb1[‘A4‘] = 444 # 对A4除插入数字444 wb1.cell(row=6,column=3,value=6363) # 在6行3列处插入数字6363 wb1[‘A5‘] = ‘=sum(A3:A4)‘ # 将A3和A4进行求和接固放在A5 wb1.append([‘username‘, ‘age‘, ‘hobby‘]) # 对之前代码的下一行进行行编辑此时编辑对象为第七行 wb1.append([‘xu‘,20,‘piao‘]) wb1.append([‘wang‘,22,‘chihe‘]) wb.save(‘test.xlsx‘) # 保存文件
如何用openpyxl来写excel文件:
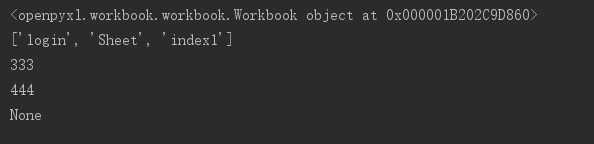
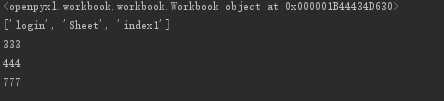
from openpyxl import load_workbook # 读文件 wb = load_workbook(‘test.xlsx‘,read_only=True,data_only=True) print(wb) print(wb.sheetnames) # [‘login‘, ‘Sheet‘, ‘index1‘] print(wb[‘login‘][‘A3‘].value) print(wb[‘login‘][‘A4‘].value) print(wb[‘login‘][‘A5‘].value)
ps:通过代码产生的excel表格必须经过人为的操作后才能取出函数计算出的结果(打开表格后对表格空白处写入一个数字然后删除在保存也行)
五.深浅拷贝
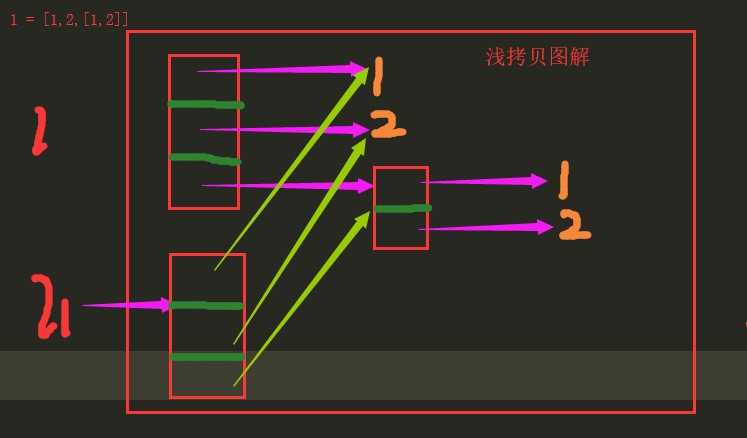
浅拷贝:数据半共享(复制其数据独立内存存放,但是只拷贝成功第一层)
import copy l1 = [1,2,3,[11,22,33]] l2 = l1.copy() print(l2) #[1,2,3,[11,22,33]] l2[3][2]=‘aaa‘ print(l1) #[1, 2, 3, [11, 22, ‘aaa‘]] print(l2) #[1, 2, 3, [11, 22, ‘aaa‘]] l1[0]= 0 print(l1) #[0, 2, 3, [11, 22, ‘aaa‘]] print(l2) #[1, 2, 3, [11, 22, ‘aaa‘]] print(id(l1)==id(l2)) #Flase
深拷贝:数据完全不共享(复制其数据完完全全放独立的一个内存,完全拷贝,数据不共享)
import copy l1 = [1, 2, 3, [11, 22, 33]] # l2 = copy.copy(l1) 浅拷贝 l2 = copy.deepcopy(l1) print(l1,‘>>>‘,l2) l2[3][0] = 1111 print(l1,">>>",l2)
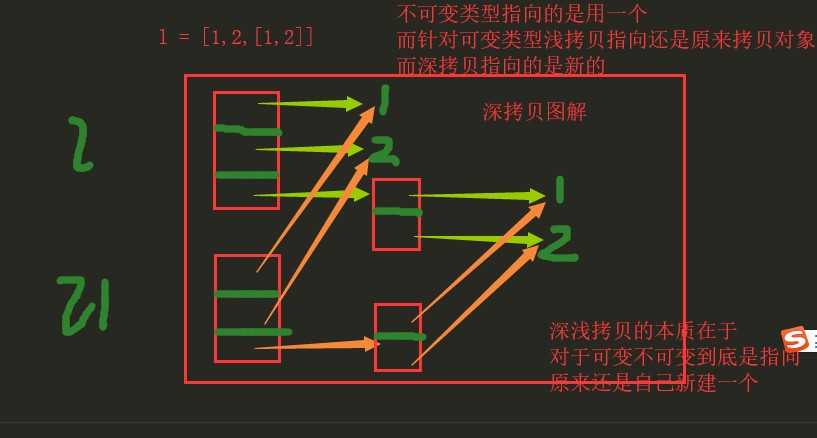
ps:深浅拷贝的本质在于对于可变不可变类型是指向原来的还是自己新建的,浅拷贝可变是原来的,深拷贝可变是新建的.不可变都是指向原来的
包/logging模块/hashlib模块/openpyxl模块/深浅拷贝
标签:encode mamicode 模块 onclick Matter eve append 文件中 stream
原文地址:https://www.cnblogs.com/z929chongzi/p/11215362.html
