标签:过程 logs control 作图 errors 回避 fir 增加 possible
在数据集不是很大的时候,开发人员可以使用python、R、MATLAB等语言在单机上处理数据集。但是在大数据时代,数据集少说都是TB、PB级别,此时便需要分布式地处理。相较于上述语言,Scala有着现成的框架即Spark能分布式地处理问题,Scala中有着丰富的Spark API,开发时只需要进行函数的编写就能轻松解决各种需求。虽然其他语言也有Spark的API,比如python的pySpark,但是逊色于Spark对Scala的支持,毕竟Spark是用Scala开发出来的。
Spark和Hadoop是Apache下的两个不同开源项目,但是有着很强的关联性。简单理解,Spark是一个能在Hadoop生态圈中使用的计算框架,Hadoop本身也有计算框架MapReduce。Spark对比Hadoop中的MapReduce有以下优势:
Spark对于数据的实时处理被人津津乐道,那么这个分布式计算框架为什么能如此优秀?
对于一个分布式计算框架,有两个问题始终难以回避:
在实际开发中,Latency是难以规避的。虽然Spark是很优秀的框架,但是如何编写出更好的代码尽量降低Latency也是开发人员的工作。
一些延迟时间:
 ?
?
在继承Hadoop对于节点崩溃的容错性的同时,Spark在处理时效上有了巨大突破。原因在于
如果计算不涉及与其他节点进行数据交换,Spark可以在内存中一次性完成这些操作,也就是中间结果无须落盘(MR则需要存到HDFS先),减少了磁盘IO的操作。
在scala-REPL中敲出下列代码可以查看Spark根目录中的LICENSE有几行,并且可以打印其中有几行包含“BSD”。
// sc是Spark Context类
scala> val licLines = sc.textFile("/Users/shayue/env/spark/spark-2.4.2-bin-hadoop2.7/LICENSE")
licLines: org.apache.spark.rdd.RDD[String] = /Users/shayue/env/spark/spark-2.4.2-bin-hadoop2.7/LICENSE MapPartitionsRDD[1] at textFile at <console>:24
scala> val lineCnt = licLines.count
[Stage 0:>
lineCnt: Long = 518
scala> val bsdLines = licLines.filter(line => line.contains("BSD"))
bsdLines: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at filter at <console>:25
scala> bsdLines.count
res1: Long = 3
scala> bsdLines.foreach(bsdLine => println(bsdLine))
BSD 2-Clause
BSD 3-Clause
is distributed under the 3-Clause BSD license.
// 简化写法
scala> bsdLines.foreach(println)
BSD 2-Clause
BSD 3-Clause
is distributed under the 3-Clause BSD license.这里代码中用到的filter和contains在scala的一些collection中也有。不过,licLines和bsdLines并不是scala的collection结构。它们时分布式的collection结构,在Spark中被称为RDDs。
RDD的特性如下:
RDDs能执行很多数据转化操作,但结束后总是产生一个新的RDD实例。一旦创建,RDD永远不会改变,这也是上面提到的Immutable特性。因为Mutable会增加框架的复杂性,除此之外,immutable collections使得Spark更具有容错性。
一个RDD实例是分布在各台机器上的总和,但是Spark仅仅暴露一个接口给用户,使得用户感觉就像在单机上操作。RDDs使得将一个任务部署到多个机器上执行变得简单了。
其他分布式计算框架通过将数据复制到多台机器来保持容错,一旦节点出现故障就可以从正常的节点复制恢复。RDD的机制不同的,它们会记录如何在某个工作节点上生成一些数据的方式,称为RDD运算图(RDD lineage),如果哪个工作节点发生故障,则只需根据记录重新生成数据即可。
下面以上述代码为例:
filter方法,生成新的bsdLines RDDRDD运算图(RDD lineage)。它记录了如何从头到尾创建bsdLines RDD。也就是说,即使某个节点当掉,可以根据RDD lineage重新生成必要的数据。分为两种方式:
filter,map,可以发现transformations操作一般会通过原RDD进行更改,进而产生新的RDD实例count,foreach,进行action操作主要是希望得到一些关于RDD实例性质的结果。值得注意的是:
Spark的Transformations操作是Lazily的,即仅在执行某些Actions操作以输出一些想要的结果时,Transformations操作才会进行。
在RDD上触发action操作后,Spark会检查RDD lineage,并使用该信息构建需要执行的graph of operations(操作图)以计算操作。它告诉Spark需要执行哪些transformations,以及将以何种顺序执行。
“操作图”可以理解为在一些RDDs上接了许多带箭头的线,每条线代表一个transformation,只有最后点击Actions时,这些线上才会有数据流动。
// sc.parallelize是一个创建RDD的方式,用本地的scala collect创建。makeRDD也可;(10 to 50 by 10)是生成Scala Range类型写法
// scala> List(10 to 50 by 10)
// res6: List[scala.collection.immutable.Range] = List(Range 10 to 50 by 10)
scala> val numbers = sc.parallelize(10 to 50 by 10)
numbers: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[3] at parallelize at <console>:24
scala> numbers.foreach(println)
20
30
40
50
10
// map操作,计算平方
scala> val numberSquared = numbers.map(num => num * num)
numberSquared: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[4] at map at <console>:25
scala> numberSquared.foreach(println)
100
1600
400
900
2500
// 对于平方数,转成string,再反转
scala> val reversed = numberSquared.map(num => num.toString.reverse)
reversed: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[5] at map at <console>:25
scala> reversed.foreach(println)
001
004
009
0061
0052
// 上述方式的简写
scala> val alsoReversed = numberSquared.map(_.toString.reverse)
alsoReversed: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[6] at map at <console>:25def flatMap[U](f: (T) => TraversableOnce[U]): RDD[U]代码:
scala> val lines = sc.textFile("/Users/shayue/client-ids.log")
lines: org.apache.spark.rdd.RDD[String] = /Users/shayue/client-ids.log MapPartitionsRDD[1] at textFile at <console>:24
scala> val idsStr = lines.flatMap(_.split(","))
idsStr: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at flatMap at <console>:25
scala> idsStr.collect
res0: Array[String] = Array(15, 16, 20, 20, 77, 80, 94, 94, 98, 16, 31, 31, 15, 20)
scala> idsStr.first
res2: String = 15
scala> val idsInt = idsStr.map(_.toInt)
idsInt: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[3] at map at <console>:25
// idsInt.collect是Array[Int]
scala> idsInt.collect
res4: Array[Int] = Array(15, 16, 20, 20, 77, 80, 94, 94, 98, 16, 31, 31, 15, 20)
scala> idsInt.distinct
res5: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[6] at distinct at <console>:26
// res5指代idsInt.distinct生成的RDD实例
scala> res5
res6: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[6] at distinct at <console>:26
// 仅包含不同元素
scala> res5.collect
res8: Array[Int] = Array(16, 80, 98, 20, 94, 15, 77, 31)
// 由Array[String]到String,并且加上特定格式“;”
scala> idsStr.collect.mkString(";")
res9: String = 15;16;20;20;77;80;94;94;98;16;31;31;15;20def sample(withReplacement: Boolean, fraction: Double, seed: Long = Utils.random.nextLong): RDD[T]
用于对一个RDD实例中的元素取样,Boolean是True的话就是有放回的取样;False就是无放回
mean\sum\histogram\variance\stdv
PPT 总结:赖得手打了
常用Transformations:
 ?
?
常用Actions:
 ?
?
其他:
 ?
?
先来回顾一下Spark的特性:
数据处理中做的最多的事情是迭代:
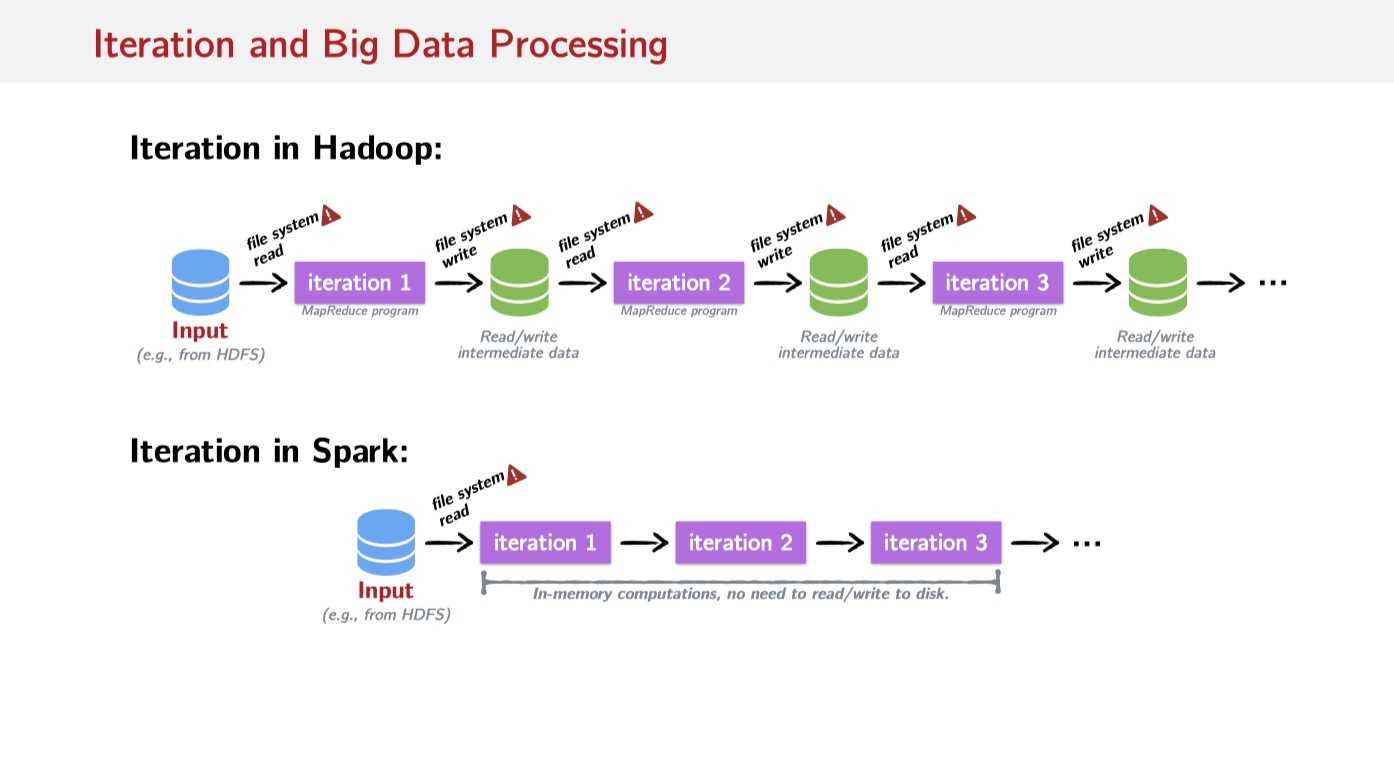 ?
?
从上图看来,不像Hadoop需要重复地将数据写回File System中,Spark有能力直接在内存中读取数据进行迭代。
Spark allows us to control what is cached in memory. What we do is just simply call persist() or cache() on RDDs.
举例:
 ?
?
倘若不在第二行生成logsWithErrors时加上.persist()。由于filter()和contains()是Lazy的,在第4行执行Actions操作count时,需要重新执行.filter(_.contains("ERROR"))这个操作;但是加上.persist()就可以不用重复计算。
当然,既然是将数据保存在内存中,那显然很吃内存的容量。Spark有以下如下几种方式,配置保存在内存中的数据格式。
 ?
?
 ?
?
取完10个元素之后,Spark便停止工作了;又或者:
 ?
?
collction中要先走完map再走filter再走count,RDDs中一次遍历时这些操作同时进行。
标签:过程 logs control 作图 errors 回避 fir 增加 possible
原文地址:https://www.cnblogs.com/shayue/p/week1.html