标签:ict 用户 dict 学习过程 类别 baidu not 疑惑 red
调包一时爽,复现马上躺。
Co-Clustering
注意右上角的:“Edit on GitHub”,一开始疯狂吐槽没有源码,复现得非常难受,今天刚做完GM05中Algotirhm1部分,再次点开无意中发现了源码的GitHub,准备复现完成后去看看不同所在。预期到复现效果一定是极差的,并不是自我质疑,而是所用设备问题,在行列确定聚类数时,没有能力枚举行列大小运用肘部法则确定k值,故随机了几组范围,得到了这些范围内最小的SSE误差聚类数作为行列的类数。本博客分为两部分,第一部分主要阐述复现的学习过程,第二部分则是对源码的学习。大概率是看不懂了Co-Clustering(下称该算法)
Prediction Formula:
$ \widehat{A_{ij}} = A^{COC}_{gh} + (A^R_i - A^{RC}_g) + (A^C_j - A^{CC}_h) $
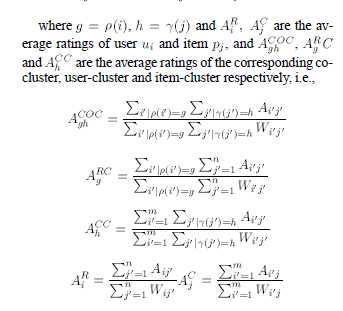
上面就是Co-Clustering的预测公式,下面来说说复现过程的问题和手拙的地方。
先放核心算法(Static Training):
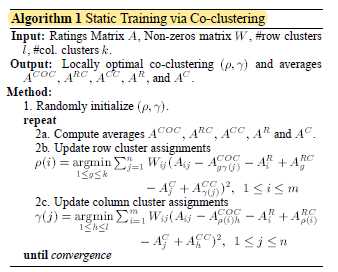
复现描述:
首先,算法描述中的Input,提到了权重数组W($W_ij = (A_ij==0)$ ),这个可以很方便地求出,但是还涉及到了行列的类数,这显然没有提供,所以是需要聚类的。在聚类的时候,就想到直接运用KMeans,枚举K,用肘部法则来确定k值,但是其实这样非常的花费时间,所以就随机了几个区间取最好的结果来(最后的SSE也有大几万,可以说还是很差劲的)。
其次,在Method中,一开始随机的协同中心,发现其实时一系列的协同中心,并不是很理解,就先按照自己的理解把每个用户和每个电影的平均得分,作为初始类中心,然后准备开始迭代,发现jupyter的*一直没有变成数字,就大概猜到迭代不动了,至于为什么,原因也不是很清楚。
最后,第一次迭代仍然没有完成,等于没有复现成功。而看了一下算法描述的第二部分是Prediction,其实就是开头写下的公式,并且结合需要预测的用户-电影组是不是未在数据集中出现过的(00,01,10,11共四种情况),来做对应调整。还有最后一部分是增量训练,就是面对新加入的数据,并不是预测就结束了,是需要变成数据集的数据来不断学习的,这部分去看了算法和源码学习了一下。
源码学习:
很惊喜的是,竟然都看得懂。很遗憾的是,这不难的代码竟然没有复现出来,不得不说码力还是太僵了。代码很巧妙地实现了论文所说的第一部分算法(第二部分仅为公式套用),真的还需要多学习,论文摆在眼前竟然还只复现了一半不到,想不清楚怎么去迭代的。但是,对于第一部分还有个疑惑,就是源码假设了用户和电影的类别数都是3,然后去迭代,并没有我去枚举k找到最佳类数的操作,在这里不是很理解。虽然最后肯定会收敛,但是这难道不会影响预测的准确度么?
其次,还有一个疑虑,就是代码并没有第三部分增量学习的表达(Incremental Training),怎么也要有个update函数吧而论文所说该算法的亮点正是对于新数据,并且论文假设其为局部增量的时候(局部增量,个人理解是小规模的新加入数据,其规模相对于原来的数据来说较小,增量特征学习),该算法迭代速度与准确度优于SVD,NMF。于是,我大胆猜测所谓的增量学习,不过就是重新计算迭代预测,因为CoClustering的迭代速度很快本地跑得好慢,所以所谓的局部增量变化,其实就是直接被当成了新增加的用户和电影(如若两者均为新的)加入矩阵来进行预测,而论文的描述也是如同预测一般去分类讨论,紧接着更新对应的中心、均值,说明和我的猜测相去无几本来以为会有全新的操作。至于第四部分(Parallel Co-Clustering),看懂了语言描述中将行列分开计算来加快速度的思路,但在算法描述的时候,又说是拿一部分子矩阵来迭代(就是将算法第一部分描述中的更新整个矩阵,变成更新所选取的子矩阵),可能是对于并行计算并没有了解,所以带了这些疑惑,之后了解并行计算再回头看看。
PS:第一次看这种纯算法描述的英文论文有点难懂,如果没调包估计不会遇到这个算法,也不会为了能够有底气地展示去如此认真地看论文,认真学掉还是挺有趣的,可以说让聚类在我心里提了一个档次,疯狂入坑。
标签:ict 用户 dict 学习过程 类别 baidu not 疑惑 red
原文地址:https://www.cnblogs.com/FormerAutumn/p/11219158.html