标签:使用 内存 构造 logs 编译器 线程 mamicode volatil 排序
参考博客:https://www.cnblogs.com/xdecode/p/8948277.html
内存模型:每一个线程有一个工作内存和主存独立,工作内存存放主存中变量的值的拷贝
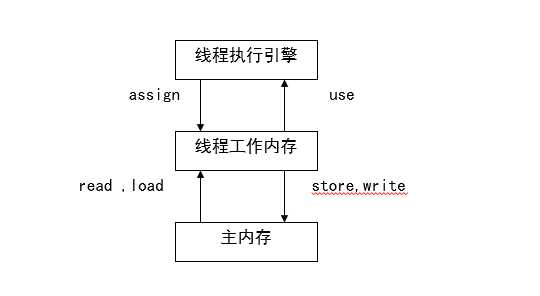
当数据从主内存复制到工作存储时,必须出现两个动作:第一,由主内存执行的读(read)操作;第二,由工作内存执行的相应的load操作;当数据从工作内存拷贝到主内存时,也出现两个操作:第一个,由工作内存执行的存储(store)操作;
第二,由主内存执行的相应的写(write)操作每一个操作都是原子的,即执行期间不会被中断。对于普通变量,一个线程中更新的值,不能马上反应在其他变量中如果需要在其他线程中立即可见,需要使用 volatile 关键字
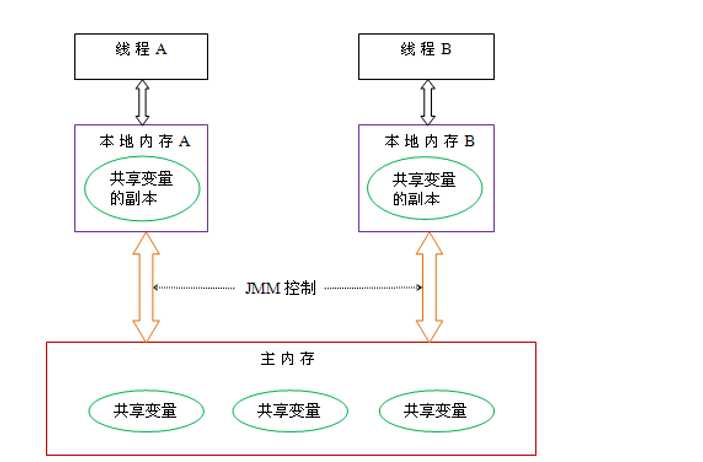
可见性:一个线程修改了变量,其他线程可以立即知道,在本线程内,操作都是有序的在线程外观察,操作都是无序的。(指令重排 或 主内存同步延时)
保证可见性的方法:volatile,synchronized (unlock之前,写变量值回主存),final(一旦初始化完成,其他线程就可见),LOCK锁等
指令重排:指令重排是指在程序执行过程中, 为了性能考虑, 编译器和CPU可能会对指令重新排序.。保证线程内串行语义,破坏线程间的有序性,编译器不考虑多线程间的语义
写后读 a = 1;b = a; 写一个变量之后,再读这个位置。
写后写 a = 1;a = 2; 写一个变量之后,再写这个变量。
读后写 a = b;b = 1; 读一个变量之后,再写这个变量。
以上语句不可重排
可重排: a=1;b=2;
指令重排遵循的基本原则(Happen-Before先行发生规则):
程序顺序原则:一个线程内保证语义的串行性
volatile规则:volatile变量的写,先发生于读
锁规则:解锁(unlock)必然发生在随后的加锁(lock)前
传递性:A先于B,B先于C 那么A必然先于C
线程的start方法先于它的每一个动作
线程的所有操作先于线程的终结(Thread.join())
线程的中断(interrupt())先于被中断线程的代码
对象的构造函数执行结束先于finalize()方法
标签:使用 内存 构造 logs 编译器 线程 mamicode volatil 排序
原文地址:https://www.cnblogs.com/cheng21553516/p/11220296.html