标签:美的 所有权 适用于 lin 训练 header 结构 最优 影响
???????范数在深度学习中的应用是作为损失函数正则化选项,从而减少模型的过拟合情况。在继续讲解正则化之前,我们先介绍欠拟合、过拟合的概念。
???????假设坐标系内有一系列点,都是带有噪声的二次曲线上的点。现在我们不知道这些数据是二次曲线上的点,但希望通过一个函数来拟合出一条线,使得这条线能尽可能的贴近这些点,这条线也就是我们得到的模型。如图1所示第一列到第三列依次为欠拟合,正常拟合以及过拟合。
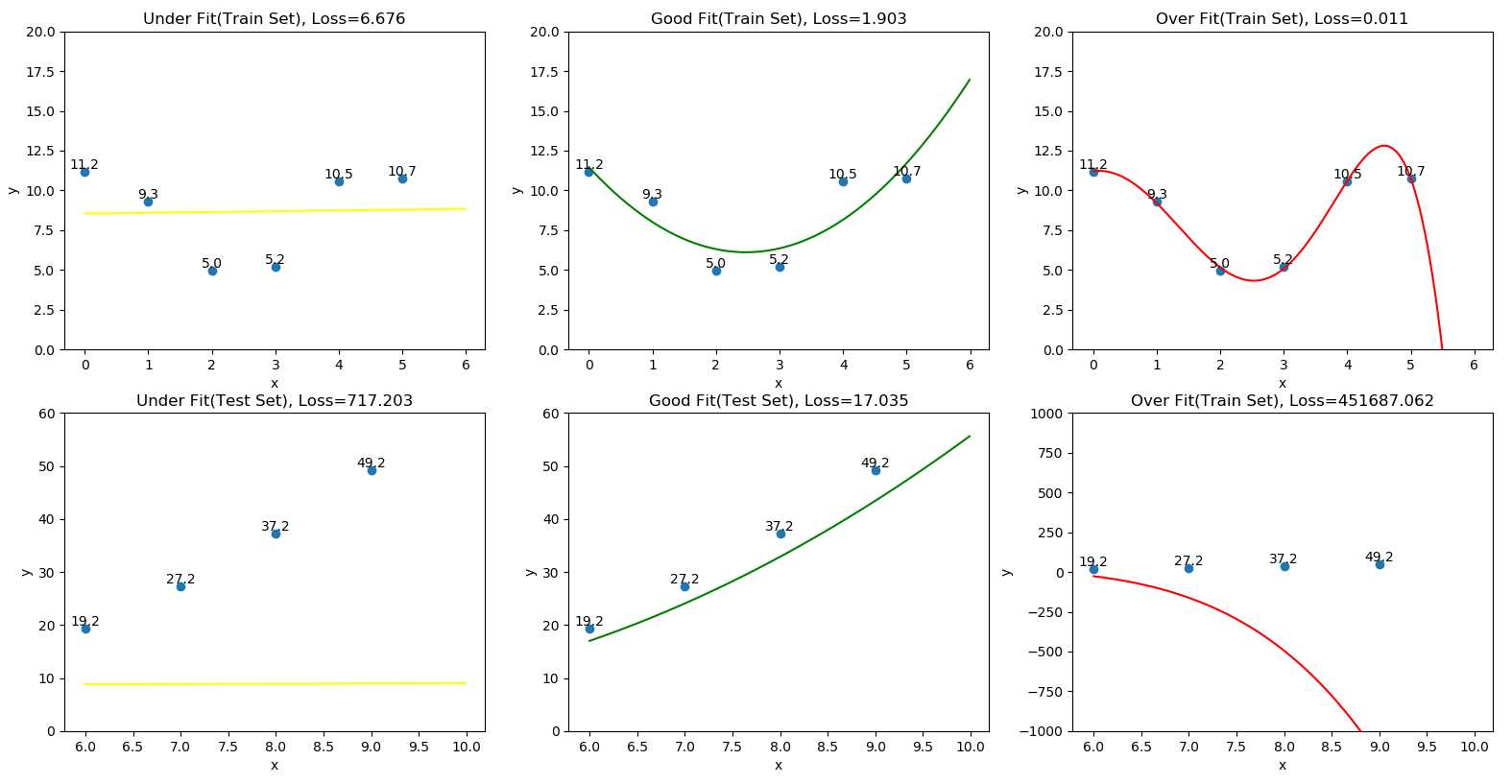
| 情形 | 表现 | 训练集正确率 | 测试集正确率 |
|---|---|---|---|
| 欠拟合 | 用\(y = ax + b\) 拟合有噪二次函数数据 | 差(图1中1行1列) | 差(图1中2行1列) |
| 正常拟合 | 用\(y = ax^{2} + bx + c\) 拟合有噪二次函数数据 | 较好(图1中1行2列) | 较好(图1中2行2列) |
| 过拟合 | 用\(y = ax^{5} + bx^{4} + cx^{3} +dx^{2} + ex +f\)拟合有噪二次函数数据 | 非常好(图1中1行3列) | 非常差(图1中2行3列) |
???????如图1所示分别为欠拟合、正常拟合和过拟合,下面将分别描述这些情形:
???????欠拟合,如同用待定系数的一次函数去拟合一个由二次函数产生的带噪声数据,表示模型过于简单,拟合出来模型难以反映样本分布情况(在训练集上损失值为6.676),模型在训练集上准确率也不高(在测试集上损失值比训练集还高,为717.203)。
???????正常拟合,如同用待定系数的二次函数的去拟合一个由二次函数产生的带噪声数据,拟合出来模型基本能反映样本的分布情况,且不会受到样本的误差的影响(在训练集上损失值为比较低,为1.903)。模型在训练集和验证集上准确率都令人满意(在测试集上损失值为17.03)。
???????过拟合,如同用待定系数的五次函数的去拟合一个由二次函数产生的带噪声数据,得到的拟合函数能非常完美的模拟样本的分布(在训练集上损失值非常低,为0.011),但也把样本误差等因素都拟合了进去,导致模型的泛化能力大大下降。模型在训练集上准确率非常高,但在验证集上准确率往往很差 (在训练集上损失值非常大,为451687.062)。
???????通常在过拟合情况下,训练过程中模型复杂度增加,模型在训练集上的错误率逐渐减小,但是在验证集上的错误率却反而逐渐增大——因为训练出来的模型过拟合了训练集(直观解释就是模型增加了只适用于训练集的参数,如图1所示用高次函数拟合一个二次函数的数据集)。
???????我们不希望在深度学习模型训练中出现过拟合情况,我们要用一些手段防止过拟合。即让模型不出现用高次函数去拟合二次函数产生的带有噪声的数据的情况,高次函数拟合效果虽好但也拟合了数据噪声。我们应让模型尽可能表现为用待定系数的二次函数去拟合二次函数产生的带有噪声的数据。如果要让模型不出现的过拟合情况,需要让模型权值向量W中元素个数尽可能少,对于拟合二次函数的问题来说,模型求解得到的权值向量中元素个数应该是2,而不是其他。一个向量的元素个数正好是向量的L0范数,因此让模型权值向量W中项的个数最小化其实等于优化min||w||0,这样过拟合解决方案和范数就建立了联系。对于深度学习原问题优化的目标从单目标函数优化
\[\min \;Loss\left( {{\bf{\omega }},{\bf{x}}} \right)\]
???????变成了双目标函数优化任务
\[\left\{ \begin{array}{l} \min \;Loss\left( {{\bf{\omega }},{\bf{x}}} \right) \\ \min \;{\left\| {\bf{\omega }} \right\|_0} \\ \end{array} \right.\]
???????第一个优化任务中目标函数称为经验风险,第二个优化任务中的目标函数叫做正则化项。在深度学习中一般会将这个双目标优化任务合并成单目标优化任务,即
\[\min \;Loss\left( {{\bf{\omega }},{\bf{x}}} \right) + \lambda {\left\| {\bf{\omega }} \right\|_0}\]
???????即让经验风险和正则化项之和最小,其中λ是正则化项系数。这样正则化项过大,经验风险再小也不起作用;同样经验风险过大,正则化项再小也不起作用。通常将Loss(w,x) +λ||w||0叫做结构风险。
???????在数学最优化问题中,如果目标函数中有L0范数,那么这个最优化问题难以求解,因为求解L0范数是一个NP完全问题。既然L0范数难求,那么退而求其次,可以将目标函数中的L0范数改成在数学上容易进行优化的L1范数或L2范数。即模型的目标函数改为
\[\min \;Loss\left( {{\bf{\omega }},{\bf{x}}} \right) + \lambda {\left\| {\bf{\omega }} \right\|_1}\]
???????或
\[\min \;Loss\left( {{\bf{\omega }},{\bf{x}}} \right) + \lambda {\left\| {\bf{\omega }} \right\|_2}\]
???????因此深度学习中正则化项用的较多的是L1范数和L2范数。在权值更新的梯度下降算法中,L2范数比L1范数方便求导,所以下文先介绍L2范数的正则化。
???????范数进行正则化一般有两种形式:L2正则化和L1正则化。其中L2正则化比L1正则化更常见,L2正则化是在代价函数后面再加上一个L2范数正则化项,通常形式不是简单的
\[Loss\left( {{\bf{\omega }},{\bf{x}}} \right) + \lambda {\left\| {\bf{\omega }} \right\|_2}\]
???????而是
\[\begin{array}{l} L{\rm{os}}{{\rm{s}}_2}\left( {{\bf{\omega }},{\bf{x}}} \right) = Los{s_0}\left( {{\bf{\omega }},{\bf{x}}} \right) + \frac{\lambda }{{2n}}\left\| {\bf{\omega }} \right\|_2^2 \\ \quad \quad \;\;\quad \quad \; = Los{s_0}\left( {{\bf{\omega }},{\bf{x}}} \right) + \frac{\lambda }{{2n}}{{\bf{\omega }}^T}{\bf{\omega }} \\ \end{array}\]
???????Loss0代表原始的代价函数,后一项就是L2正则化项,||w||2表示参数w的L2范数,λ就是正则化项系数,n是训练集中样本个数,权衡正则化项与Loss0项的比重。另外还有一个系数1/2,1/2经常会看到,主要是为求导结果方便计算,后一项求导会产生一个2,与1/2相乘刚好凑整。L2正则化项是怎么避免overfitting的呢?我们推导一下看看,先求导:
\[ \frac{{\partial L{\rm{os}}{{\rm{s}}_2}\left( {{\bf{\omega }},{\bf{x}}} \right)}}{{\partial {\bf{\omega }}}} = \frac{{\partial L{\rm{os}}{{\rm{s}}_0}\left( {{\bf{\omega }},{\bf{x}}} \right)}}{{\partial {\bf{\omega }}}} + \frac{\lambda }{n}{\bf{\omega }} \]
???????η为梯队下降中的学习率,W权重的更新表达式为:
\[\begin{array}{l} {\bf{\omega }} = {\bf{\omega }} - \eta \frac{{\partial L{\rm{os}}{{\rm{s}}_2}\left( {{\bf{\omega }},{\bf{x}}} \right)}}{{\partial {\bf{\omega }}}} \\ \quad = {\bf{\omega }} - \eta \left( {\frac{{\partial L{\rm{os}}{{\rm{s}}_0}\left( {{\bf{\omega }},{\bf{x}}} \right)}}{{\partial {\bf{\omega }}}} + \frac{\lambda }{n}{\bf{\omega }}} \right) \\ \quad = \left( {1 - \frac{{\eta \lambda }}{n}} \right){\bf{\omega }} - \eta \frac{{\partial L{\rm{os}}{{\rm{s}}_0}\left( {{\bf{\omega }},{\bf{x}}} \right)}}{{\partial {\bf{\omega }}}} \\ \end{array}\]
???????在不使用L2正则化时,求导结果中w前系数为1,现在w前面系数为 1?ηλ/n ,因为η、λ、n都为正,所以 1?ηλ/n小于1,它的效果是减小w,这也就是权重衰减(weight decay)的由来。当然考虑到后面的导数项,w最终的值可能增大也可能减小。
???????到目前为止,我们只是解释了L2正则化项存在可以让w“变小”的效果,但是还没解释为什么w“变小”可以防止过拟合?一个“显而易见”的解释就是:更小的权值w,从某种意义上说,表示网络的复杂度更低,对数据的拟合刚刚好(奥卡姆剃刀原理),而在实际应用中,也验证了这一点,L2正则化的效果往往好于未经正则化的效果。
???????L2正则化能一定程度处理过拟合情况。过拟合的时候,拟合函数的系数往往非常大,过拟合是拟合函数需要顾忌每一个点,最终形成的拟合函数波动很大。在某些很小的区间里,函数值的变化很剧烈。这就意味着函数在某些小区间里的导数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。而正则化是通过约束参数的范数使其不要太大,所以可以在一定程度上减少过拟合情况。
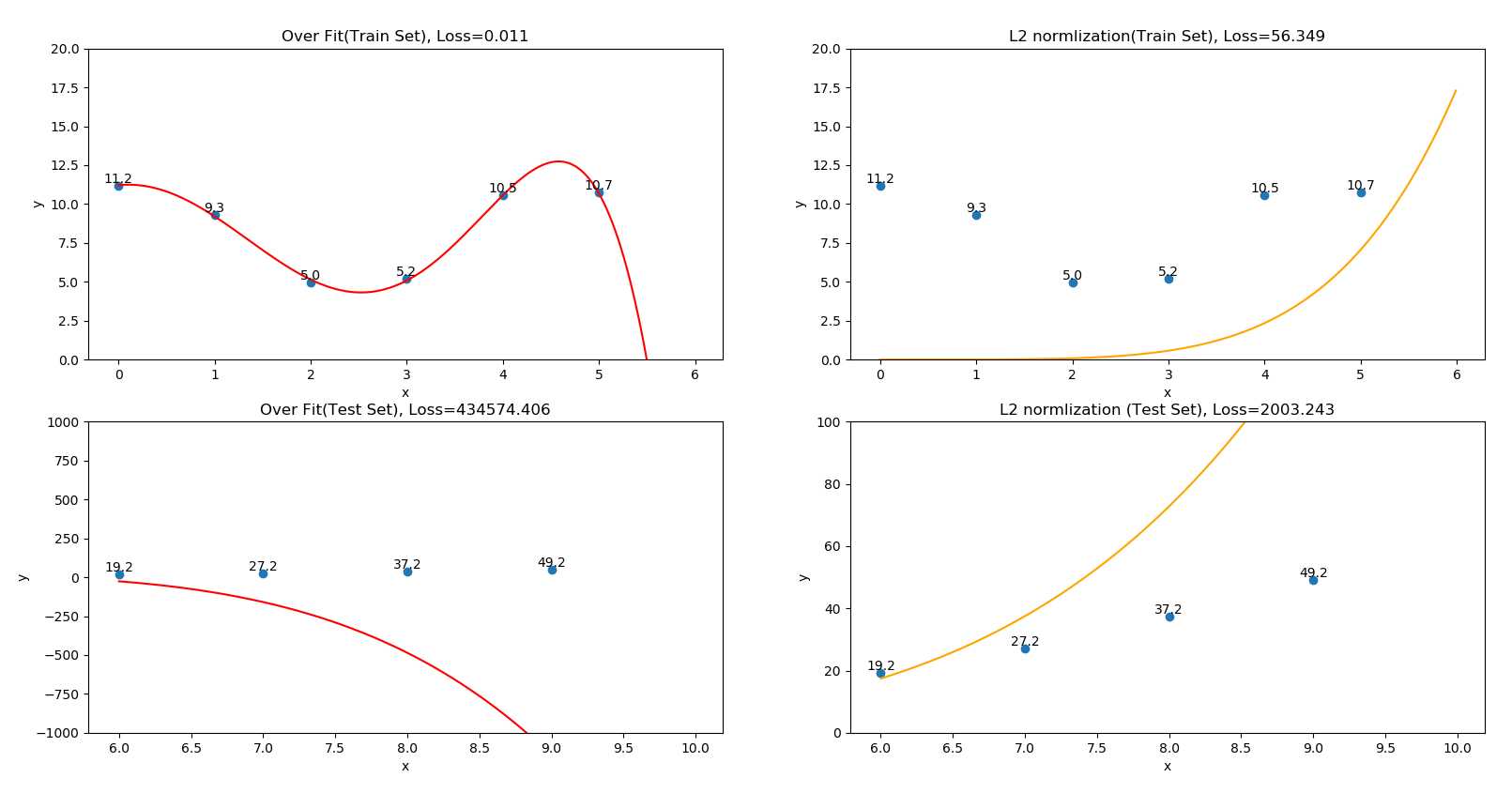
| 情形 | 表现 | 训练集正确率 | 测试集正确率 |
|---|---|---|---|
| 过拟合 | 用\(y = ax^{5} + bx^{4} + cx^{3} +dx^{2} + ex +f\)拟合有噪二次函数数据 | 非常好(图2中1行1列) | 非常差(图2中2行1列) |
| L2正则化优化 | 用\(y = ax^{5} + bx^{4} + cx^{3} +dx^{2} + ex +f\)加L2范数正则项拟合有噪二次函数数据 | 较好(图2中1行2列) | 较好(图2中2行2列) |
???????如图2所示分别为过拟合情形和经L2正则优化的情形,虽然经过L2正则优化后的模型在训练集上准确率不及没有经过L2正则优化模型,但L2正则优化后的模型有两个优点:
???????(1) L2正则优化后的模型表现出了二次函数特征,而不是过拟合情况下高次函数的特征
???????(2) L2正则优化后的模型在测试集上的准确率比没有经过L2正则优化的模型好太多,
???????以上两点都可以证明L2正则化对过拟合问题有本质上的改善。
???????同L2正则化类似,在原始的损失函数后面加上一个L1正则化项,即所有权重w的绝对值的和,乘以λ/n
\[ L{\rm{os}}{{\rm{s}}_1}\left( {{\bf{\omega }},{\bf{x}}} \right) = Los{s_0}\left( {{\bf{\omega }},{\bf{x}}} \right) + \frac{\lambda }{n}{\left\| {\bf{\omega }} \right\|_1} \]
???????先求导:
\[ \frac{{\partial L{\rm{os}}{{\rm{s}}_1}\left( {{\bf{\omega }},{\bf{x}}} \right)}}{{\partial {\bf{\omega }}}} = \frac{{\partial L{\rm{os}}{{\rm{s}}_0}\left( {{\bf{\omega }},{\bf{x}}} \right)}}{{\partial {\bf{\omega }}}} + \frac{\lambda }{n}{\mathop{\rm sgn}} \left( {\bf{\omega }} \right) \]
???????上式中sgn(w)表示w的符号。那么权重w的更新规则为:
\[\begin{array}{l} {\bf{\omega }} = {\bf{\omega }} - \eta \frac{{\partial L{\rm{os}}{{\rm{s}}_1}\left( {{\bf{\omega }},{\bf{x}}} \right)}}{{\partial {\bf{\omega }}}} \\ \quad = {\bf{\omega }} - \eta \left( {\frac{{\partial L{\rm{os}}{{\rm{s}}_0}\left( {{\bf{\omega }},{\bf{x}}} \right)}}{{\partial {\bf{\omega }}}} + \frac{\lambda }{n}{\mathop{\rm sgn}} \left( {\bf{\omega }} \right)} \right) \\ \quad = {\bf{\omega }} - \frac{{\eta \lambda }}{n}{\mathop{\rm sgn}} \left( {\bf{\omega }} \right) - \eta \frac{{\partial L{\rm{os}}{{\rm{s}}_0}\left( {{\bf{\omega }},{\bf{x}}} \right)}}{{\partial {\bf{\omega }}}} \\ \end{array}\]
???????比原始的更新规则多出了ηλ sgn(w)/n这一项。当w为正时,更新后的w变小。当w为负时,更新后的w变大。因此它的效果就是让w逐渐趋向于0,使模型中的权重尽可能为0,也就相当于减小了模型复杂度,防止过拟合。另外,上面没有提到一个问题,当w为0时怎么办?当w等于0时,|W|是不可导的,所以我们只能按照原始的未经正则化的方法去更新w,这就相当于去掉ηλsgn(w)/n这一项,所以我们可以规定sgn(0)=0,这样就把w=0的情况也统一进来了。
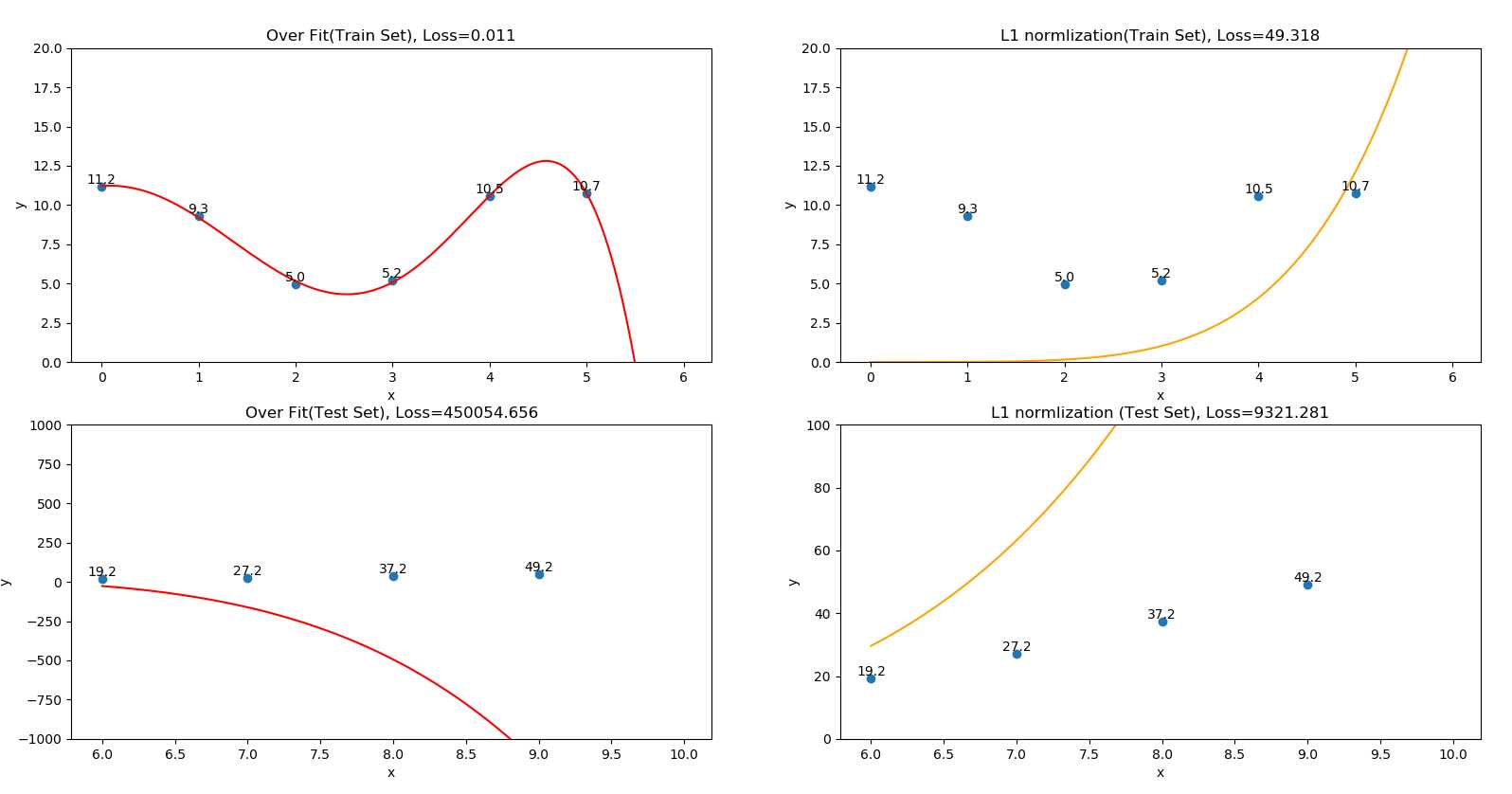
| 情形 | 表现 | 训练集正确率 | 测试集正确率 |
|---|---|---|---|
| 过拟合 | 用\(y = ax^{5} + bx^{4} + cx^{3} +dx^{2} + ex +f\)拟合有噪二次函数数据 | 非常好(图2中1行1列) | 非常差(图2中2行1列) |
| L1正则化优化 | 用\(y = ax^{5} + bx^{4} + cx^{3} +dx^{2} + ex +f\)加L1范数正则项拟合有噪二次函数数据 | 较好(图2中1行2列) | 较好(图2中2行2列) |
???????如图3所示分别为过拟合情形和经L1正则优化的情形,虽然经过L1正则优化后的模型在训练集上准确率不及没有经过L1正则优化模型,但L1正则优化后的模型有两个优点:
???????(1) L1正则优化后的模型表现出了二次函数特征,而不是过拟合情况下高次函数的特征
???????(2) L1正则优化后的模型在测试集上的准确率比没有经过L1正则优化的模型好太多,
???????以上两点都可以证明L1正则化对过拟合问题有本质上的改善。
标签:美的 所有权 适用于 lin 训练 header 结构 最优 影响
原文地址:https://www.cnblogs.com/Kalafinaian/p/11220761.html